 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeAdaWeather: Adaptively Mixing Probabilistic Weather Forecasts with Logarithmic Regret
Jun 01, 2026Recent advances in machine learning have produced probabilistic weather forecasting models comparable to state-of-the-art numerical weather predictors. But no model consistently dominates spatio-temporally, and relative performance is highly context-dependent. This motivates adaptive methods for combining multiple forecasts to obtain improvements and robustness. While combined forecasts have been proposed in the literature, these are achieved either through supervised learning or through prediction with expert advice methods. We introduce AdaWeather, an adaptive framework that combines many probabilistic forecasts using both machine learning as well as mixture of experts to arrive at a unified improved probabilistic forecast. While traditional expert methods develop the regret bounds with respect to the best single expert in hindsight, we extend the algorithm and analysis to show our method has logarithmic regret compared to the best static mixture of experts in hindsight. Empirically, we focus on forecasting temperature, and observe improvements over existing methods.
Generating DDPM-based Samples from Tilted Distributions
Apr 03, 2026Given $n$ independent samples from a $d$-dimensional probability distribution, our aim is to generate diffusion-based samples from a distribution obtained by tilting the original, where the degree of tilt is parametrized by $θ\in \mathbb{R}^d$. We define a plug-in estimator and show that it is minimax-optimal. We develop Wasserstein bounds between the distribution of the plug-in estimator and the true distribution as a function of $n$ and $θ$, illustrating regimes where the output and the desired true distribution are close. Further, under some assumptions, we prove the TV-accuracy of running Diffusion on these tilted samples. Our theoretical results are supported by extensive simulations. Applications of our work include finance, weather and climate modelling, and many other domains, where the aim may be to generate samples from a tilted distribution that satisfies practically motivated moment constraints.
Fundamental limits for weighted empirical approximations of tilted distributions
Dec 30, 2025Consider the task of generating samples from a tilted distribution of a random vector whose underlying distribution is unknown, but samples from it are available. This finds applications in fields such as finance and climate science, and in rare event simulation. In this article, we discuss the asymptotic efficiency of a self-normalized importance sampler of the tilted distribution. We provide a sharp characterization of its accuracy, given the number of samples and the degree of tilt. Our findings reveal a surprising dichotomy: while the number of samples needed to accurately tilt a bounded random vector increases polynomially in the tilt amount, it increases at a super polynomial rate for unbounded distributions.
Tight Lower Bounds and Improved Convergence in Performative Prediction
Dec 04, 2024Performative prediction is a framework accounting for the shift in the data distribution induced by the prediction of a model deployed in the real world. Ensuring rapid convergence to a stable solution where the data distribution remains the same after the model deployment is crucial, especially in evolving environments. This paper extends the Repeated Risk Minimization (RRM) framework by utilizing historical datasets from previous retraining snapshots, yielding a class of algorithms that we call Affine Risk Minimizers and enabling convergence to a performatively stable point for a broader class of problems. We introduce a new upper bound for methods that use only the final iteration of the dataset and prove for the first time the tightness of both this new bound and the previous existing bounds within the same regime. We also prove that utilizing historical datasets can surpass the lower bound for last iterate RRM, and empirically observe faster convergence to the stable point on various performative prediction benchmarks. We offer at the same time the first lower bound analysis for RRM within the class of Affine Risk Minimizers, quantifying the potential improvements in convergence speed that could be achieved with other variants in our framework.
