 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeSC2: Supervised Compression for Split Computing
Paper and Code
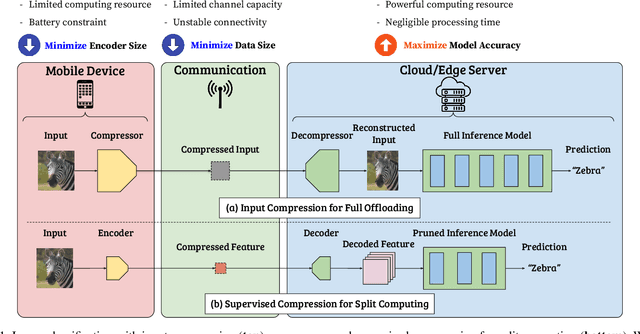
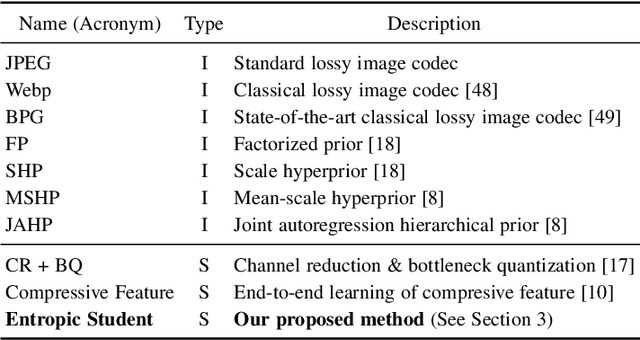
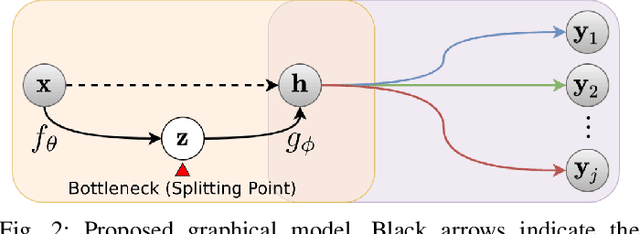
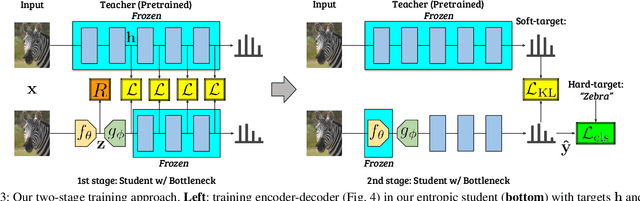
Split computing distributes the execution of a neural network (e.g., for a classification task) between a mobile device and a more powerful edge server. A simple alternative to splitting the network is to carry out the supervised task purely on the edge server while compressing and transmitting the full data, and most approaches have barely outperformed this baseline. This paper proposes a new approach for discretizing and entropy-coding intermediate feature activations to efficiently transmit them from the mobile device to the edge server. We show that a efficient splittable network architecture results from a three-way tradeoff between (a) minimizing the computation on the mobile device, (b) minimizing the size of the data to be transmitted, and (c) maximizing the model's prediction performance. We propose an architecture based on this tradeoff and train the splittable network and entropy model in a knowledge distillation framework. In an extensive set of experiments involving three vision tasks, three datasets, nine baselines, and more than 180 trained models, we show that our approach improves supervised rate-distortion tradeoffs while maintaining a considerably smaller encoder size. We also release sc2bench, an installable Python package, to encourage and facilitate future studies on supervised compression for split computing (SC2).