 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeIIRSim Studio: A Dashboard for User Simulation
Apr 25, 2026User simulation is a valuable methodology for evaluation in Information Retrieval (IR), enabling low-cost experimentation and counterfactual analysis. However, existing simulation frameworks are primarily code-centric libraries that require substantial setup effort, which limits adoption and hinders reproducibility. The bottleneck is not the simulation engines themselves, but the lack of infrastructure connecting experiment design, execution, and sharing into a single verifiable workflow. This paper introduces IIRSim Studio, a web-based workbench that addresses this gap through four contributions: (1) a visual environment for composing simulation pipelines on top of simulation frameworks, serving both novices learning simulation concepts and experts piloting large-scale experiments; (2) a component lifecycle that supports authoring, versioning, and sharing custom simulation components through Git-backed storage and runtime injection; (3) a provenance model based on experiment bundles and environment templates that makes the scope of replication explicit; and (4) a shared-task workflow, demonstrated through the re-deployment of a Sim4IA micro-task. IIRSim Studio is available as a hosted service and as a portable containerized deployment.
Information Farming: From Berry Picking to Berry Growing
Jan 18, 2026The classic paradigms of Berry Picking and Information Foraging Theory have framed users as gatherers, opportunistically searching across distributed sources to satisfy evolving information needs. However, the rise of GenAI is driving a fundamental transformation in how people produce, structure, and reuse information - one that these paradigms no longer fully capture. This transformation is analogous to the Neolithic Revolution, when societies shifted from hunting and gathering to cultivation. Generative technologies empower users to "farm" information by planting seeds in the form of prompts, cultivating workflows over time, and harvesting richly structured, relevant yields within their own plots, rather than foraging across others people's patches. In this perspectives paper, we introduce the notion of Information Farming as a conceptual framework and argue that it represents a natural evolution in how people engage with information. Drawing on historical analogy and empirical evidence, we examine the benefits and opportunities of information farming, its implications for design and evaluation, and the accompanying risks posed by this transition. We hypothesize that as GenAI technologies proliferate, cultivating information will increasingly supplant transient, patch-based foraging as a dominant mode of engagement, marking a broader shift in human-information interaction and its study.
* ACM CHIIR 2026
Answering Questions in Stages: Prompt Chaining for Contract QA
Oct 09, 2024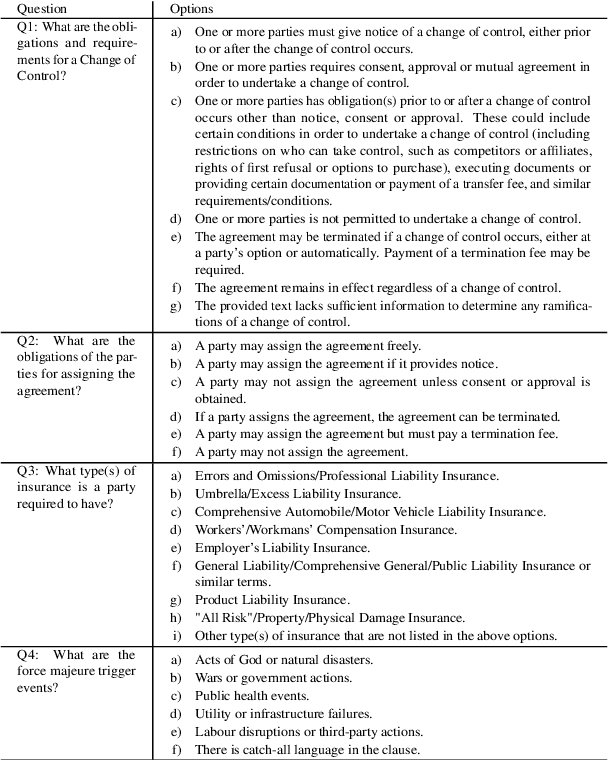


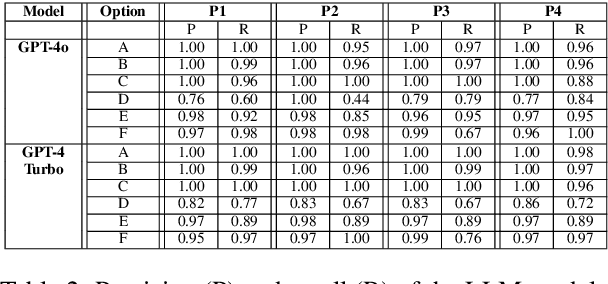
Finding answers to legal questions about clauses in contracts is an important form of analysis in many legal workflows (e.g., understanding market trends, due diligence, risk mitigation) but more important is being able to do this at scale. Prior work showed that it is possible to use large language models with simple zero-shot prompts to generate structured answers to questions, which can later be incorporated into legal workflows. Such prompts, while effective on simple and straightforward clauses, fail to perform when the clauses are long and contain information not relevant to the question. In this paper, we propose two-stage prompt chaining to produce structured answers to multiple-choice and multiple-select questions and show that they are more effective than simple prompts on more nuanced legal text. We analyze situations where this technique works well and areas where further refinement is needed, especially when the underlying linguistic variations are more than can be captured by simply specifying possible answers. Finally, we discuss future research that seeks to refine this work by improving stage one results by making them more question-specific.
O Contract, Where Art Thou? Contract Management as a SharePoint Oddity
Dec 14, 2023
For many legal operations teams, the management of the contracts and agreements that their organization are negotiating or have been executed is an encompassing and time-consuming task. This has resulted in specialized tools for Contract Lifecycle Management (CLM) have grown steadily in demand over the last decade. Transitioning to such tools can itself be an arduous and costly process and so a logical step would be to augment existing storage solutions. In this paper, we present the analysis of 26 semi-structured interviews with legal operations professionals about their trials and tribulations with using Microsoft SharePoint for contract management. We find that while there is promise, too much of what is needed to be successful requires more technical prowess than might be easily available to those empowered to put it in place.
A Search for Prompts: Generating Structured Answers from Contracts
Oct 16, 2023In many legal processes being able to action on the concrete implication of a legal question can be valuable to automating human review or signalling certain conditions (e.g., alerts around automatic renewal). To support such tasks, we present a form of legal question answering that seeks to return one (or more) fixed answers for a question about a contract clause. After showing that unstructured generative question answering can have questionable outcomes for such a task, we discuss our exploration methodology for legal question answering prompts using OpenAI's \textit{GPT-3.5-Turbo} and provide a summary of insights. Using insights gleaned from our qualitative experiences, we compare our proposed template prompts against a common semantic matching approach and find that our prompt templates are far more accurate despite being less reliable in the exact response return. With some additional tweaks to prompts and the use of in-context learning, we are able to further improve the performance of our proposed strategy while maximizing the reliability of responses as best we can.