 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeFrom Basic to Extra Features: Hypergraph Transformer Pretrain-then-Finetuning for Balanced Clinical Predictions on EHR
Jun 09, 2024Electronic Health Records (EHRs) contain rich patient information and are crucial for clinical research and practice. In recent years, deep learning models have been applied to EHRs, but they often rely on massive features, which may not be readily available for all patients. We propose HTP-Star, which leverages hypergraph structures with a pretrain-then-finetune framework for modeling EHR data, enabling seamless integration of additional features. Additionally, we design two techniques, namely (1) Smoothness-inducing Regularization and (2) Group-balanced Reweighting, to enhance the model's robustness during fine-tuning. Through experiments conducted on two real EHR datasets, we demonstrate that HTP-Star consistently outperforms various baselines while striking a balance between patients with basic and extra features.
LogicPrpBank: A Corpus for Logical Implication and Equivalence
Feb 14, 2024
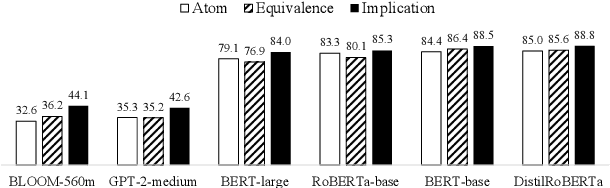


Logic reasoning has been critically needed in problem-solving and decision-making. Although Language Models (LMs) have demonstrated capabilities of handling multiple reasoning tasks (e.g., commonsense reasoning), their ability to reason complex mathematical problems, specifically propositional logic, remains largely underexplored. This lack of exploration can be attributed to the limited availability of annotated corpora. Here, we present a well-labeled propositional logic corpus, LogicPrpBank, containing 7093 Propositional Logic Statements (PLSs) across six mathematical subjects, to study a brand-new task of reasoning logical implication and equivalence. We benchmark LogicPrpBank with widely-used LMs to show that our corpus offers a useful resource for this challenging task and there is ample room for model improvement.
PGB: A PubMed Graph Benchmark for Heterogeneous Network Representation Learning
May 04, 2023There has been a rapid growth in biomedical literature, yet capturing the heterogeneity of the bibliographic information of these articles remains relatively understudied. Although graph mining research via heterogeneous graph neural networks has taken center stage, it remains unclear whether these approaches capture the heterogeneity of the PubMed database, a vast digital repository containing over 33 million articles. We introduce PubMed Graph Benchmark (PGB), a new benchmark dataset for evaluating heterogeneous graph embeddings for biomedical literature. PGB is one of the largest heterogeneous networks to date and consists of 30 million English articles. The benchmark contains rich metadata including abstract, authors, citations, MeSH terms, MeSH hierarchy, and some other information. The benchmark contains an evaluation task of 21 systematic reviews topics from 3 different datasets. In PGB, we aggregate the metadata associated with the biomedical articles from PubMed into a unified source and make the benchmark publicly available for any future works.
MedDiff: Generating Electronic Health Records using Accelerated Denoising Diffusion Model
Feb 08, 2023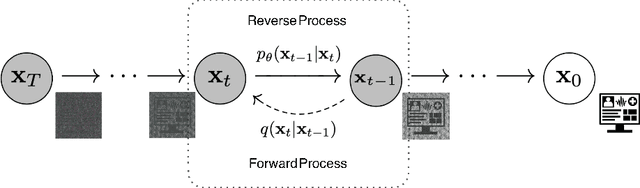

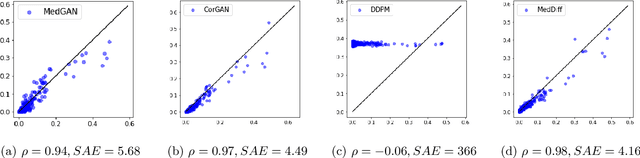
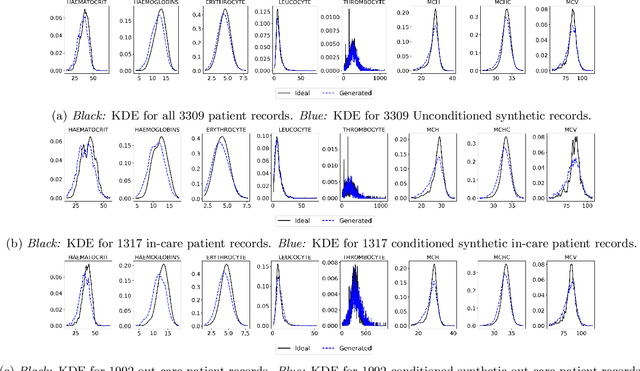
Due to patient privacy protection concerns, machine learning research in healthcare has been undeniably slower and limited than in other application domains. High-quality, realistic, synthetic electronic health records (EHRs) can be leveraged to accelerate methodological developments for research purposes while mitigating privacy concerns associated with data sharing. The current state-of-the-art model for synthetic EHR generation is generative adversarial networks, which are notoriously difficult to train and can suffer from mode collapse. Denoising Diffusion Probabilistic Models, a class of generative models inspired by statistical thermodynamics, have recently been shown to generate high-quality synthetic samples in certain domains. It is unknown whether these can generalize to generation of large-scale, high-dimensional EHRs. In this paper, we present a novel generative model based on diffusion models that is the first successful application on electronic health records. Our model proposes a mechanism to perform class-conditional sampling to preserve label information. We also introduce a new sampling strategy to accelerate the inference speed. We empirically show that our model outperforms existing state-of-the-art synthetic EHR generation methods.
