 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeInequality in Congestion Games with Learning Agents
Jan 28, 2026Who benefits from expanding transport networks? While designed to improve mobility, such interventions can also create inequality. In this paper, we show that disparities arise not only from the structure of the network itself but also from differences in how commuters adapt to it. We model commuters as reinforcement learning agents who adapt their travel choices at different learning rates, reflecting unequal access to resources and information. To capture potential efficiency-fairness tradeoffs, we introduce the Price of Learning (PoL), a measure of inefficiency during learning. We analyze both a stylized network -- inspired in the well-known Braess's paradox, yet with two-source nodes -- and an abstraction of a real-world metro system (Amsterdam). Our simulations show that network expansions can simultaneously increase efficiency and amplify inequality, especially when faster learners disproportionately benefit from new routes before others adapt. These results highlight that transport policies must account not only for equilibrium outcomes but also for the heterogeneous ways commuters adapt, since both shape the balance between efficiency and fairness.
Do LLMs trust AI regulation? Emerging behaviour of game-theoretic LLM agents
Apr 11, 2025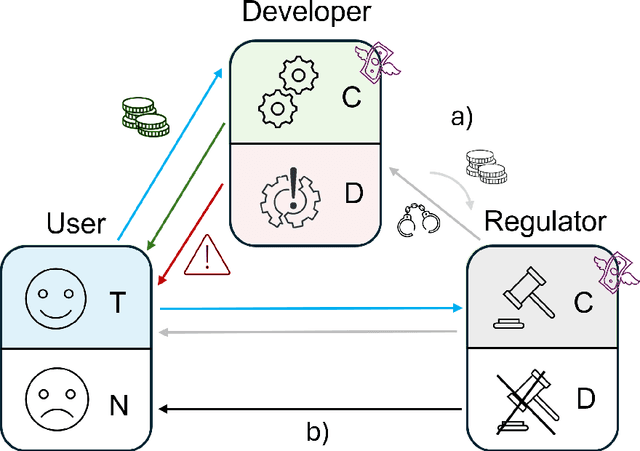
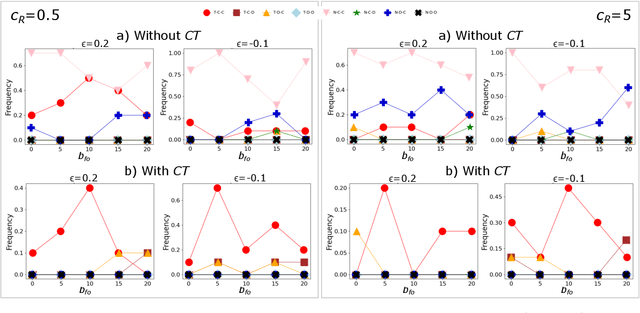
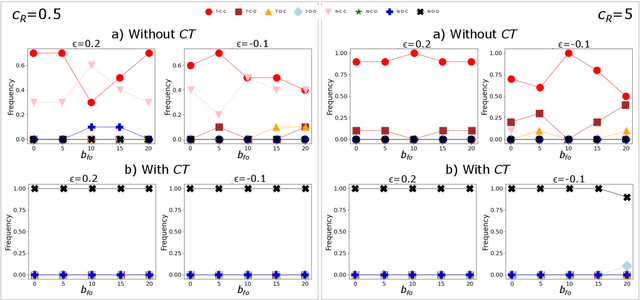
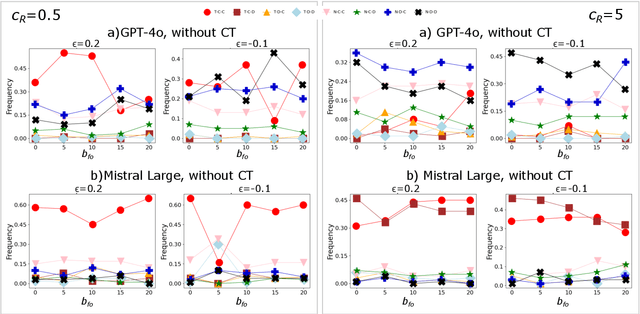
There is general agreement that fostering trust and cooperation within the AI development ecosystem is essential to promote the adoption of trustworthy AI systems. By embedding Large Language Model (LLM) agents within an evolutionary game-theoretic framework, this paper investigates the complex interplay between AI developers, regulators and users, modelling their strategic choices under different regulatory scenarios. Evolutionary game theory (EGT) is used to quantitatively model the dilemmas faced by each actor, and LLMs provide additional degrees of complexity and nuances and enable repeated