 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeLogicPrpBank: A Corpus for Logical Implication and Equivalence
Feb 14, 2024
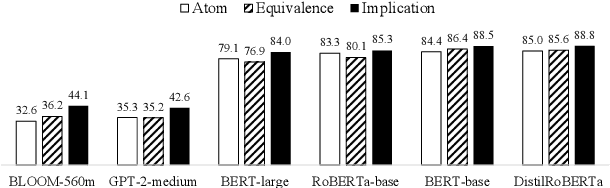


Logic reasoning has been critically needed in problem-solving and decision-making. Although Language Models (LMs) have demonstrated capabilities of handling multiple reasoning tasks (e.g., commonsense reasoning), their ability to reason complex mathematical problems, specifically propositional logic, remains largely underexplored. This lack of exploration can be attributed to the limited availability of annotated corpora. Here, we present a well-labeled propositional logic corpus, LogicPrpBank, containing 7093 Propositional Logic Statements (PLSs) across six mathematical subjects, to study a brand-new task of reasoning logical implication and equivalence. We benchmark LogicPrpBank with widely-used LMs to show that our corpus offers a useful resource for this challenging task and there is ample room for model improvement.
A Survey on Knowledge Graphs for Healthcare: Resources, Applications, and Promises
Jun 07, 2023



Healthcare knowledge graphs (HKGs) have emerged as a promising tool for organizing medical knowledge in a structured and interpretable way, which provides a comprehensive view of medical concepts and their relationships. However, challenges such as data heterogeneity and limited coverage remain, emphasizing the need for further research in the field of HKGs. This survey paper serves as the first comprehensive overview of HKGs. We summarize the pipeline and key techniques for HKG construction (i.e., from scratch and through integration), as well as the common utilization approaches (i.e., model-free and model-based). To provide researchers with valuable resources, we organize existing HKGs (The resource is available at https://github.com/lujiaying/Awesome-HealthCare-KnowledgeBase) based on the data types they capture and application domains, supplemented with pertinent statistical information. In the application section, we delve into the transformative impact of HKGs across various healthcare domains, spanning from fine-grained basic science research to high-level clinical decision support. Lastly, we shed light on the opportunities for creating comprehensive and accurate HKGs in the era of large language models, presenting the potential to revolutionize healthcare delivery and enhance the interpretability and reliability of clinical prediction.
HiPrompt: Few-Shot Biomedical Knowledge Fusion via Hierarchy-Oriented Prompting
Apr 12, 2023Medical decision-making processes can be enhanced by comprehensive biomedical knowledge bases, which require fusing knowledge graphs constructed from different sources via a uniform index system. The index system often organizes biomedical terms in a hierarchy to provide the aligned entities with fine-grained granularity. To address the challenge of scarce supervision in the biomedical knowledge fusion (BKF) task, researchers have proposed various unsupervised methods. However, these methods heavily rely on ad-hoc lexical and structural matching algorithms, which fail to capture the rich semantics conveyed by biomedical entities and terms. Recently, neural embedding models have proved effective in semantic-rich tasks, but they rely on sufficient labeled data to be adequately trained. To bridge the gap between the scarce-labeled BKF and neural embedding models, we propose HiPrompt, a supervision-efficient knowledge fusion framework that elicits the few-shot reasoning ability of large language models through hierarchy-oriented prompts. Empirical results on the collected KG-Hi-BKF benchmark datasets demonstrate the effectiveness of HiPrompt.