 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeThe Culture Funnel: You Can't Align What isn't in the Data
Jun 11, 2026Current cultural alignment approaches focus on inference-time interventions, assuming models already contain sufficient cultural knowledge. We argue modern LLM pipelines suffer from a cultural data funnel. Using a multidimensional tagging framework across pretraining, fine-tuning, alignment, and reasoning datasets, we show explicit cultural signals decline sharply during post-training, while geographically concentrated, task-specialized data dominates. Multilinguality enhances geographic diversity of cultural knowledge but does not ensure balanced representation. Our tags improve downstream cultural benchmark performance, demonstrating that advances require shifting focus in training data pipelines. To facilitate future research, we release our culturally tagged dataset with 5.6M samples at https://huggingface.co/datasets/CohereLabs/CultureMarkers.
Tiny Aya: Bridging Scale and Multilingual Depth
Mar 12, 2026Tiny Aya redefines what a small multilingual language model can achieve. Trained on 70 languages and refined through region-aware posttraining, it delivers state-of-the-art in translation quality, strong multilingual understanding, and high-quality target-language generation, all with just 3.35B parameters. The release includes a pretrained foundation model, a globally balanced instruction-tuned variant, and three region-specialized models targeting languages from Africa, South Asia, Europe, Asia-Pacific, and West Asia. This report details the training strategy, data composition, and comprehensive evaluation framework behind Tiny Aya, and presents an alternative scaling path for multilingual AI: one centered on efficiency, balanced performance across languages, and practical deployment.
Performance Control in Early Exiting to Deploy Large Models at the Same Cost of Smaller Ones
Dec 26, 2024Early Exiting (EE) is a promising technique for speeding up inference by adaptively allocating compute resources to data points based on their difficulty. The approach enables predictions to exit at earlier layers for simpler samples while reserving more computation for challenging ones. In this study, we first present a novel perspective on the EE approach, showing that larger models deployed with EE can achieve higher performance than smaller models while maintaining similar computational costs. As existing EE approaches rely on confidence estimation at each exit point, we further study the impact of overconfidence on the controllability of the compute-performance trade-off. We introduce Performance Control Early Exiting (PCEE), a method that enables accuracy thresholding by basing decisions not on a data point's confidence but on the average accuracy of samples with similar confidence levels from a held-out validation set. In our experiments, we show that PCEE offers a simple yet computationally efficient approach that provides better control over performance than standard confidence-based approaches, and allows us to scale up model sizes to yield performance gain while reducing the computational cost.
Tight Lower Bounds and Improved Convergence in Performative Prediction
Dec 04, 2024Performative prediction is a framework accounting for the shift in the data distribution induced by the prediction of a model deployed in the real world. Ensuring rapid convergence to a stable solution where the data distribution remains the same after the model deployment is crucial, especially in evolving environments. This paper extends the Repeated Risk Minimization (RRM) framework by utilizing historical datasets from previous retraining snapshots, yielding a class of algorithms that we call Affine Risk Minimizers and enabling convergence to a performatively stable point for a broader class of problems. We introduce a new upper bound for methods that use only the final iteration of the dataset and prove for the first time the tightness of both this new bound and the previous existing bounds within the same regime. We also prove that utilizing historical datasets can surpass the lower bound for last iterate RRM, and empirically observe faster convergence to the stable point on various performative prediction benchmarks. We offer at the same time the first lower bound analysis for RRM within the class of Affine Risk Minimizers, quantifying the potential improvements in convergence speed that could be achieved with other variants in our framework.