games and incorporation of personality traits. Our research identifies emerging behaviours of strategic AI agents, which tend to adopt more "pessimistic" (not trusting and defective) stances than pure game-theoretic agents. We observe that, in case of full trust by users, incentives are effective to promote effective regulation; however, conditional trust may deteriorate the "social pact". Establishing a virtuous feedback between users' trust and regulators' reputation thus appears to be key to nudge developers towards creating safe AI. However, the level at which this trust emerges may depend on the specific LLM used for testing. Our results thus provide guidance for AI regulation systems, and help predict the outcome of strategic LLM agents, should they be used to aid regulation itself.
Media and responsible AI governance: a game-theoretic and LLM analysis
Mar 12, 2025This paper investigates the complex interplay between AI developers, regulators, users, and the media in fostering trustworthy AI systems. Using evolutionary game theory and large language models (LLMs), we model the strategic interactions among these actors under different regulatory regimes. The research explores two key mechanisms for achieving responsible governance, safe AI development and adoption of safe AI: incentivising effective regulation through media reporting, and conditioning user trust on commentariats' recommendation. The findings highlight the crucial role of the media in providing information to users, potentially acting as a form of "soft" regulation by investigating developers or regulators, as a substitute to institutional AI regulation (which is still absent in many regions). Both game-theoretic analysis and LLM-based simulations reveal conditions under which effective regulation and trustworthy AI development emerge, emphasising the importance of considering the influence of different regulatory regimes from an evolutionary game-theoretic perspective. The study concludes that effective governance requires managing incentives and costs for high quality commentaries.
Scalable Multi-Objective Reinforcement Learning with Fairness Guarantees using Lorenz Dominance
