 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeThe use of Synthetic Data to solve the scalability and data availability problems in Smart City Digital Twins
Jul 06, 2022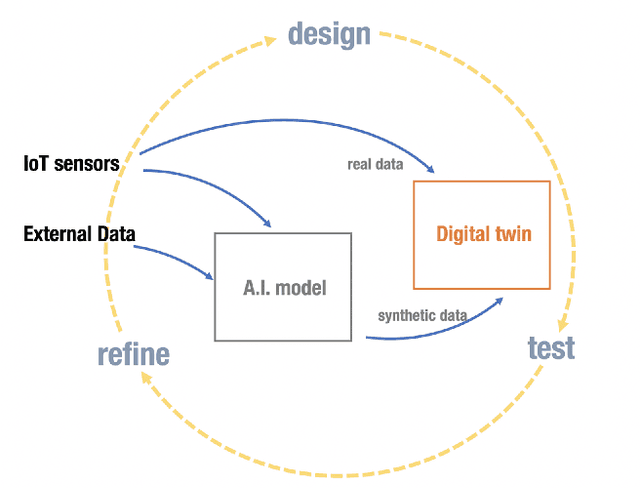
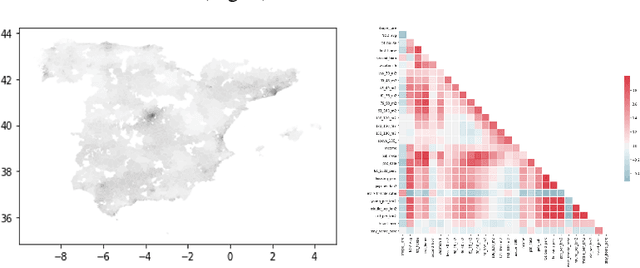


The A.I. disruption and the need to compete on innovation are impacting cities that have an increasing necessity to become innovation hotspots. However, without proven solutions, experimentation, often unsuccessful, is needed. But experimentation in cities has many undesirable effects not only for its citizens but also reputational if unsuccessful. Digital Twins, so popular in other areas, seem like a promising way to expand experimentation proposals but in simulated environments, translating only the half-baked ones, the ones with higher probability of success, to real environments and therefore minimizing risks. However, Digital Twins are data intensive and need highly localized data, making them difficult to scale, particularly to small cities, and with the high cost associated to data collection. We present an alternative based on synthetic data that given some conditions, quite common in Smart Cities, can solve these two problems together with a proof-of-concept based on NO2 pollution.
SmartDet: Context-Aware Dynamic Control of Edge Task Offloading for Mobile Object Detection
Jan 11, 2022
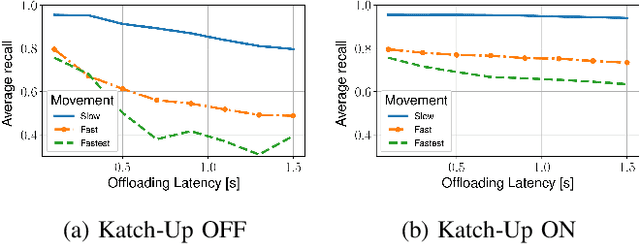

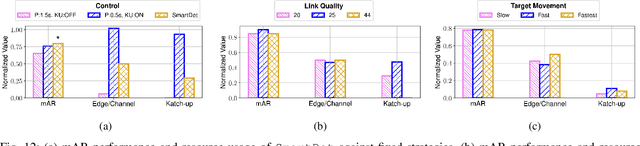
Mobile devices increasingly rely on object detection (OD) through deep neural networks (DNNs) to perform critical tasks. Due to their high complexity, the execution of these DNNs requires excessive time and energy. Low-complexity object tracking (OT) can be used with OD, where the latter is periodically applied to generate "fresh" references for tracking. However, the frames processed with OD incur large delays, which may make the reference outdated and degrade tracking quality. Herein, we propose to use edge computing in this context, and establish parallel OT (at the mobile device) and OD (at the edge server) processes that are resilient to large OD latency. We propose Katch-Up, a novel tracking mechanism that improves the system resilience to excessive OD delay. However, while Katch-Up significantly improves performance, it also increases the computing load of the mobile device. Hence, we design SmartDet, a low-complexity controller based on deep reinforcement learning (DRL) that learns controlling the trade-off between resource utilization and OD performance. SmartDet takes as input context-related information related to the current video content and the current network conditions to optimize frequency and type of OD offloading, as well as Katch-Up utilization. We extensively evaluate SmartDet on a real-world testbed composed of a JetSon Nano as mobile device and a GTX 980 Ti as edge server, connected through a Wi-Fi link. Experimental results show that SmartDet achieves an optimal balance between tracking performance - mean Average Recall (mAR) and resource usage. With respect to a baseline with full Katch-Upusage and maximum channel usage, we still increase mAR by 4% while using 50% less of the channel and 30% power resources associated with Katch-Up. With respect to a fixed strategy using minimal resources, we increase mAR by 20% while using Katch-Up on 1/3 of the frames.
