 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgePerformance of a Deep Learning-Based Segmentation Model for Pancreatic Tumors on Public Endoscopic Ultrasound Datasets
Jan 09, 2026Background: Pancreatic cancer is one of the most aggressive cancers, with poor survival rates. Endoscopic ultrasound (EUS) is a key diagnostic modality, but its effectiveness is constrained by operator subjectivity. This study evaluates a Vision Transformer-based deep learning segmentation model for pancreatic tumors. Methods: A segmentation model using the USFM framework with a Vision Transformer backbone was trained and validated with 17,367 EUS images (from two public datasets) in 5-fold cross-validation. The model was tested on an independent dataset of 350 EUS images from another public dataset, manually segmented by radiologists. Preprocessing included grayscale conversion, cropping, and resizing to 512x512 pixels. Metrics included Dice similarity coefficient (DSC), intersection over union (IoU), sensitivity, specificity, and accuracy. Results: In 5-fold cross-validation, the model achieved a mean DSC of 0.651 +/- 0.738, IoU of 0.579 +/- 0.658, sensitivity of 69.8%, specificity of 98.8%, and accuracy of 97.5%. For the external validation set, the model achieved a DSC of 0.657 (95% CI: 0.634-0.769), IoU of 0.614 (95% CI: 0.590-0.689), sensitivity of 71.8%, and specificity of 97.7%. Results were consistent, but 9.7% of cases exhibited erroneous multiple predictions. Conclusions: The Vision Transformer-based model demonstrated strong performance for pancreatic tumor segmentation in EUS images. However, dataset heterogeneity and limited external validation highlight the need for further refinement, standardization, and prospective studies.
Evolving Excellence: Automated Optimization of LLM-based Agents
Dec 09, 2025Agentic AI systems built on large language models (LLMs) offer significant potential for automating complex workflows, from software development to customer support. However, LLM agents often underperform due to suboptimal configurations; poorly tuned prompts, tool descriptions, and parameters that typically require weeks of manual refinement. Existing optimization methods either are too complex for general use or treat components in isolation, missing critical interdependencies. We present ARTEMIS, a no-code evolutionary optimization platform that jointly optimizes agent configurations through semantically-aware genetic operators. Given only a benchmark script and natural language goals, ARTEMIS automatically discovers configurable components, extracts performance signals from execution logs, and evolves configurations without requiring architectural modifications. We evaluate ARTEMIS on four representative agent systems: the \emph{ALE Agent} for competitive programming on AtCoder Heuristic Contest, achieving a \textbf{$13.6\%$ improvement} in acceptance rate; the \emph{Mini-SWE Agent} for code optimization on SWE-Perf, with a statistically significant \textbf{10.1\% performance gain}; and the \emph{CrewAI Agent} for cost and mathematical reasoning on Math Odyssey, achieving a statistically significant \textbf{$36.9\%$ reduction} in the number of tokens required for evaluation. We also evaluate the \emph{MathTales-Teacher Agent} powered by a smaller open-source model (Qwen2.5-7B) on GSM8K primary-level mathematics problems, achieving a \textbf{22\% accuracy improvement} and demonstrating that ARTEMIS can optimize agents based on both commercial and local models.
Self-Adaptive Graph Mixture of Models
Nov 17, 2025Graph Neural Networks (GNNs) have emerged as powerful tools for learning over graph-structured data, yet recent studies have shown that their performance gains are beginning to plateau. In many cases, well-established models such as GCN and GAT, when appropriately tuned, can match or even exceed the performance of more complex, state-of-the-art architectures. This trend highlights a key limitation in the current landscape: the difficulty of selecting the most suitable model for a given graph task or dataset. To address this, we propose Self-Adaptive Graph Mixture of Models (SAGMM), a modular and practical framework that learns to automatically select and combine the most appropriate GNN models from a diverse pool of architectures. Unlike prior mixture-of-experts approaches that rely on variations of a single base model, SAGMM leverages architectural diversity and a topology-aware attention gating mechanism to adaptively assign experts to each node based on the structure of the input graph. To improve efficiency, SAGMM includes a pruning mechanism that reduces the number of active experts during training and inference without compromising performance. We also explore a training-efficient variant in which expert models are pretrained and frozen, and only the gating and task-specific layers are trained. We evaluate SAGMM on 16 benchmark datasets covering node classification, graph classification, regression, and link prediction tasks, and demonstrate that it consistently outperforms or matches leading GNN baselines and prior mixture-based methods, offering a robust and adaptive solution for real-world graph learning.