Nov 27, 2024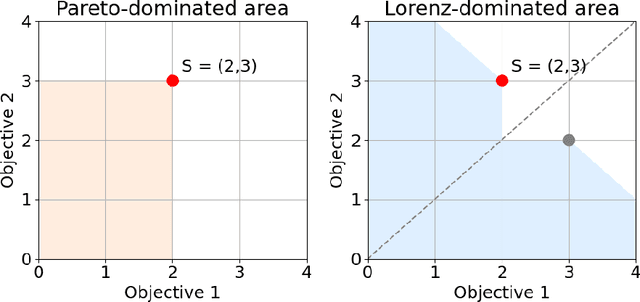

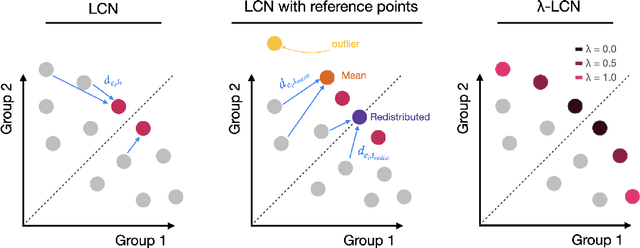
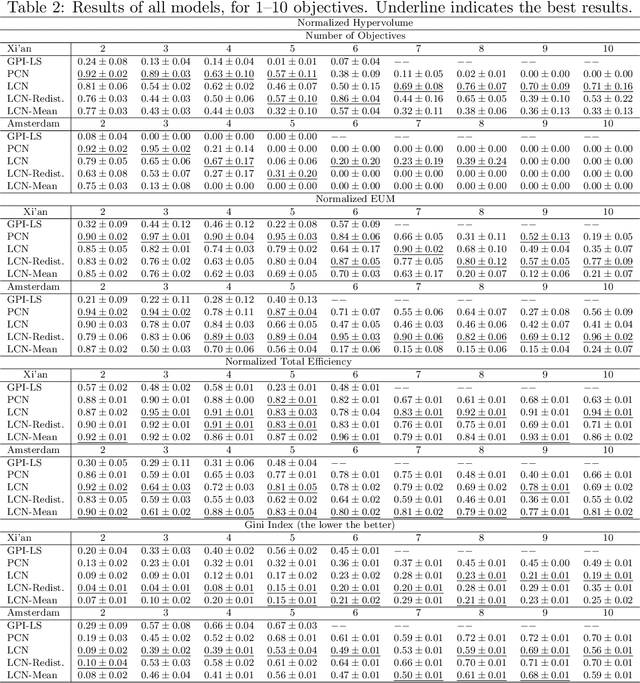
Multi-Objective Reinforcement Learning (MORL) aims to learn a set of policies that optimize trade-offs between multiple, often conflicting objectives. MORL is computationally more complex than single-objective RL, particularly as the number of objectives increases. Additionally, when objectives involve the preferences of agents or groups, ensuring fairness is socially desirable. This paper introduces a principled algorithm that incorporates fairness into MORL while improving scalability to many-objective problems. We propose using Lorenz dominance to identify policies with equitable reward distributions and introduce {\lambda}-Lorenz dominance to enable flexible fairness preferences. We release a new, large-scale real-world transport planning environment and demonstrate that our method encourages the discovery of fair policies, showing improved scalability in two large cities (Xi'an and Amsterdam). Our methods outperform common multi-objective approaches, particularly in high-dimensional objective spaces.
Performative Prediction on Games and Mechanism Design
Aug 09, 2024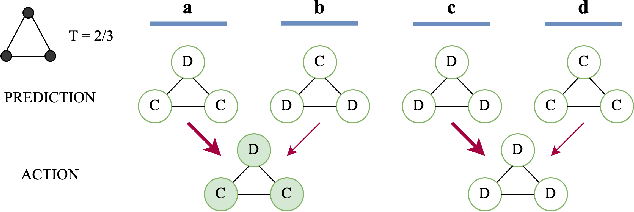
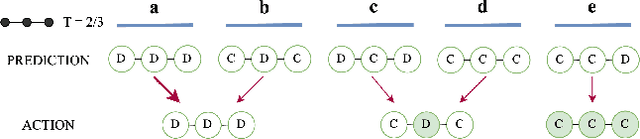
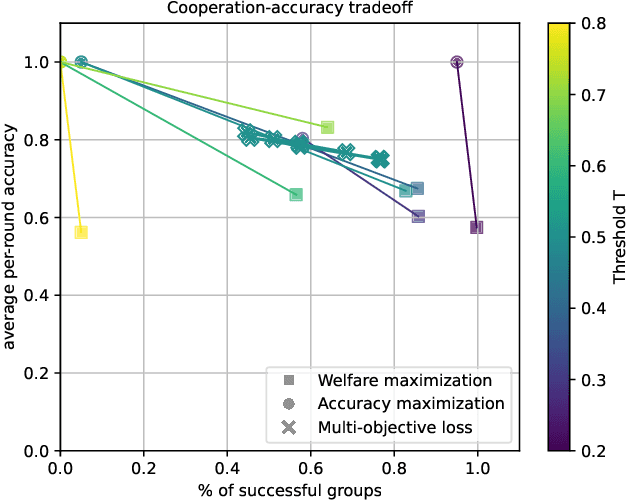
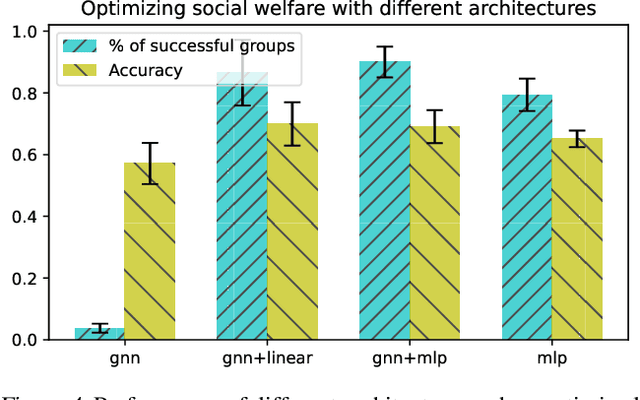
Predictions often influence the reality which they aim to predict, an effect known as performativity. Existing work focuses on accuracy maximization under this effect, but model deployment may have important unintended impacts, especially in multiagent scenarios. In this work, we investigate performative prediction in a concrete game-theoretic setting where social welfare is an alternative objective to accuracy maximization. We explore a collective risk dilemma scenario where maximising accuracy can negatively impact social welfare, when predicting collective behaviours. By assuming knowledge of a Bayesian agent behavior model, we then show how to achieve better trade-offs and use them for mechanism design.
