 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeTight Lower Bounds and Improved Convergence in Performative Prediction
Dec 04, 2024Performative prediction is a framework accounting for the shift in the data distribution induced by the prediction of a model deployed in the real world. Ensuring rapid convergence to a stable solution where the data distribution remains the same after the model deployment is crucial, especially in evolving environments. This paper extends the Repeated Risk Minimization (RRM) framework by utilizing historical datasets from previous retraining snapshots, yielding a class of algorithms that we call Affine Risk Minimizers and enabling convergence to a performatively stable point for a broader class of problems. We introduce a new upper bound for methods that use only the final iteration of the dataset and prove for the first time the tightness of both this new bound and the previous existing bounds within the same regime. We also prove that utilizing historical datasets can surpass the lower bound for last iterate RRM, and empirically observe faster convergence to the stable point on various performative prediction benchmarks. We offer at the same time the first lower bound analysis for RRM within the class of Affine Risk Minimizers, quantifying the potential improvements in convergence speed that could be achieved with other variants in our framework.
Do Explanations Explain? Model Knows Best
Mar 04, 2022



It is a mystery which input features contribute to a neural network's output. Various explanation (feature attribution) methods are proposed in the literature to shed light on the problem. One peculiar observation is that these explanations (attributions) point to different features as being important. The phenomenon raises the question, which explanation to trust? We propose a framework for evaluating the explanations using the neural network model itself. The framework leverages the network to generate input features that impose a particular behavior on the output. Using the generated features, we devise controlled experimental setups to evaluate whether an explanation method conforms to an axiom. Thus we propose an empirical framework for axiomatic evaluation of explanation methods. We evaluate well-known and promising explanation solutions using the proposed framework. The framework provides a toolset to reveal properties and drawbacks within existing and future explanation solutions.
Are socially-aware trajectory prediction models really socially-aware?
Aug 24, 2021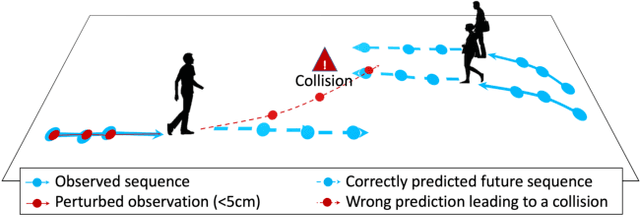
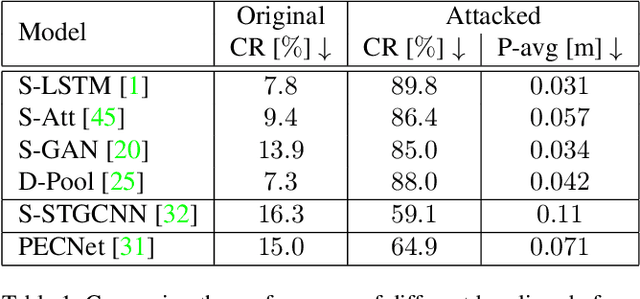
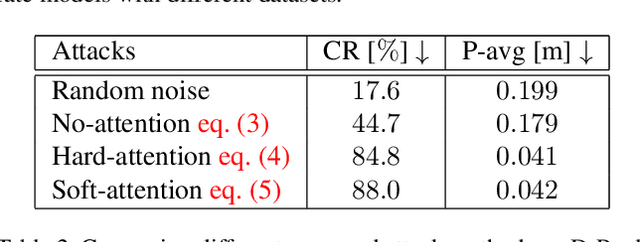

Our field has recently witnessed an arms race of neural network-based trajectory predictors. While these predictors are at the core of many applications such as autonomous navigation or pedestrian flow simulations, their adversarial robustness has not been carefully studied. In this paper, we introduce a socially-attended attack to assess the social understanding of prediction models in terms of collision avoidance. An attack is a small yet carefully-crafted perturbations to fail predictors. Technically, we define collision as a failure mode of the output, and propose hard- and soft-attention mechanisms to guide our attack. Thanks to our attack, we shed light on the limitations of the current models in terms of their social understanding. We demonstrate the strengths of our method on the recent trajectory prediction models. Finally, we show that our attack can be employed to increase the social understanding of state-of-the-art models. The code is available online: https://s-attack.github.io/