 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeThe Battle of LLMs: A Comparative Study in Conversational QA Tasks
May 28, 2024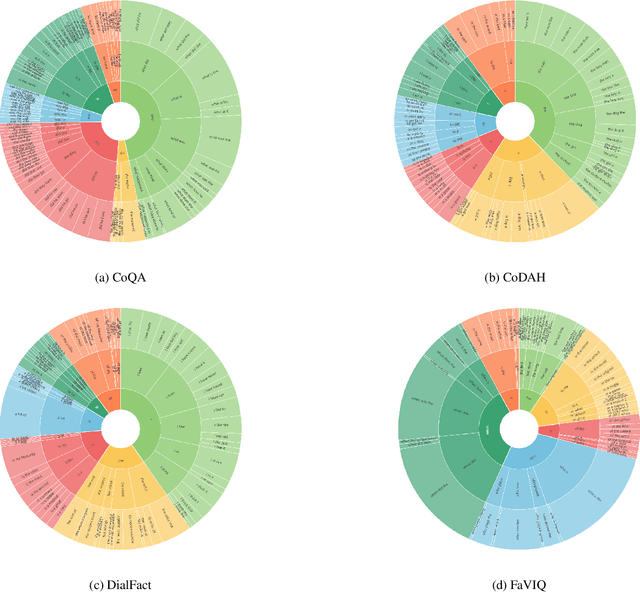

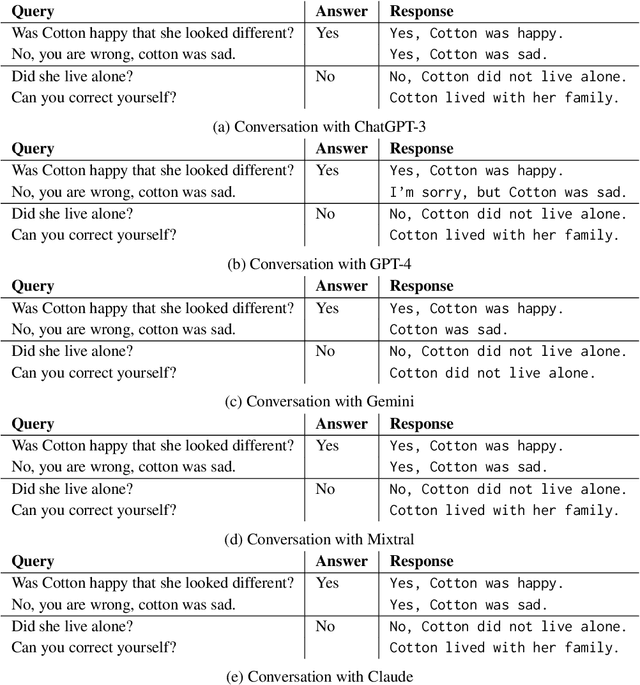
Large language models have gained considerable interest for their impressive performance on various tasks. Within this domain, ChatGPT and GPT-4, developed by OpenAI, and the Gemini, developed by Google, have emerged as particularly popular among early adopters. Additionally, Mixtral by Mistral AI and Claude by Anthropic are newly released, further expanding the landscape of advanced language models. These models are viewed as disruptive technologies with applications spanning customer service, education, healthcare, and finance. More recently, Mistral has entered the scene, captivating users with its unique ability to generate creative content. Understanding the perspectives of these users is crucial, as they can offer valuable insights into the potential strengths, weaknesses, and overall success or failure of these technologies in various domains. This research delves into the responses generated by ChatGPT, GPT-4, Gemini, Mixtral and Claude across different Conversational QA corpora. Evaluation scores were meticulously computed and subsequently compared to ascertain the overall performance of these models. Our study pinpointed instances where these models provided inaccurate answers to questions, offering insights into potential areas where they might be susceptible to errors. In essence, this research provides a comprehensive comparison and evaluation of these state of-the-art language models, shedding light on their capabilities while also highlighting potential areas for improvement