Get our free extension to see links to code for papers anywhere online!Free add-on: code for papers everywhere!Free add-on: See code for papers anywhere!
 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeParametric Synthesis of Text on Stylized Backgrounds using PGGANs
Paper and Code
Sep 22, 2018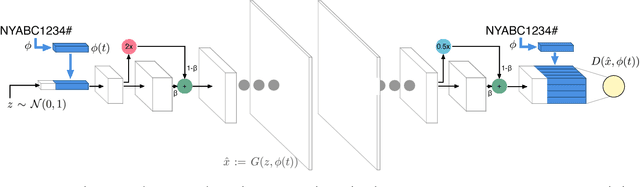

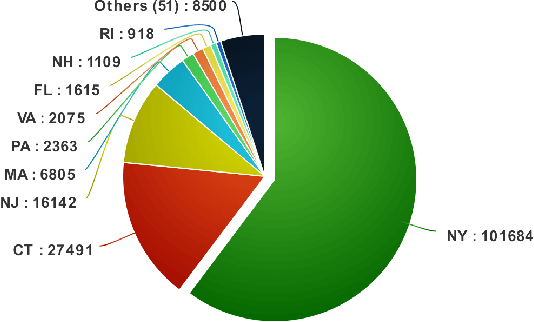

We describe a novel method of generating high-resolution real-world images of text where the style and textual content of the images are described parametrically. Our method combines text to image retrieval techniques with progressive growing of Generative Adversarial Networks (PGGANs) to achieve conditional generation of photo-realistic images that reflect specific styles, as well as artifacts seen in real-world images. We demonstrate our method in the context of automotive license plates. We assess the impact of varying the number of training images of each style on the fidelity of the generated style, and demonstrate the quality of the generated images using license plate recognition systems.
View paper on