Adaptive LLM Routing under Budget Constraints
Aug 28, 2025Large Language Models (LLMs) have revolutionized natural language processing, but their varying capabilities and costs pose challenges in practical applications. LLM routing addresses this by dynamically selecting the most suitable LLM for each query/task. Previous approaches treat this as a supervised learning problem, assuming complete knowledge of optimal query-LLM pairings. However, real-world scenarios lack such comprehensive mappings and face evolving user queries. We thus propose to study LLM routing as a contextual bandit problem, enabling adaptive decision-making using bandit feedback without requiring exhaustive inference across all LLMs for all queries (in contrast to supervised routing). To address this problem, we develop a shared embedding space for queries and LLMs, where query and LLM embeddings are aligned to reflect their affinity. This space is initially learned from offline human preference data and refined through online bandit feedback. We instantiate this idea through Preference-prior Informed Linucb fOr adaptive rouTing (PILOT), a novel extension of LinUCB. To handle diverse user budgets for model routing, we introduce an online cost policy modeled as a multi-choice knapsack problem, ensuring resource-efficient routing.
Uncertainty in Supply Chain Digital Twins: A Quantum-Classical Hybrid Approach
Nov 15, 2024
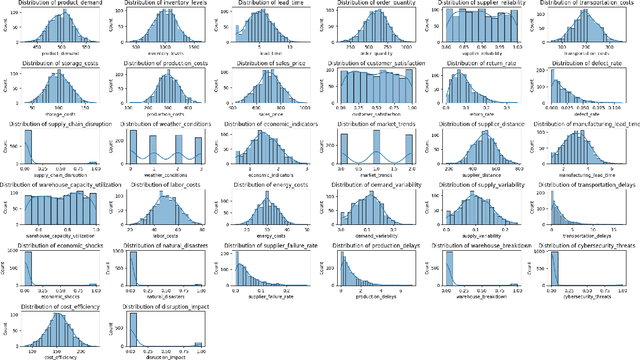


This study investigates uncertainty quantification (UQ) using quantum-classical hybrid machine learning (ML) models for applications in complex and dynamic fields, such as attaining resiliency in supply chain digital twins and financial risk assessment. Although quantum feature transformations have been integrated into ML models for complex data tasks, a gap exists in determining their impact on UQ within their hybrid architectures (quantum-classical approach). This work applies existing UQ techniques for different models within a hybrid framework, examining how quantum feature transformation affects uncertainty propagation. Increasing qubits from 4 to 16 shows varied model responsiveness to outlier detection (OD) samples, which is a critical factor for resilient decision-making in dynamic environments. This work shows how quantum computing techniques can transform data features for UQ, particularly when combined with traditional methods.