BottleFit: Learning Compressed Representations in Deep Neural Networks for Effective and Efficient Split Computing
Jan 07, 2022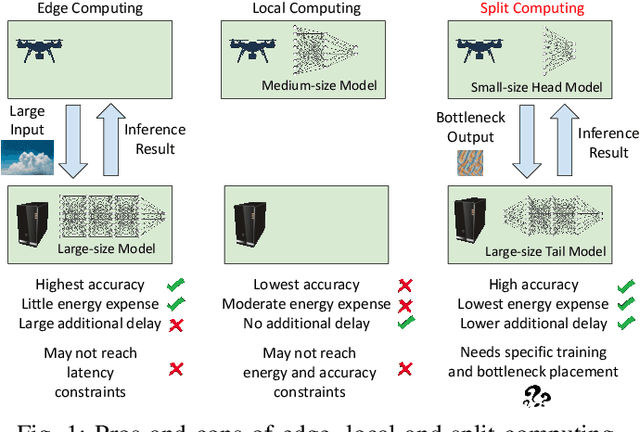
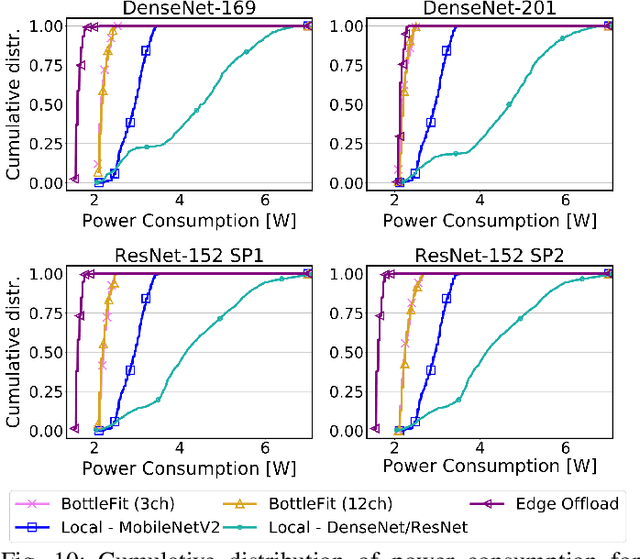
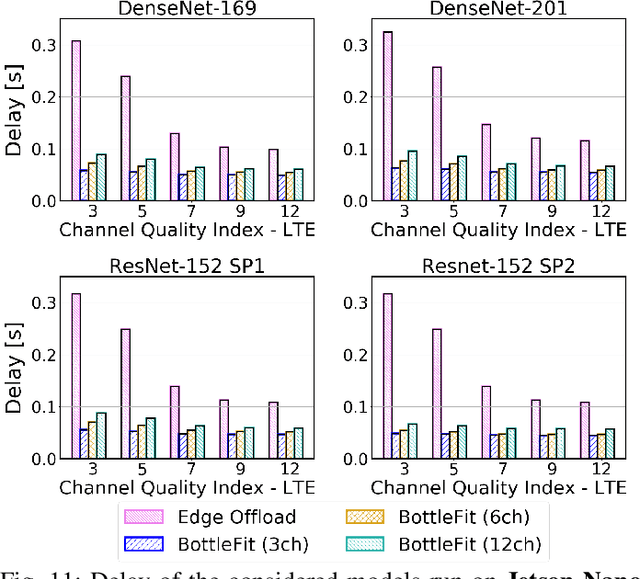
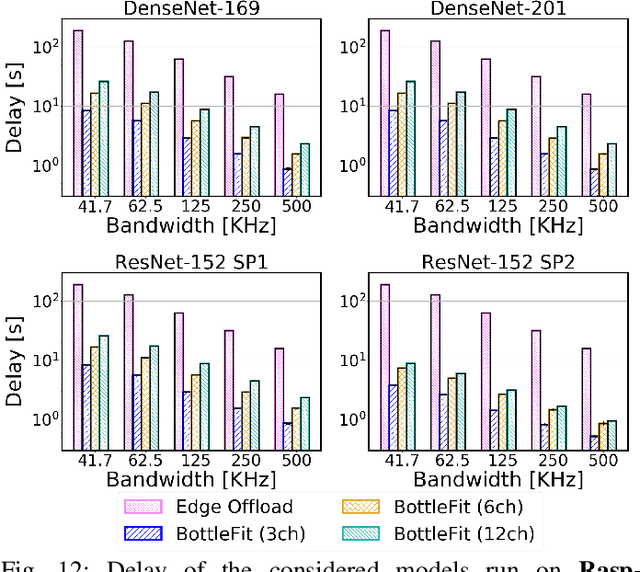
Although mission-critical applications require the use of deep neural networks (DNNs), their continuous execution at mobile devices results in a significant increase in energy consumption. While edge offloading can decrease energy consumption, erratic patterns in channel quality, network and edge server load can lead to severe disruption of the system's key operations. An alternative approach, called split computing, generates compressed representations within the model (called "bottlenecks"), to reduce bandwidth usage and energy consumption. Prior work has proposed approaches that introduce additional layers, to the detriment of energy consumption and latency. For this reason, we propose a new framework called BottleFit, which, in addition to targeted DNN architecture modifications, includes a novel training strategy to achieve high accuracy even with strong compression rates. We apply BottleFit on cutting-edge DNN models in image classification, and show that BottleFit achieves 77.1% data compression with up to 0.6% accuracy loss on ImageNet dataset, while state of the art such as SPINN loses up to 6% in accuracy. We experimentally measure the power consumption and latency of an image classification application running on an NVIDIA Jetson Nano board (GPU-based) and a Raspberry PI board (GPU-less). We show that BottleFit decreases power consumption and latency respectively by up to 49% and 89% with respect to (w.r.t.) local computing and by 37% and 55% w.r.t. edge offloading. We also compare BottleFit with state-of-the-art autoencoders-based approaches, and show that (i) BottleFit reduces power consumption and execution time respectively by up to 54% and 44% on the Jetson and 40% and 62% on Raspberry PI; (ii) the size of the head model executed on the mobile device is 83 times smaller. The code repository will be published for full reproducibility of the results.