Pairing Analogy-Augmented Generation with Procedural Memory for Procedural Q&A
Sep 02, 2024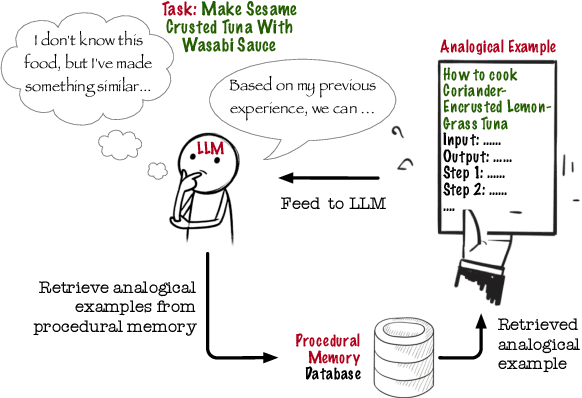
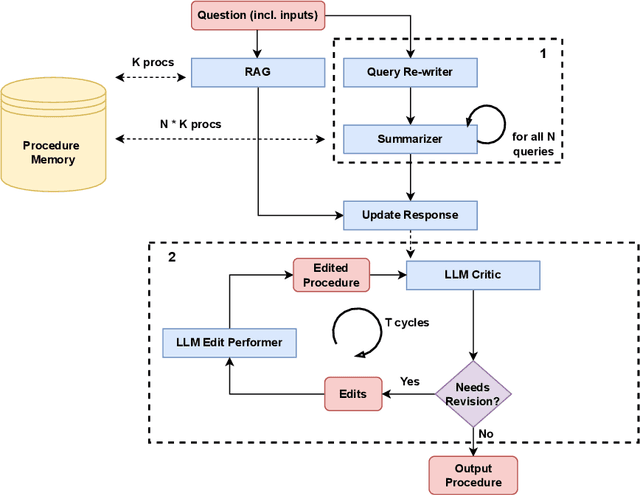
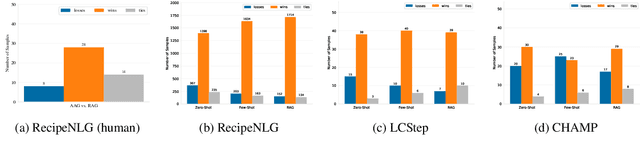
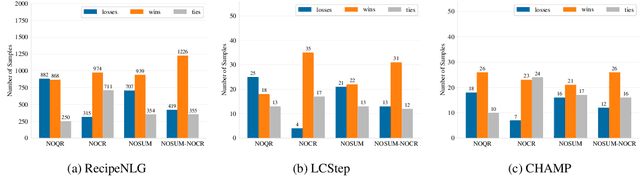
While LLMs in the RAG paradigm have shown remarkable performance on a variety of tasks, they still under-perform on unseen domains, especially on complex tasks like procedural question answering. In this work, we introduce a novel formalism and structure for manipulating text-based procedures. Based on this formalism, we further present a novel dataset called LCStep, scraped from the LangChain Python docs. Moreover, we extend the traditional RAG system to propose a novel system called analogy-augmented generation (AAG), that draws inspiration from human analogical reasoning and ability to assimilate past experiences to solve unseen problems. The proposed method uses a frozen language model with a custom procedure memory store to adapt to specialized knowledge. We demonstrate that AAG outperforms few-shot and RAG baselines on LCStep, RecipeNLG, and CHAMP datasets under a pairwise LLM-based evaluation, corroborated by human evaluation in the case of RecipeNLG.
Learning Disentangled Representation in Object-Centric Models for Visual Dynamics Prediction via Transformers
Jul 03, 2024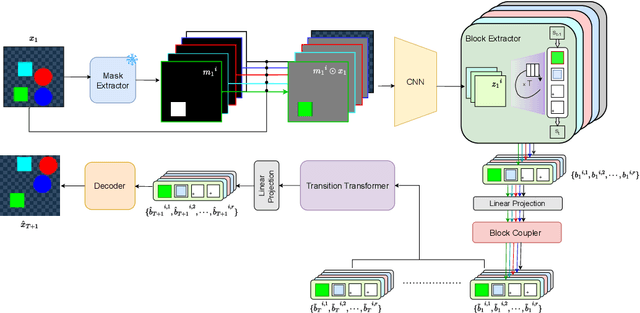
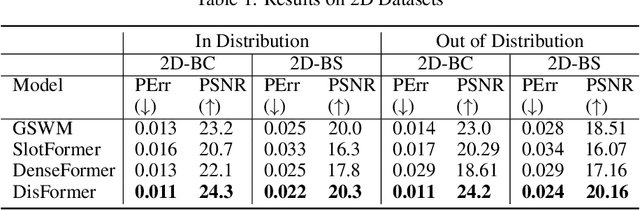
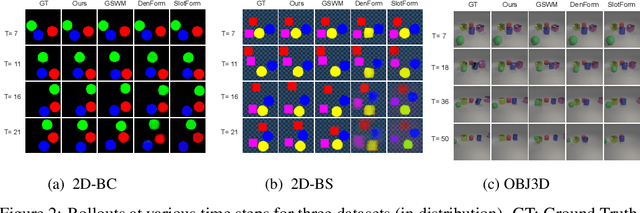
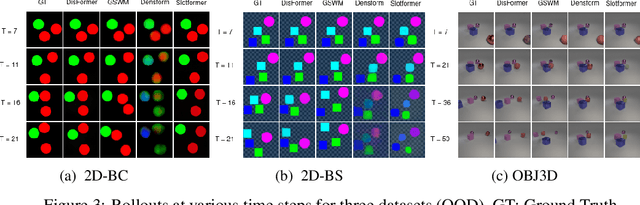
