 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeInequality in Congestion Games with Learning Agents
Jan 28, 2026Who benefits from expanding transport networks? While designed to improve mobility, such interventions can also create inequality. In this paper, we show that disparities arise not only from the structure of the network itself but also from differences in how commuters adapt to it. We model commuters as reinforcement learning agents who adapt their travel choices at different learning rates, reflecting unequal access to resources and information. To capture potential efficiency-fairness tradeoffs, we introduce the Price of Learning (PoL), a measure of inefficiency during learning. We analyze both a stylized network -- inspired in the well-known Braess's paradox, yet with two-source nodes -- and an abstraction of a real-world metro system (Amsterdam). Our simulations show that network expansions can simultaneously increase efficiency and amplify inequality, especially when faster learners disproportionately benefit from new routes before others adapt. These results highlight that transport policies must account not only for equilibrium outcomes but also for the heterogeneous ways commuters adapt, since both shape the balance between efficiency and fairness.
Facilitating Automated Online Consensus Building through Parallel Thinking
Mar 16, 2025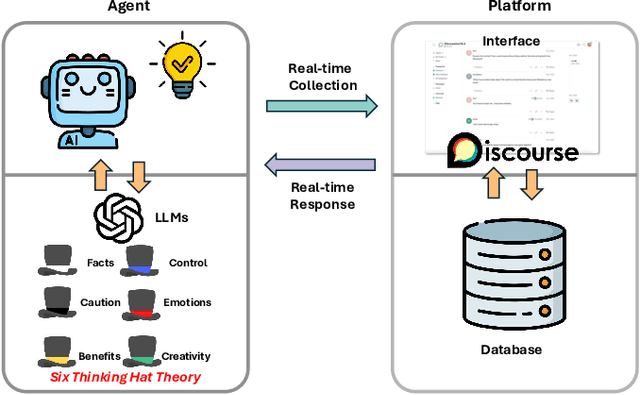

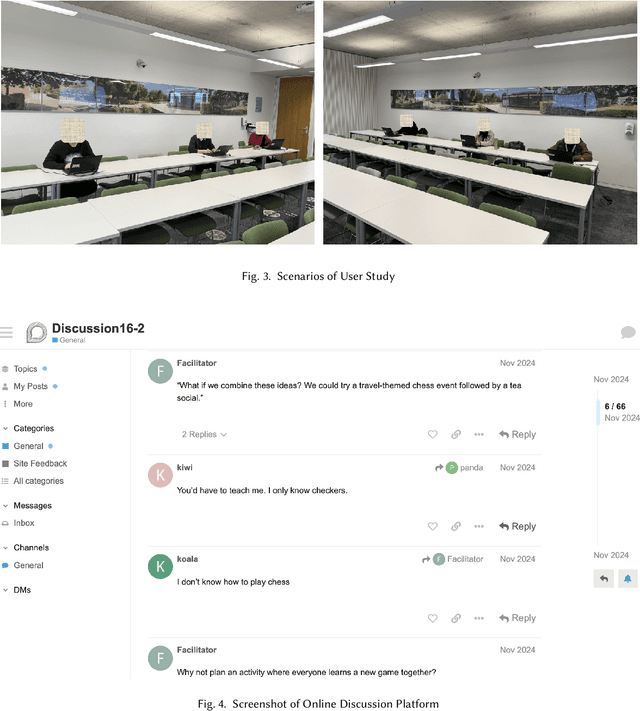
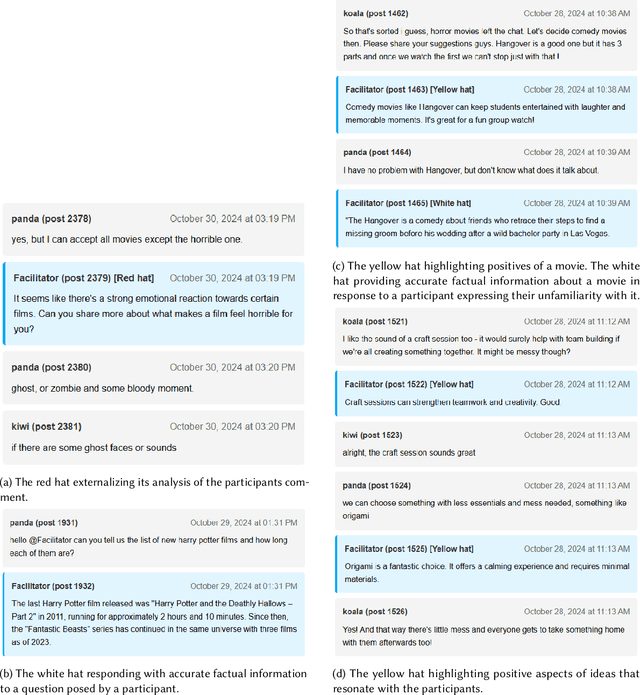
Consensus building is inherently challenging due to the diverse opinions held by stakeholders. Effective facilitation is crucial to support the consensus building process and enable efficient group decision making. However, the effectiveness of facilitation is often constrained by human factors such as limited experience and scalability. In this research, we propose a Parallel Thinking-based Facilitation Agent (PTFA) that facilitates online, text-based consensus building processes. The PTFA automatically collects textual posts and leverages large language models (LLMs) to perform all of the six distinct roles of the well-established Six Thinking Hats technique in parallel thinking. To illustrate the potential of PTFA, a pilot study was carried out and PTFA's ability in idea generation, emotional probing, and deeper analysis of ideas was demonstrated. Furthermore, a comprehensive dataset that contains not only the conversational content among the participants but also between the participants and the agent is constructed for future study.