Learning Disentangled Representation in Object-Centric Models for Visual Dynamics Prediction via Transformers
Jul 03, 2024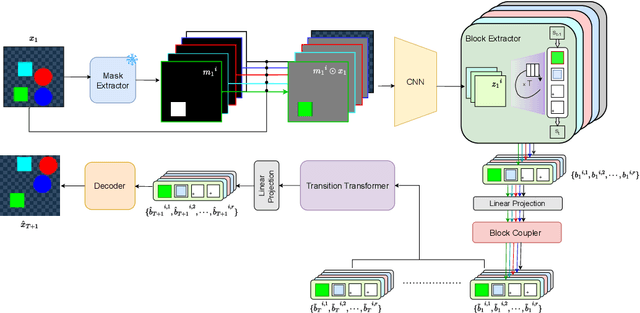
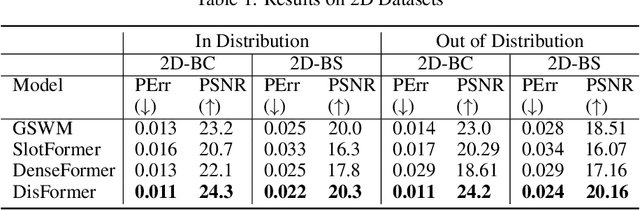
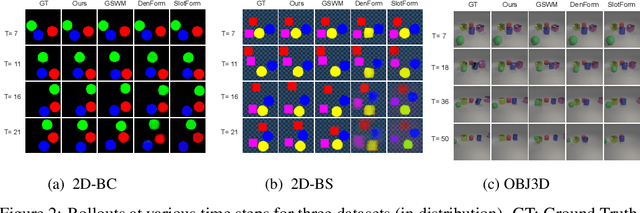
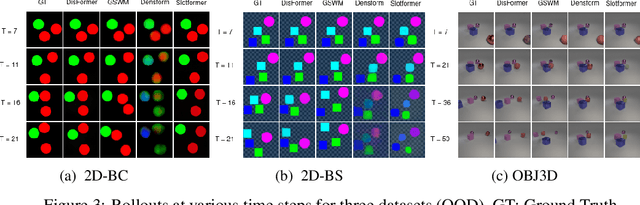
Recent work has shown that object-centric representations can greatly help improve the accuracy of learning dynamics while also bringing interpretability. In this work, we take this idea one step further, ask the following question: "can learning disentangled representation further improve the accuracy of visual dynamics prediction in object-centric models?" While there has been some attempt to learn such disentangled representations for the case of static images \citep{nsb}, to the best of our knowledge, ours is the first work which tries to do this in a general setting for video, without making any specific assumptions about the kind of attributes that an object might have. The key building block of our architecture is the notion of a {\em block}, where several blocks together constitute an object. Each block is represented as a linear combination of a given number of learnable concept vectors, which is iteratively refined during the learning process. The blocks in our model are discovered in an unsupervised manner, by attending over object masks, in a style similar to discovery of slots \citep{slot_attention}, for learning a dense object-centric representation. We employ self-attention via transformers over the discovered blocks to predict the next state resulting in discovery of visual dynamics. We perform a series of experiments on several benchmark 2-D, and 3-D datasets demonstrating that our architecture (1) can discover semantically meaningful blocks (2) help improve accuracy of dynamics prediction compared to SOTA object-centric models (3) perform significantly better in OOD setting where the specific attribute combinations are not seen earlier during training. Our experiments highlight the importance discovery of disentangled representation for visual dynamics prediction.