Recent work has shown that object-centric representations can greatly help improve the accuracy of learning dynamics while also bringing interpretability. In this work, we take this idea one step further, ask the following question: "can learning disentangled representation further improve the accuracy of visual dynamics prediction in object-centric models?" While there has been some attempt to learn such disentangled representations for the case of static images \citep{nsb}, to the best of our knowledge, ours is the first work which tries to do this in a general setting for video, without making any specific assumptions about the kind of attributes that an object might have. The key building block of our architecture is the notion of a {\em block}, where several blocks together constitute an object. Each block is represented as a linear combination of a given number of learnable concept vectors, which is iteratively refined during the learning process. The blocks in our model are discovered in an unsupervised manner, by attending over object masks, in a style similar to discovery of slots \citep{slot_attention}, for learning a dense object-centric representation. We employ self-attention via transformers over the discovered blocks to predict the next state resulting in discovery of visual dynamics. We perform a series of experiments on several benchmark 2-D, and 3-D datasets demonstrating that our architecture (1) can discover semantically meaningful blocks (2) help improve accuracy of dynamics prediction compared to SOTA object-centric models (3) perform significantly better in OOD setting where the specific attribute combinations are not seen earlier during training. Our experiments highlight the importance discovery of disentangled representation for visual dynamics prediction.
Towards an Interpretable Latent Space in Structured Models for Video Prediction
Jul 16, 2021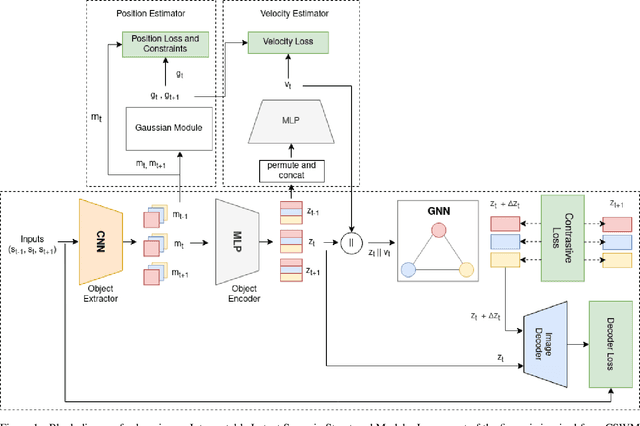
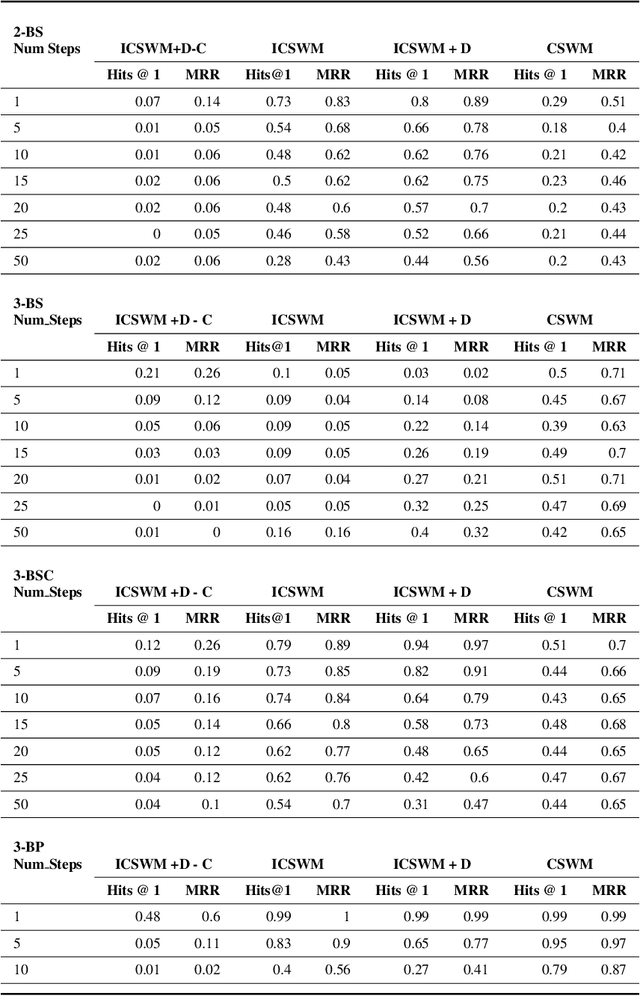