An Efficient Nonlinear Acceleration method that Exploits Symmetry of the Hessian
Oct 22, 2022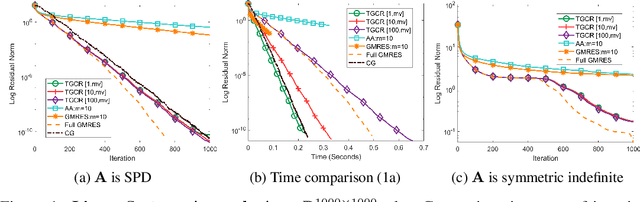
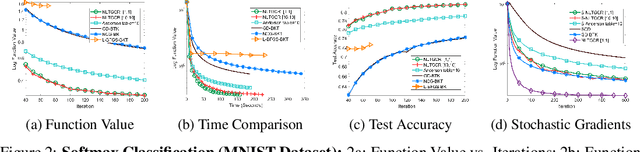
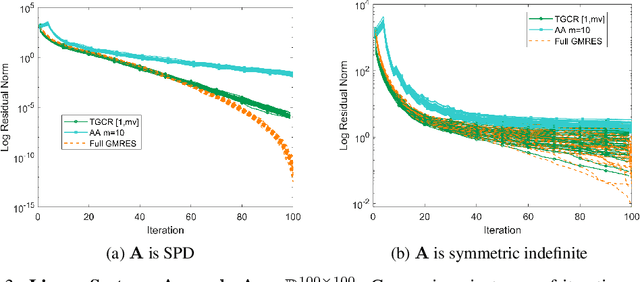
Nonlinear acceleration methods are powerful techniques to speed up fixed-point iterations. However, many acceleration methods require storing a large number of previous iterates and this can become impractical if computational resources are limited. In this paper, we propose a nonlinear Truncated Generalized Conjugate Residual method (nlTGCR) whose goal is to exploit the symmetry of the Hessian to reduce memory usage. The proposed method can be interpreted as either an inexact Newton or a quasi-Newton method. We show that, with the help of global strategies like residual check techniques, nlTGCR can converge globally for general nonlinear problems and that under mild conditions, nlTGCR is able to achieve superlinear convergence. We further analyze the convergence of nlTGCR in a stochastic setting. Numerical results demonstrate the superiority of nlTGCR when compared with several other competitive baseline approaches on a few problems. Our code will be available in the future.