Artifact-Tolerant Clustering-Guided Contrastive Embedding Learning for Ophthalmic Images
Sep 02, 2022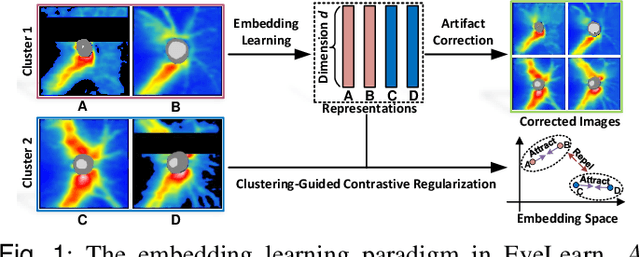
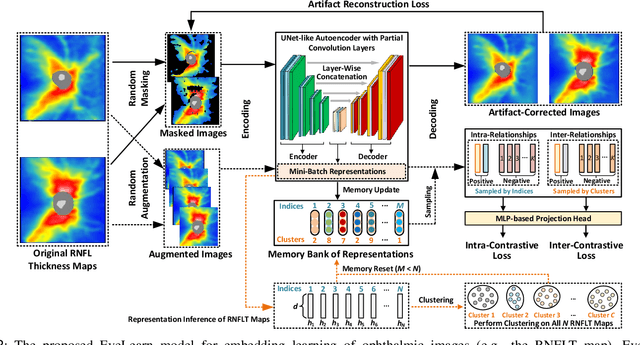
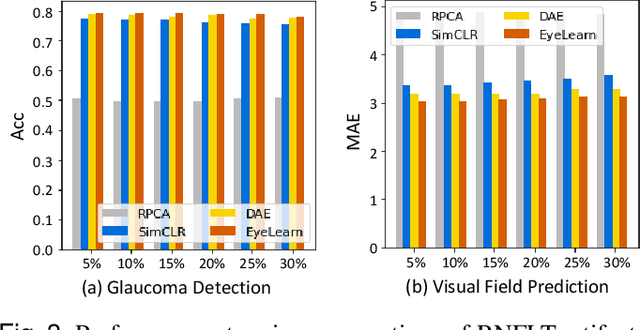
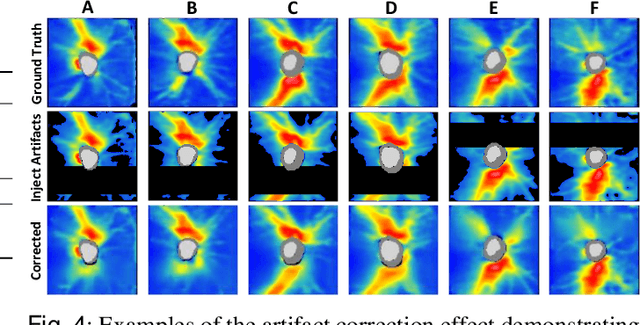
Ophthalmic images and derivatives such as the retinal nerve fiber layer (RNFL) thickness map are crucial for detecting and monitoring ophthalmic diseases (e.g., glaucoma). For computer-aided diagnosis of eye diseases, the key technique is to automatically extract meaningful features from ophthalmic images that can reveal the biomarkers (e.g., RNFL thinning patterns) linked to functional vision loss. However, representation learning from ophthalmic images that links structural retinal damage with human vision loss is non-trivial mostly due to large anatomical variations between patients. The task becomes even more challenging in the presence of image artifacts, which are common due to issues with image acquisition and automated segmentation. In this paper, we propose an artifact-tolerant unsupervised learning framework termed EyeLearn for learning representations of ophthalmic images. EyeLearn has an artifact correction module to learn representations that can best predict artifact-free ophthalmic images. In addition, EyeLearn adopts a clustering-guided contrastive learning strategy to explicitly capture the intra- and inter-image affinities. During training, images are dynamically organized in clusters to form contrastive samples in which images in the same or different clusters are encouraged to learn similar or dissimilar representations, respectively. To evaluate EyeLearn, we use the learned representations for visual field prediction and glaucoma detection using a real-world ophthalmic image dataset of glaucoma patients. Extensive experiments and comparisons with state-of-the-art methods verified the effectiveness of EyeLearn for learning optimal feature representations from ophthalmic images.
