 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeFacilitating Automated Online Consensus Building through Parallel Thinking
Mar 16, 2025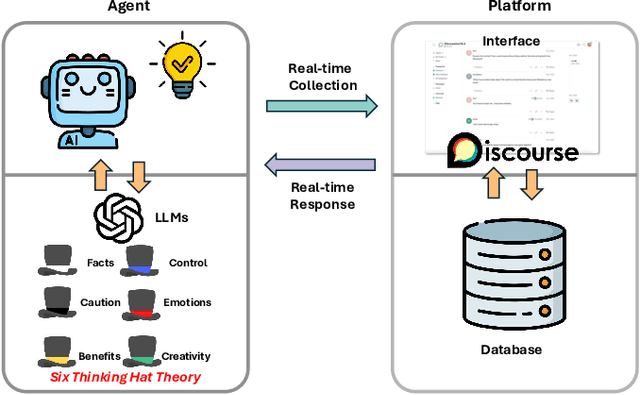

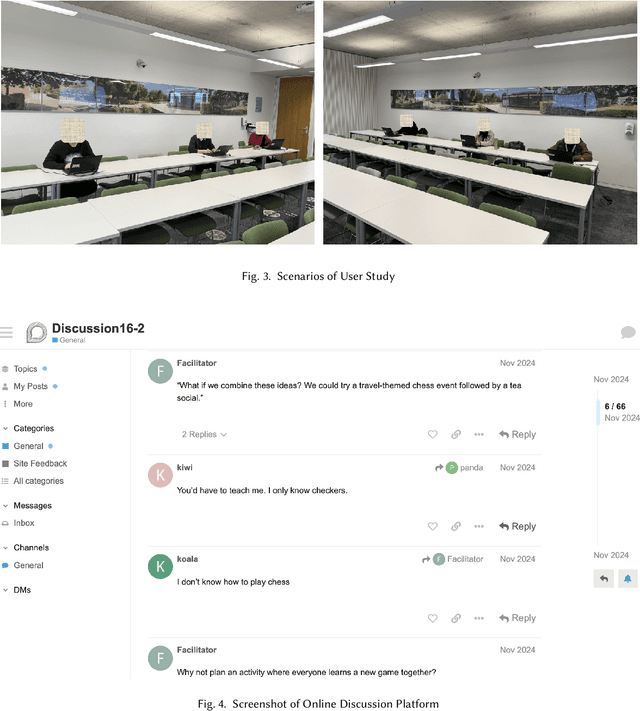
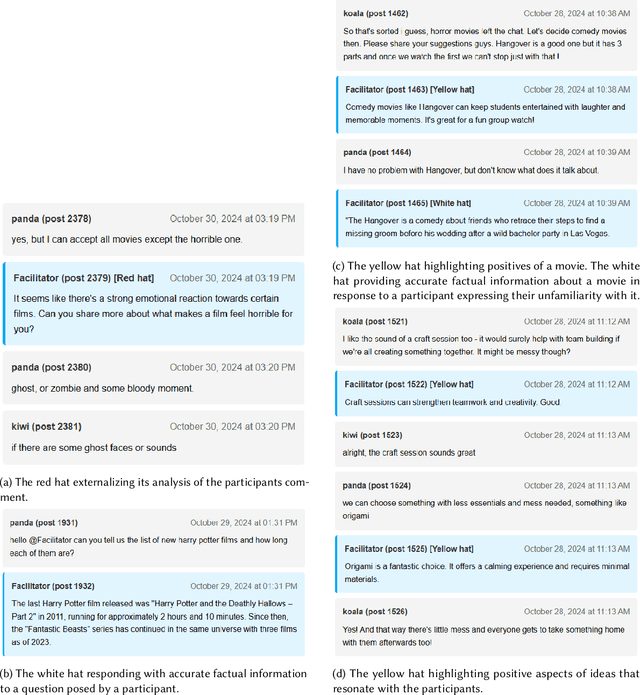
Consensus building is inherently challenging due to the diverse opinions held by stakeholders. Effective facilitation is crucial to support the consensus building process and enable efficient group decision making. However, the effectiveness of facilitation is often constrained by human factors such as limited experience and scalability. In this research, we propose a Parallel Thinking-based Facilitation Agent (PTFA) that facilitates online, text-based consensus building processes. The PTFA automatically collects textual posts and leverages large language models (LLMs) to perform all of the six distinct roles of the well-established Six Thinking Hats technique in parallel thinking. To illustrate the potential of PTFA, a pilot study was carried out and PTFA's ability in idea generation, emotional probing, and deeper analysis of ideas was demonstrated. Furthermore, a comprehensive dataset that contains not only the conversational content among the participants but also between the participants and the agent is constructed for future study.