Scalable Multi-Objective Reinforcement Learning with Fairness Guarantees using Lorenz Dominance
Nov 27, 2024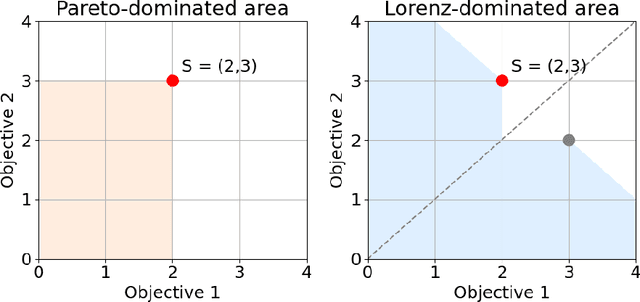

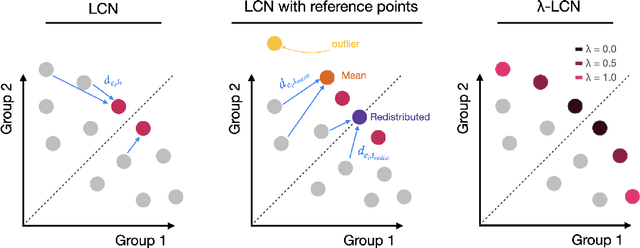
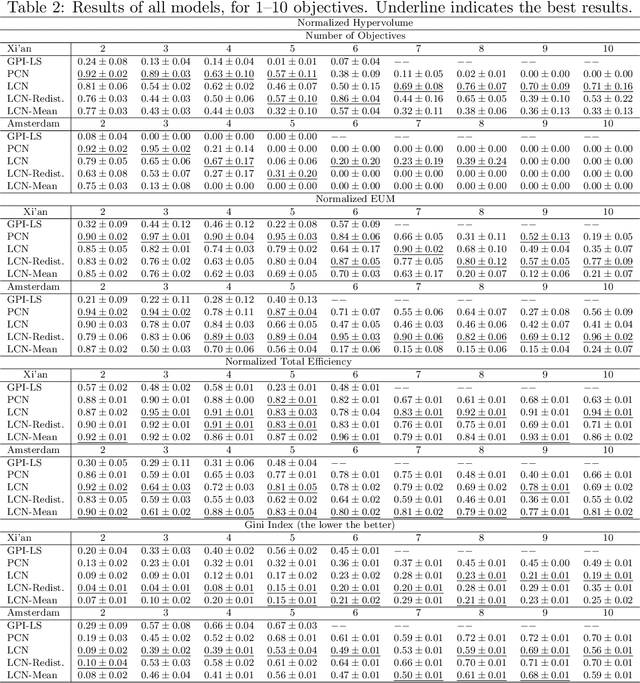
Multi-Objective Reinforcement Learning (MORL) aims to learn a set of policies that optimize trade-offs between multiple, often conflicting objectives. MORL is computationally more complex than single-objective RL, particularly as the number of objectives increases. Additionally, when objectives involve the preferences of agents or groups, ensuring fairness is socially desirable. This paper introduces a principled algorithm that incorporates fairness into MORL while improving scalability to many-objective problems. We propose using Lorenz dominance to identify policies with equitable reward distributions and introduce {\lambda}-Lorenz dominance to enable flexible fairness preferences. We release a new, large-scale real-world transport planning environment and demonstrate that our method encourages the discovery of fair policies, showing improved scalability in two large cities (Xi'an and Amsterdam). Our methods outperform common multi-objective approaches, particularly in high-dimensional objective spaces.