Deep Learning for Bias Detection: From Inception to Deployment
Oct 12, 2021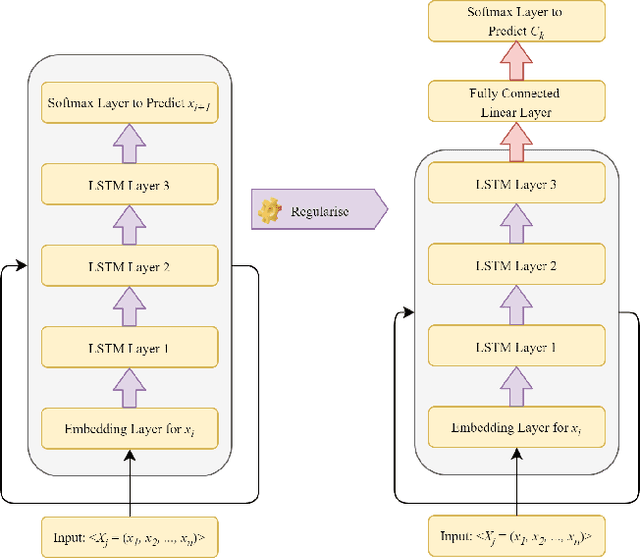

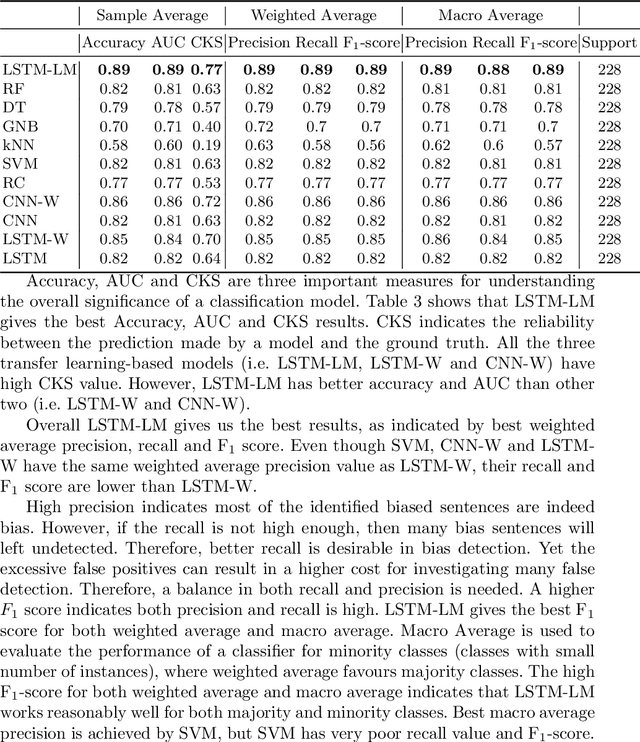
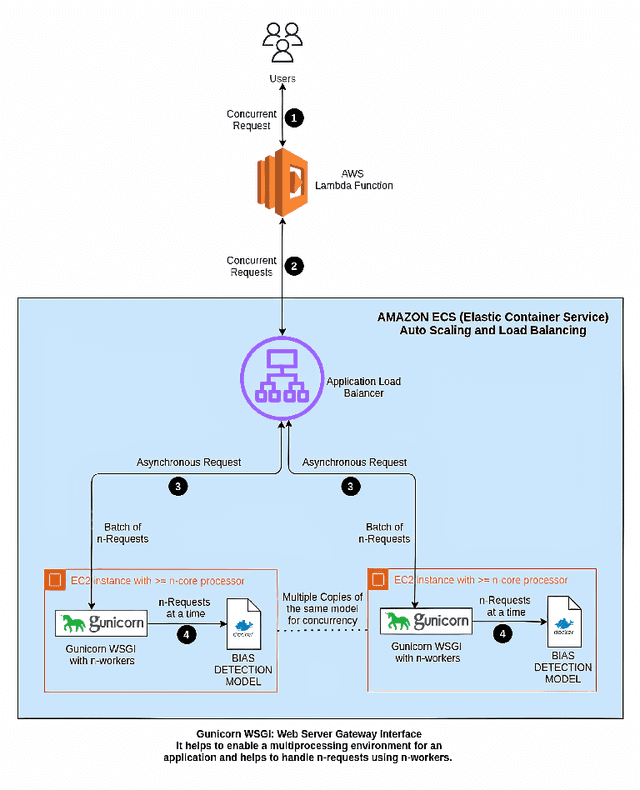
To create a more inclusive workplace, enterprises are actively investing in identifying and eliminating unconscious bias (e.g., gender, race, age, disability, elitism and religion) across their various functions. We propose a deep learning model with a transfer learning based language model to learn from manually tagged documents for automatically identifying bias in enterprise content. We first pretrain a deep learning-based language-model using Wikipedia, then fine tune the model with a large unlabelled data set related with various types of enterprise content. Finally, a linear layer followed by softmax layer is added at the end of the language model and the model is trained on a labelled bias dataset consisting of enterprise content. The trained model is thoroughly evaluated on independent datasets to ensure a general application. We present the proposed method and its deployment detail in a real-world application.
