 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgePage-level Optimization of e-Commerce Item Recommendations
Aug 12, 2021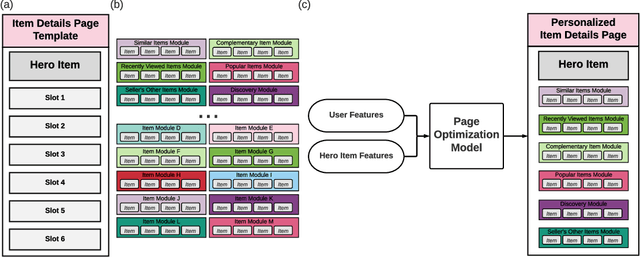

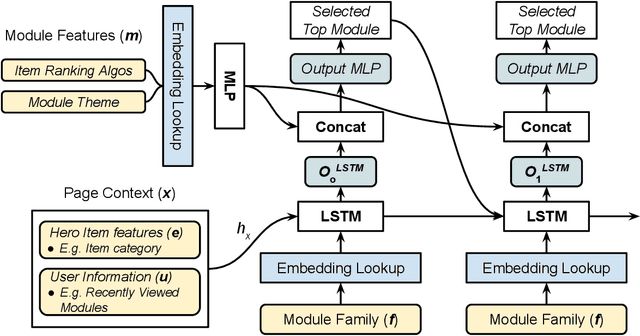

The item details page (IDP) is a web page on an e-commerce website that provides information on a specific product or item listing. Just below the details of the item on this page, the buyer can usually find recommendations for other relevant items. These are typically in the form of a series of modules or carousels, with each module containing a set of recommended items. The selection and ordering of these item recommendation modules are intended to increase discover-ability of relevant items and encourage greater user engagement, while simultaneously showcasing diversity of inventory and satisfying other business objectives. Item recommendation modules on the IDP are often curated and statically configured for all customers, ignoring opportunities for personalization. In this paper, we present a scalable end-to-end production system to optimize the personalized selection and ordering of item recommendation modules on the IDP in real-time by utilizing deep neural networks. Through extensive offline experimentation and online A/B testing, we show that our proposed system achieves significantly higher click-through and conversion rates compared to other existing methods. In our online A/B test, our framework improved click-through rate by 2.48% and purchase-through rate by 7.34% over a static configuration.
Personalized Embedding-based e-Commerce Recommendations at eBay
Feb 11, 2021

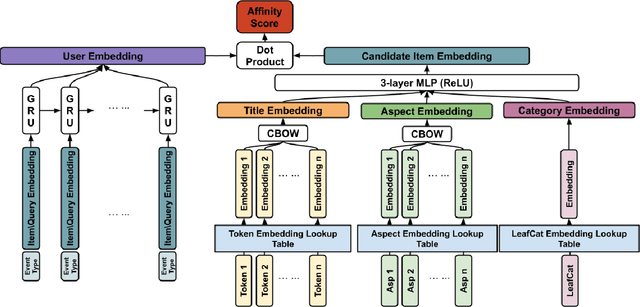

Recommender systems are an essential component of e-commerce marketplaces, helping consumers navigate massive amounts of inventory and find what they need or love. In this paper, we present an approach for generating personalized item recommendations in an e-commerce marketplace by learning to embed items and users in the same vector space. In order to alleviate the considerable cold-start problem present in large marketplaces, item and user embeddings are computed using content features and multi-modal onsite user activity respectively. Data ablation is incorporated into the offline model training process to improve the robustness of the production system. In offline evaluation using a dataset collected from eBay traffic, our approach was able to improve the Recall@k metric over the Recently-Viewed-Item (RVI) method. This approach to generating personalized recommendations has been launched to serve production traffic, and the corresponding scalable engineering architecture is also presented. Initial A/B test results show that compared to the current personalized recommendation module in production, the proposed method increases the surface rate by $\sim$6\% to generate recommendations for 90\% of listing page impressions.
Parametric Synthesis of Text on Stylized Backgrounds using PGGANs
Sep 22, 2018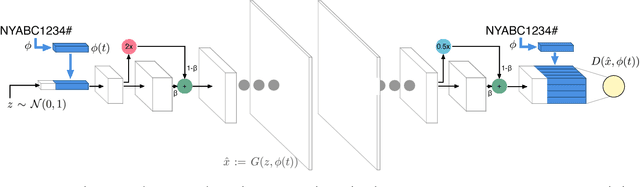