Learning Collective Action under Risk Diversity
Jan 30, 2022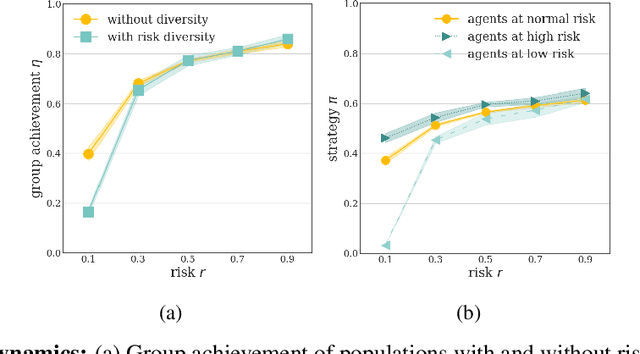
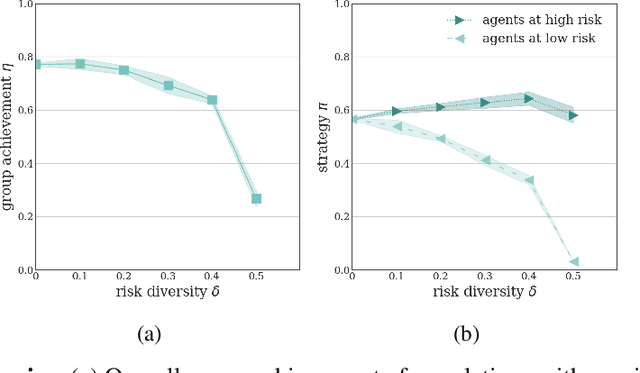
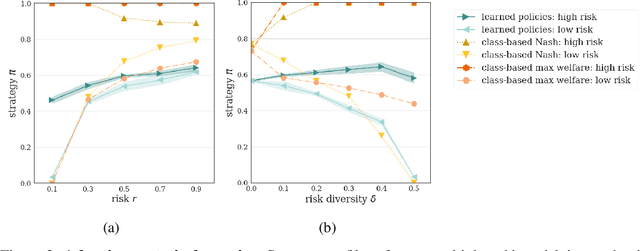
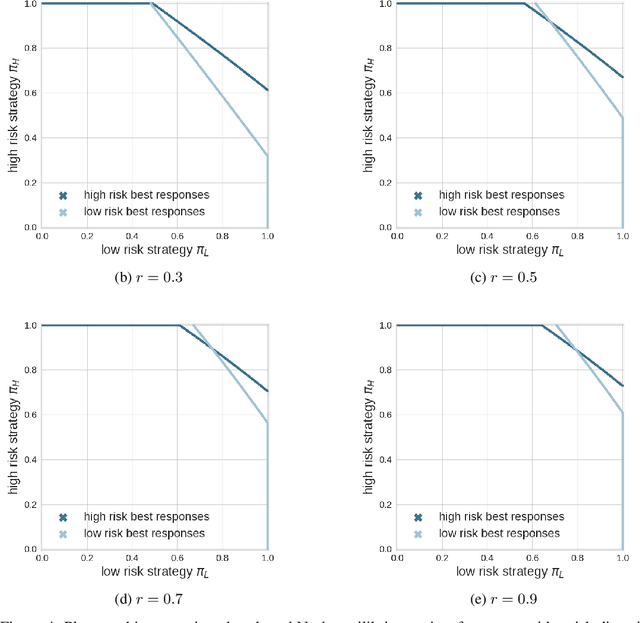
Collective risk dilemmas (CRDs) are a class of n-player games that represent societal challenges where groups need to coordinate to avoid the risk of a disastrous outcome. Multi-agent systems incurring such dilemmas face difficulties achieving cooperation and often converge to sub-optimal, risk-dominant solutions where everyone defects. In this paper we investigate the consequences of risk diversity in groups of agents learning to play CRDs. We find that risk diversity places new challenges to cooperation that are not observed in homogeneous groups. We show that increasing risk diversity significantly reduces overall cooperation and hinders collective target achievement. It leads to asymmetrical changes in agents' policies -- i.e. the increase in contributions from individuals at high risk is unable to compensate for the decrease in contributions from individuals at low risk -- which overall reduces the total contributions in a population. When comparing RL behaviors to rational individualistic and social behaviors, we find that RL populations converge to fairer contributions among agents. Our results highlight the need for aligning risk perceptions among agents or develop new learning techniques that explicitly account for risk diversity.