MULTIPAR: Supervised Irregular Tensor Factorization with Multi-task Learning
Aug 09, 2022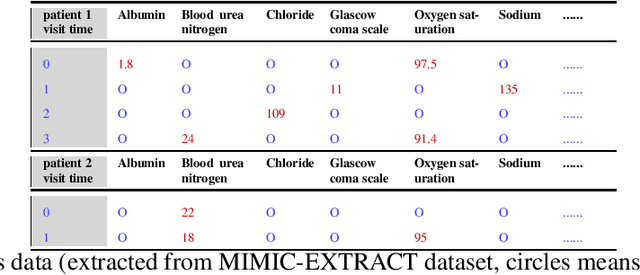
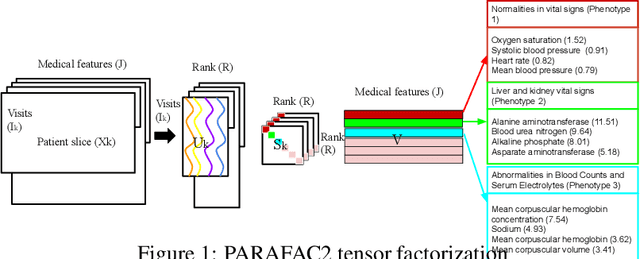
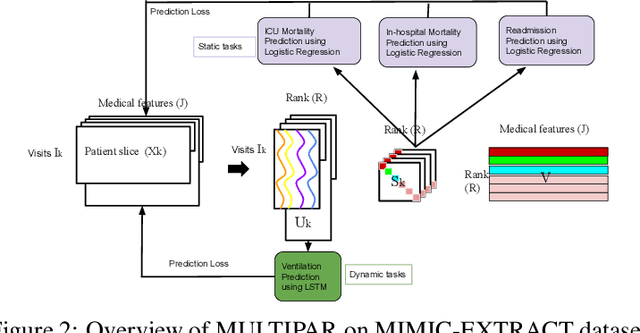
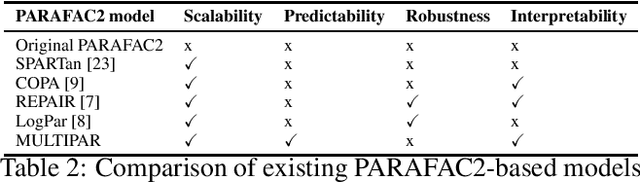
Tensor factorization has received increasing interest due to its intrinsic ability to capture latent factors in multi-dimensional data with many applications such as recommender systems and Electronic Health Records (EHR) mining. PARAFAC2 and its variants have been proposed to address irregular tensors where one of the tensor modes is not aligned, e.g., different users in recommender systems or patients in EHRs may have different length of records. PARAFAC2 has been successfully applied on EHRs for extracting meaningful medical concepts (phenotypes). Despite recent advancements, current models' predictability and interpretability are not satisfactory, which limits its utility for downstream analysis. In this paper, we propose MULTIPAR: a supervised irregular tensor factorization with multi-task learning. MULTIPAR is flexible to incorporate both static (e.g. in-hospital mortality prediction) and continuous or dynamic (e.g. the need for ventilation) tasks. By supervising the tensor factorization with downstream prediction tasks and leveraging information from multiple related predictive tasks, MULTIPAR can yield not only more meaningful phenotypes but also better predictive performance for downstream tasks. We conduct extensive experiments on two real-world temporal EHR datasets to demonstrate that MULTIPAR is scalable and achieves better tensor fit with more meaningful subgroups and stronger predictive performance compared to existing state-of-the-art methods.
Solve Minimax Optimization by Anderson Acceleration
Oct 06, 2021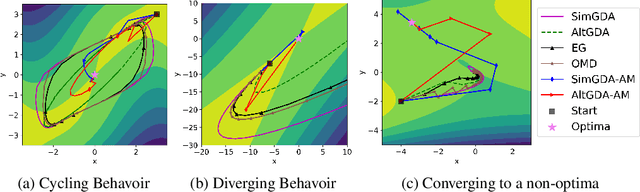

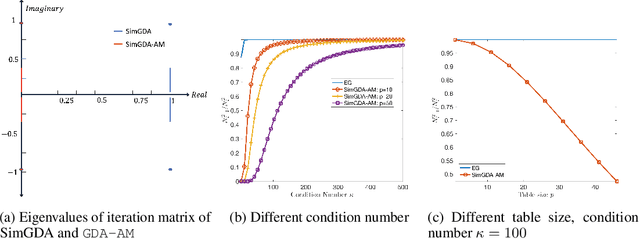

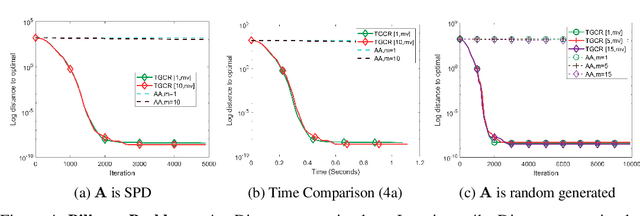
Many modern machine learning algorithms such as generative adversarial networks (GANs) and adversarial training can be formulated as minimax optimization. Gradient descent ascent (GDA) is the most commonly used algorithm due to its simplicity. However, GDA can converge to non-optimal minimax points. We propose a new minimax optimization framework, GDA-AM, that views the GDAdynamics as a fixed-point iteration and solves it using Anderson Mixing to con-verge to the local minimax. It addresses the diverging issue of simultaneous GDAand accelerates the convergence of alternating GDA. We show theoretically that the algorithm can achieve global convergence for bilinear problems under mild conditions. We also empirically show that GDA-AMsolves a variety of minimax problems and improves GAN training on several datasets