Performative Prediction on Games and Mechanism Design
Aug 09, 2024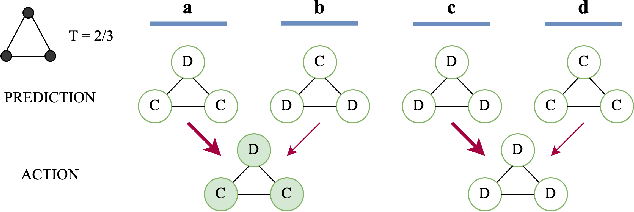
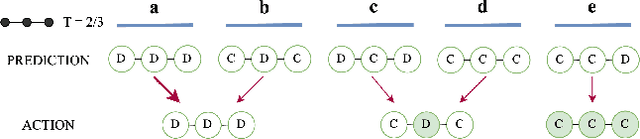
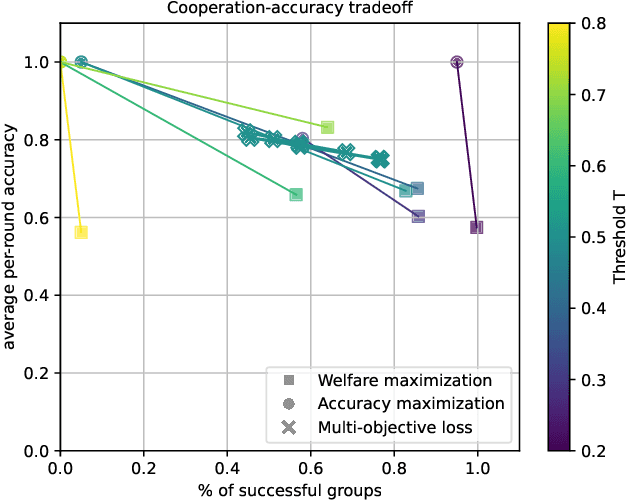
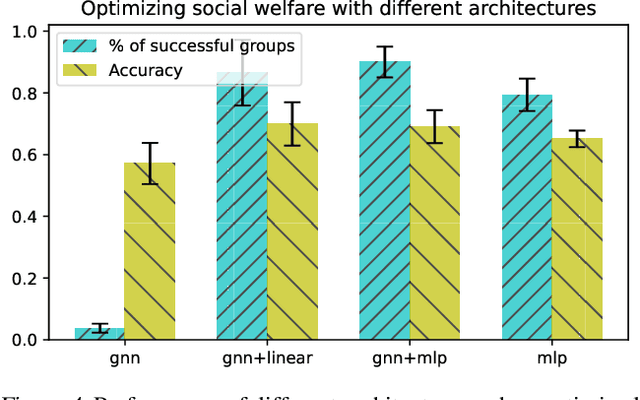
Predictions often influence the reality which they aim to predict, an effect known as performativity. Existing work focuses on accuracy maximization under this effect, but model deployment may have important unintended impacts, especially in multiagent scenarios. In this work, we investigate performative prediction in a concrete game-theoretic setting where social welfare is an alternative objective to accuracy maximization. We explore a collective risk dilemma scenario where maximising accuracy can negatively impact social welfare, when predicting collective behaviours. By assuming knowledge of a Bayesian agent behavior model, we then show how to achieve better trade-offs and use them for mechanism design.
Performative Prediction with Neural Networks
Apr 14, 2023
Performative prediction is a framework for learning models that influence the data they intend to predict. We focus on finding classifiers that are performatively stable, i.e. optimal for the data distribution they induce. Standard convergence results for finding a performatively stable classifier with the method of repeated risk minimization assume that the data distribution is Lipschitz continuous to the model's parameters. Under this assumption, the loss must be strongly convex and smooth in these parameters; otherwise, the method will diverge for some problems. In this work, we instead assume that the data distribution is Lipschitz continuous with respect to the model's predictions, a more natural assumption for performative systems. As a result, we are able to significantly relax the assumptions on the loss function. In particular, we do not need to assume convexity with respect to the model's parameters. As an illustration, we introduce a resampling procedure that models realistic distribution shifts and show that it satisfies our assumptions. We support our theory by showing that one can learn performatively stable classifiers with neural networks making predictions about real data that shift according to our proposed procedure.