A Survey Forest Diagram : Gain a Divergent Insight View on a Specific Research Topic
Jul 24, 2024With the exponential growth in the number of papers and the trend of AI research, the use of Generative AI for information retrieval and question-answering has become popular for conducting research surveys. However, novice researchers unfamiliar with a particular field may not significantly improve their efficiency in interacting with Generative AI because they have not developed divergent thinking in that field. This study aims to develop an in-depth Survey Forest Diagram that guides novice researchers in divergent thinking about the research topic by indicating the citation clues among multiple papers, to help expand the survey perspective for novice researchers.
Hierarchical Tree-structured Knowledge Graph For Academic Insight Survey
Feb 07, 2024Research surveys have always posed a challenge for beginner researchers who lack of research training. These researchers struggle to understand the directions within their research topic, and the discovery of new research findings within a short time. One way to provide intuitive assistance to beginner researchers is by offering relevant knowledge graphs(KG) and recommending related academic papers. However, existing navigation knowledge graphs primarily rely on keywords in the research field and often fail to present the logical hierarchy among multiple related papers clearly. Moreover, most recommendation systems for academic papers simply rely on high text similarity, which can leave researchers confused as to why a particular article is being recommended. They may lack of grasp important information about the insight connection between "Issue resolved" and "Issue finding" that they hope to obtain. To address these issues, this study aims to support research insight surveys for beginner researchers by establishing a hierarchical tree-structured knowledge graph that reflects the inheritance insight of research topics and the relevance insight among the academic papers.
Object Recognition from Scientific Document based on Compartment Refinement Framework
Dec 15, 2023With the rapid development of the internet in the past decade, it has become increasingly important to extract valuable information from vast resources efficiently, which is crucial for establishing a comprehensive digital ecosystem, particularly in the context of research surveys and comprehension. The foundation of these tasks focuses on accurate extraction and deep mining of data from scientific documents, which are essential for building a robust data infrastructure. However, parsing raw data or extracting data from complex scientific documents have been ongoing challenges. Current data extraction methods for scientific documents typically use rule-based (RB) or machine learning (ML) approaches. However, using rule-based methods can incur high coding costs for articles with intricate typesetting. Conversely, relying solely on machine learning methods necessitates annotation work for complex content types within the scientific document, which can be costly. Additionally, few studies have thoroughly defined and explored the hierarchical layout within scientific documents. The lack of a comprehensive definition of the internal structure and elements of the documents indirectly impacts the accuracy of text classification and object recognition tasks. From the perspective of analyzing the standard layout and typesetting used in the specified publication, we propose a new document layout analysis framework called CTBR(Compartment & Text Blocks Refinement). Firstly, we define scientific documents into hierarchical divisions: base domain, compartment, and text blocks. Next, we conduct an in-depth exploration and classification of the meanings of text blocks. Finally, we utilize the results of text block classification to implement object recognition within scientific documents based on rule-based compartment segmentation.
A Framework For Refining Text Classification and Object Recognition from Academic Articles
May 31, 2023With the widespread use of the internet, it has become increasingly crucial to extract specific information from vast amounts of academic articles efficiently. Data mining techniques are generally employed to solve this issue. However, data mining for academic articles is challenging since it requires automatically extracting specific patterns in complex and unstructured layout documents. Current data mining methods for academic articles employ rule-based(RB) or machine learning(ML) approaches. However, using rule-based methods incurs a high coding cost for complex typesetting articles. On the other hand, simply using machine learning methods requires annotation work for complex content types within the paper, which can be costly. Furthermore, only using machine learning can lead to cases where patterns easily recognized by rule-based methods are mistakenly extracted. To overcome these issues, from the perspective of analyzing the standard layout and typesetting used in the specified publication, we emphasize implementing specific methods for specific characteristics in academic articles. We have developed a novel Text Block Refinement Framework (TBRF), a machine learning and rule-based scheme hybrid. We used the well-known ACL proceeding articles as experimental data for the validation experiment. The experiment shows that our approach achieved over 95% classification accuracy and 90% detection accuracy for tables and figures.