We describe a novel method of generating high-resolution real-world images of text where the style and textual content of the images are described parametrically. Our method combines text to image retrieval techniques with progressive growing of Generative Adversarial Networks (PGGANs) to achieve conditional generation of photo-realistic images that reflect specific styles, as well as artifacts seen in real-world images. We demonstrate our method in the context of automotive license plates. We assess the impact of varying the number of training images of each style on the fidelity of the generated style, and demonstrate the quality of the generated images using license plate recognition systems.
Neural Signatures for Licence Plate Re-identification
Dec 01, 2017
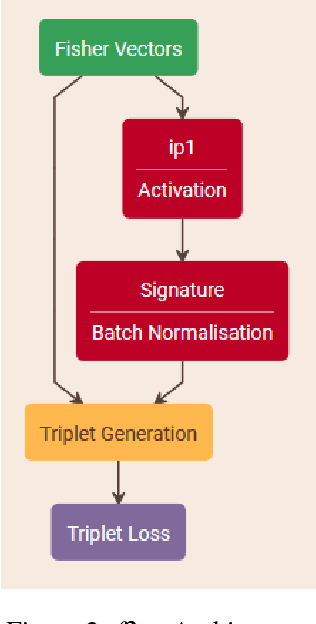

The problem of vehicle licence plate re-identification is generally considered as a one-shot image retrieval problem. The objective of this task is to learn a feature representation (called a "signature") for licence plates. Incoming licence plate images are converted to signatures and matched to a previously collected template database through a distance measure. Then, the input image is recognized as the template whose signature is "nearest" to the input signature. The template database is restricted to contain only a single signature per unique licence plate for our problem. We measure the performance of deep convolutional net-based features adapted from face recognition on this task. In addition, we also test a hybrid approach combining the Fisher vector with a neural network-based embedding called "f2nn" trained with the Triplet loss function. We find that the hybrid approach performs comparably while providing computational benefits. The signature generated by the hybrid approach also shows higher generalizability to datasets more dissimilar to the training corpus.
Deep Multimodal Representation Learning from Temporal Data
Apr 11, 2017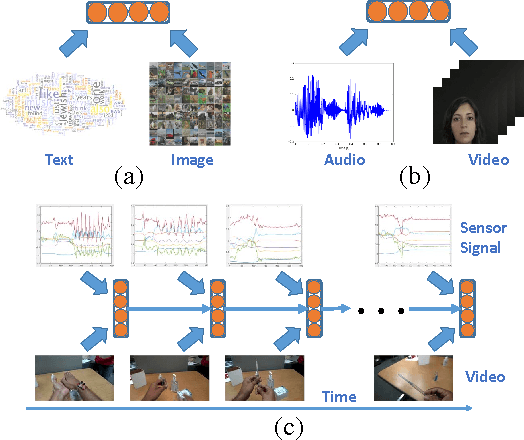
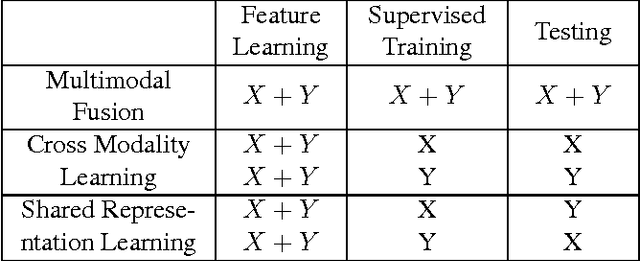
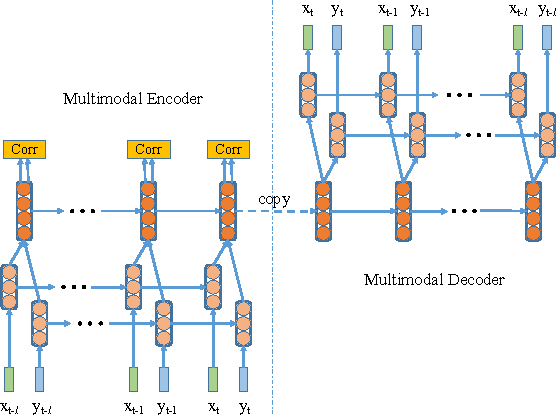

In recent years, Deep Learning has been successfully applied to multimodal learning problems, with the aim of learning useful joint representations in data fusion applications. When the available modalities consist of time series data such as video, audio and sensor signals, it becomes imperative to consider their temporal structure during the fusion process. In this paper, we propose the Correlational Recurrent Neural Network (CorrRNN), a novel temporal fusion model for fusing multiple input modalities that are inherently temporal in nature. Key features of our proposed model include: (i) simultaneous learning of the joint representation and temporal dependencies between modalities, (ii) use of multiple loss terms in the objective function, including a maximum correlation loss term to enhance learning of cross-modal information, and (iii) the use of an attention model to dynamically adjust the contribution of different input modalities to the joint representation. We validate our model via experimentation on two different tasks: video- and sensor-based activity classification, and audio-visual speech recognition. We empirically analyze the contributions of different components of the proposed CorrRNN model, and demonstrate its robustness, effectiveness and state-of-the-art performance on multiple datasets.