Towards an Interpretable Latent Space in Structured Models for Video Prediction
Jul 16, 2021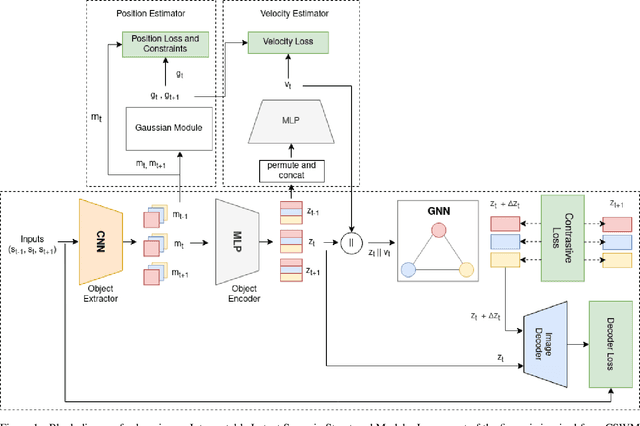
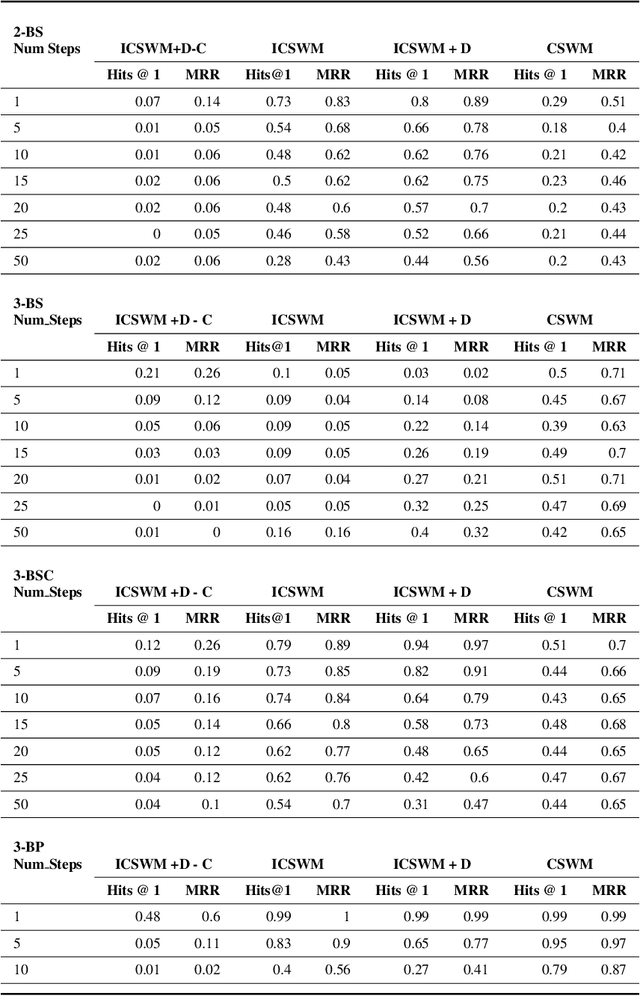
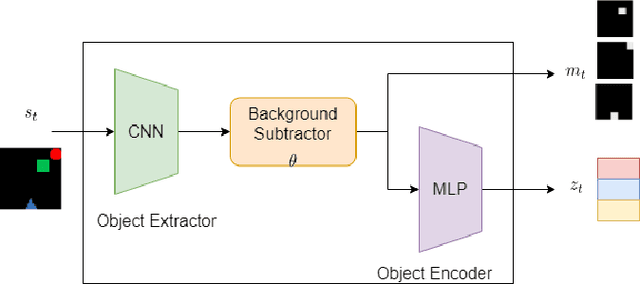
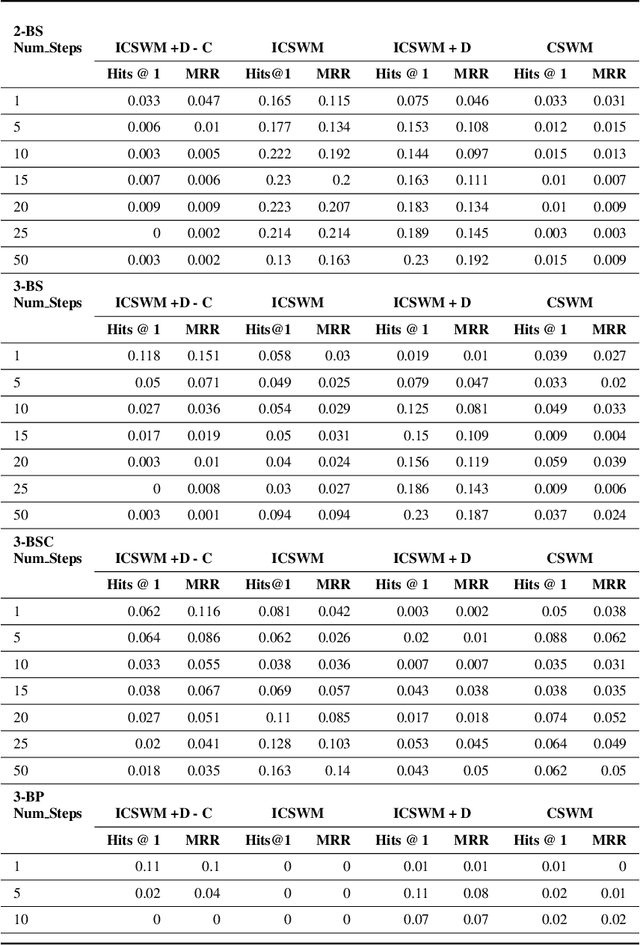
We focus on the task of future frame prediction in video governed by underlying physical dynamics. We work with models which are object-centric, i.e., explicitly work with object representations, and propagate a loss in the latent space. Specifically, our research builds on recent work by Kipf et al. \cite{kipf&al20}, which predicts the next state via contrastive learning of object interactions in a latent space using a Graph Neural Network. We argue that injecting explicit inductive bias in the model, in form of general physical laws, can help not only make the model more interpretable, but also improve the overall prediction of model. As a natural by-product, our model can learn feature maps which closely resemble actual object positions in the image, without having any explicit supervision about the object positions at the training time. In comparison with earlier works \cite{jaques&al20}, which assume a complete knowledge of the dynamics governing the motion in the form of a physics engine, we rely only on the knowledge of general physical laws, such as, world consists of objects, which have position and velocity. We propose an additional decoder based loss in the pixel space, imposed in a curriculum manner, to further refine the latent space predictions. Experiments in multiple different settings demonstrate that while Kipf et al. model is effective at capturing object interactions, our model can be significantly more effective at localising objects, resulting in improved performance in 3 out of 4 domains that we experiment with. Additionally, our model can learn highly intrepretable feature maps, resembling actual object positions.
