 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeLearning Disentangled Representation in Object-Centric Models for Visual Dynamics Prediction via Transformers
Jul 03, 2024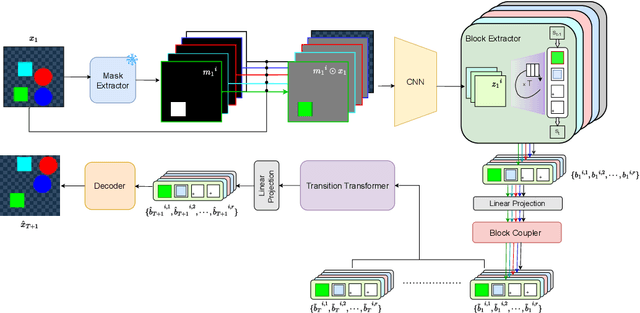
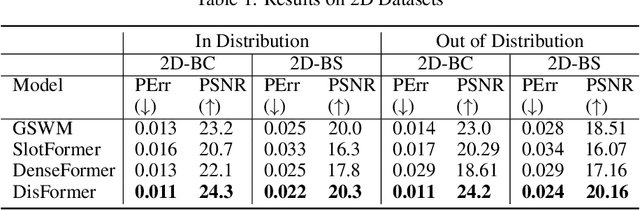
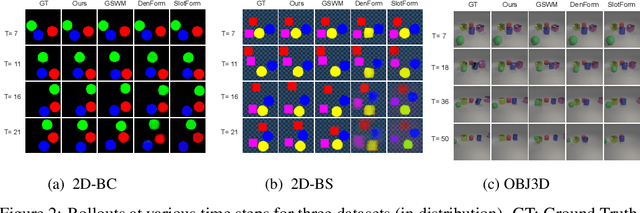
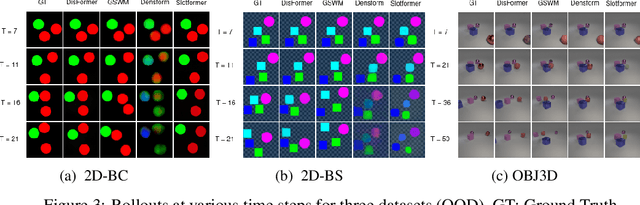
Recent work has shown that object-centric representations can greatly help improve the accuracy of learning dynamics while also bringing interpretability. In this work, we take this idea one step further, ask the following question: "can learning disentangled representation further improve the accuracy of visual dynamics prediction in object-centric models?" While there has been some attempt to learn such disentangled representations for the case of static images \citep{nsb}, to the best of our knowledge, ours is the first work which tries to do this in a general setting for video, without making any specific assumptions about the kind of attributes that an object might have. The key building block of our architecture is the notion of a {\em block}, where several blocks together constitute an object. Each block is represented as a linear combination of a given number of learnable concept vectors, which is iteratively refined during the learning process. The blocks in our model are discovered in an unsupervised manner, by attending over object masks, in a style similar to discovery of slots \citep{slot_attention}, for learning a dense object-centric representation. We employ self-attention via transformers over the discovered blocks to predict the next state resulting in discovery of visual dynamics. We perform a series of experiments on several benchmark 2-D, and 3-D datasets demonstrating that our architecture (1) can discover semantically meaningful blocks (2) help improve accuracy of dynamics prediction compared to SOTA object-centric models (3) perform significantly better in OOD setting where the specific attribute combinations are not seen earlier during training. Our experiments highlight the importance discovery of disentangled representation for visual dynamics prediction.