 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeLong-Term Memory Networks for Question Answering
Jul 06, 2017
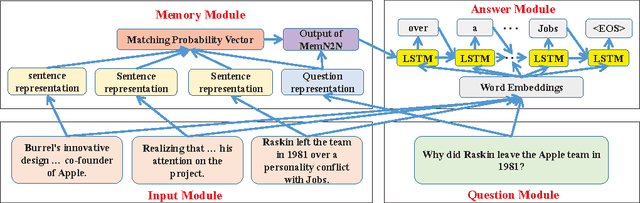

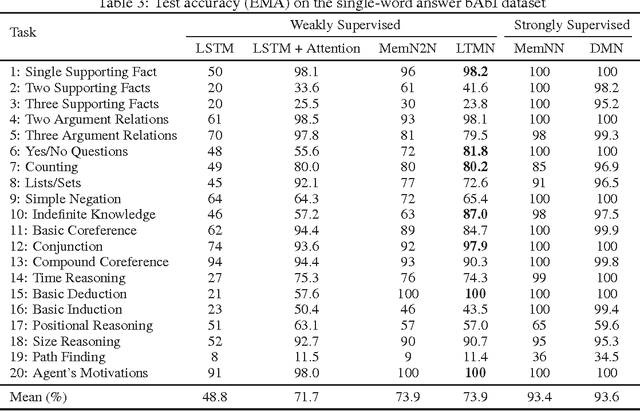
Question answering is an important and difficult task in the natural language processing domain, because many basic natural language processing tasks can be cast into a question answering task. Several deep neural network architectures have been developed recently, which employ memory and inference components to memorize and reason over text information, and generate answers to questions. However, a major drawback of many such models is that they are capable of only generating single-word answers. In addition, they require large amount of training data to generate accurate answers. In this paper, we introduce the Long-Term Memory Network (LTMN), which incorporates both an external memory module and a Long Short-Term Memory (LSTM) module to comprehend the input data and generate multi-word answers. The LTMN model can be trained end-to-end using back-propagation and requires minimal supervision. We test our model on two synthetic data sets (based on Facebook's bAbI data set) and the real-world Stanford question answering data set, and show that it can achieve state-of-the-art performance.
Deep Multimodal Representation Learning from Temporal Data
Apr 11, 2017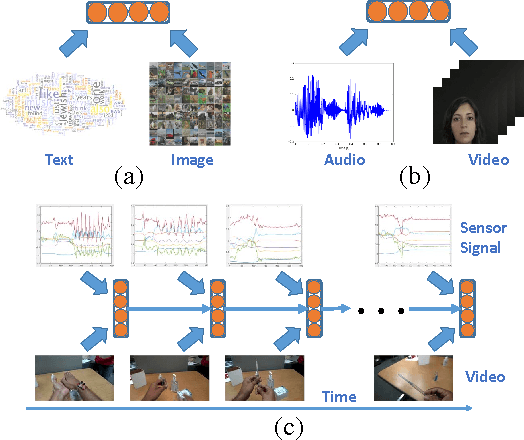
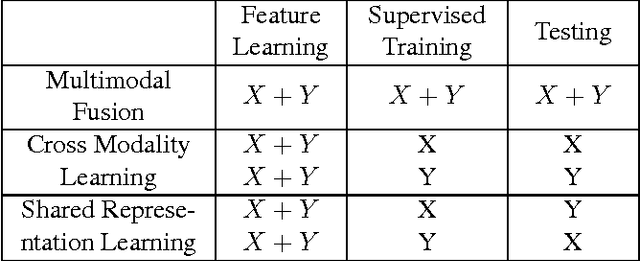
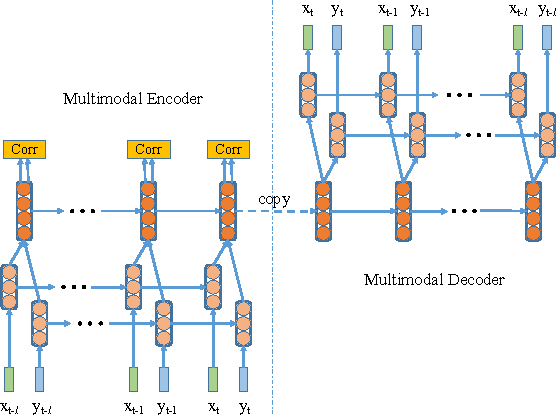

In recent years, Deep Learning has been successfully applied to multimodal learning problems, with the aim of learning useful joint representations in data fusion applications. When the available modalities consist of time series data such as video, audio and sensor signals, it becomes imperative to consider their temporal structure during the fusion process. In this paper, we propose the Correlational Recurrent Neural Network (CorrRNN), a novel temporal fusion model for fusing multiple input modalities that are inherently temporal in nature. Key features of our proposed model include: (i) simultaneous learning of the joint representation and temporal dependencies between modalities, (ii) use of multiple loss terms in the objective function, including a maximum correlation loss term to enhance learning of cross-modal information, and (iii) the use of an attention model to dynamically adjust the contribution of different input modalities to the joint representation. We validate our model via experimentation on two different tasks: video- and sensor-based activity classification, and audio-visual speech recognition. We empirically analyze the contributions of different components of the proposed CorrRNN model, and demonstrate its robustness, effectiveness and state-of-the-art performance on multiple datasets.