Local Wealth Redistribution Promotes Cooperation in Multiagent Systems
Feb 05, 2018


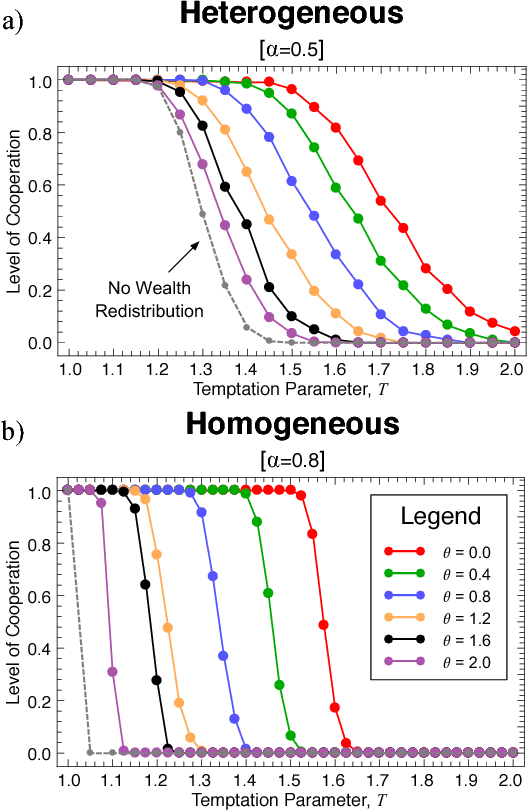
Designing mechanisms that leverage cooperation between agents has been a long-lasting goal in Multiagent Systems. The task is especially challenging when agents are selfish, lack common goals and face social dilemmas, i.e., situations in which individual interest conflicts with social welfare. Past works explored mechanisms that explain cooperation in biological and social systems, providing important clues for the aim of designing cooperative artificial societies. In particular, several works show that cooperation is able to emerge when specific network structures underlie agents' interactions. Notwithstanding, social dilemmas in which defection is highly tempting still pose challenges concerning the effective sustainability of cooperation. Here we propose a new redistribution mechanism that can be applied in structured populations of agents. Importantly, we show that, when implemented locally (i.e., agents share a fraction of their wealth surplus with their nearest neighbors), redistribution excels in promoting cooperation under regimes where, before, only defection prevailed.