 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeFairLoRA: Unpacking Bias Mitigation in Vision Models with Fairness-Driven Low-Rank Adaptation
Paper and Code
Oct 22, 2024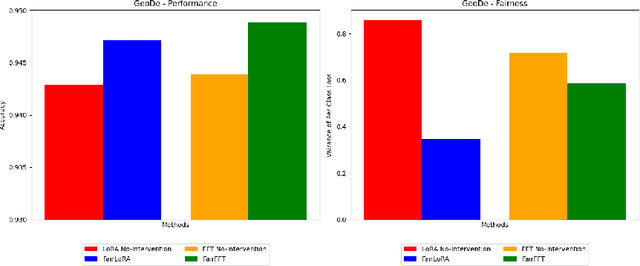


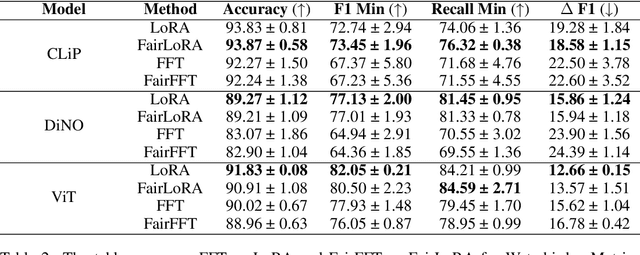
Recent advances in parameter-efficient fine-tuning methods, such as Low Rank Adaptation (LoRA), have gained significant attention for their ability to efficiently adapt large foundational models to various downstream tasks. These methods are appreciated for achieving performance comparable to full fine-tuning on aggregate-level metrics, while significantly reducing computational costs. To systematically address fairness in LLMs previous studies fine-tune on fairness specific data using a larger LoRA rank than typically used. In this paper, we introduce FairLoRA, a novel fairness-specific regularizer for LoRA aimed at reducing performance disparities across data subgroups by minimizing per-class variance in loss. To the best of our knowledge, we are the first to introduce a fairness based finetuning through LoRA. Our results demonstrate that the need for higher ranks to mitigate bias is not universal; it depends on factors such as the pre-trained model, dataset, and task. More importantly, we systematically evaluate FairLoRA across various vision models, including ViT, DiNO, and CLIP, in scenarios involving distribution shifts. We further emphasize the necessity of using multiple fairness metrics to obtain a holistic assessment of fairness, rather than relying solely on the metric optimized during training.