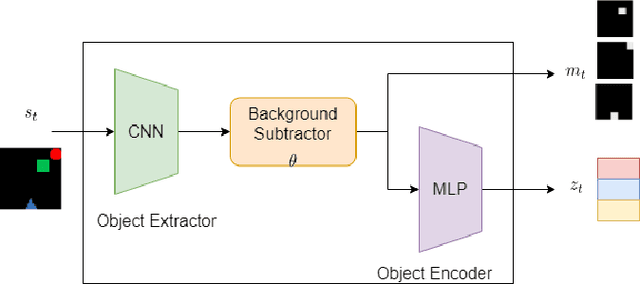
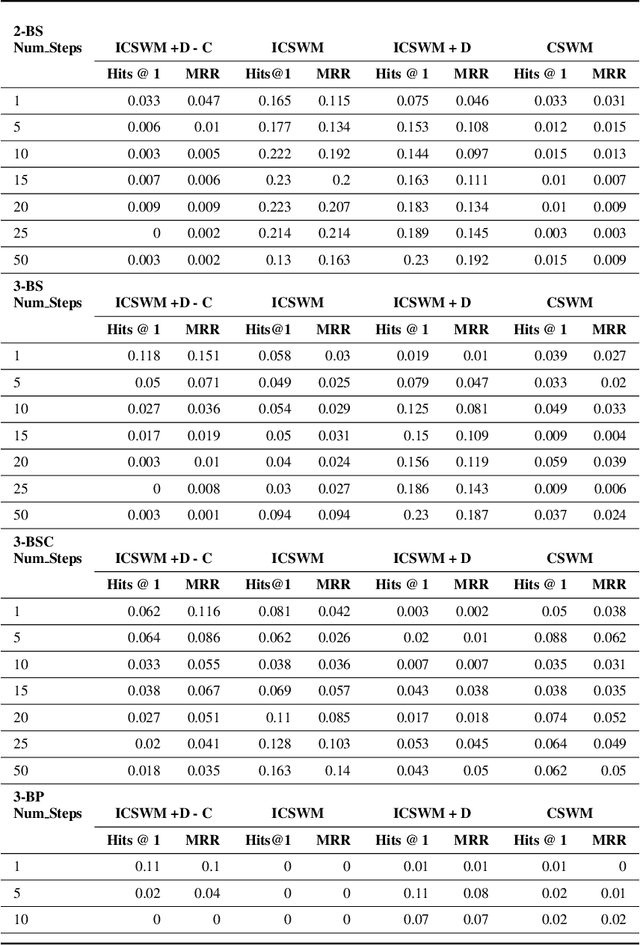
We focus on the task of future frame prediction in video governed by underlying physical dynamics. We work with models which are object-centric, i.e., explicitly work with object representations, and propagate a loss in the latent space. Specifically, our research builds on recent work by Kipf et al. \cite{kipf&al20}, which predicts the next state via contrastive learning of object interactions in a latent space using a Graph Neural Network. We argue that injecting explicit inductive bias in the model, in form of general physical laws, can help not only make the model more interpretable, but also improve the overall prediction of model. As a natural by-product, our model can learn feature maps which closely resemble actual object positions in the image, without having any explicit supervision about the object positions at the training time. In comparison with earlier works \cite{jaques&al20}, which assume a complete knowledge of the dynamics governing the motion in the form of a physics engine, we rely only on the knowledge of general physical laws, such as, world consists of objects, which have position and velocity. We propose an additional decoder based loss in the pixel space, imposed in a curriculum manner, to further refine the latent space predictions. Experiments in multiple different settings demonstrate that while Kipf et al. model is effective at capturing object interactions, our model can be significantly more effective at localising objects, resulting in improved performance in 3 out of 4 domains that we experiment with. Additionally, our model can learn highly intrepretable feature maps, resembling actual object positions.