COVID-19 detection using Residual Attention Network an Artificial Intelligence approach
Jun 26, 2020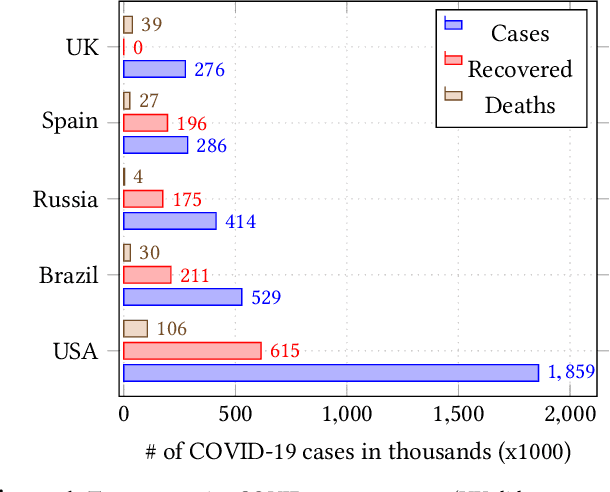
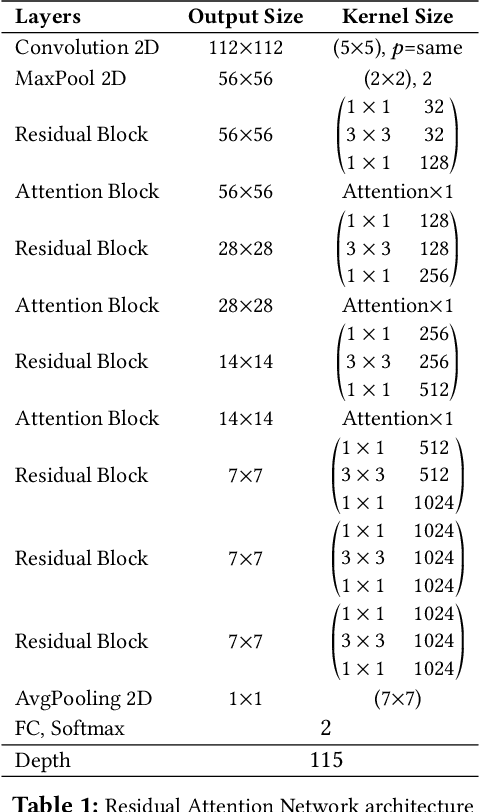
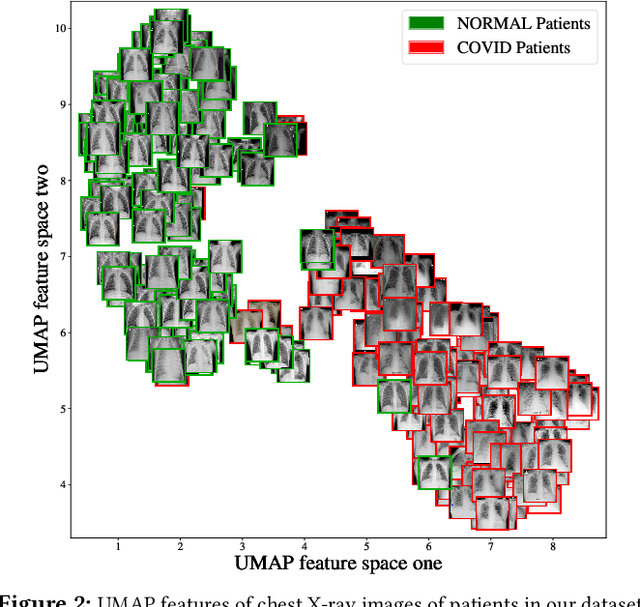
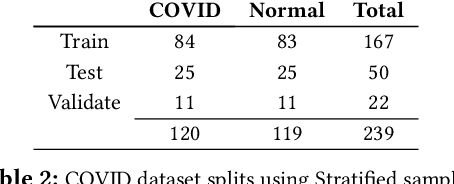
Coronavirus Disease 2019 (COVID-19) is caused by the severe acute respiratory syndrome coronavirus 2 virus (SARS-CoV-2). The virus transmits rapidly, it has a basic reproductive number ($R_0$) of $2.2-2.7$. In March, 2020 the World Health Organization declared the COVID-19 outbreak a pandemic. Effective testing for COVID-19 is crucial to controlling the outbreak since infected patients can be quarantined. But the demand for testing outstrips the availability of test kits that use Reverse Transcription Polymerase Chain Reaction (RT-PCR). In this paper, we present a technique to detect COVID-19 using Artificial Intelligence. Our technique takes only a few seconds to detect the presence of the virus in a patient. We collected a dataset of chest X-ray images and trained several popular deep convolution neural network-based models (VGG, MobileNet, Xception, DenseNet, InceptionResNet) to classify chest X-rays. Unsatisfied with these models we then designed and built a Residual Attention Network that was able to detect COVID-19 with a testing accuracy of 98\% and a validation accuracy of 100\%. Feature maps of our model show which areas within a chest X-ray are important for classification. Our work can help to increase the adaptation of AI-assisted applications in clinical practice.