 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeTowards an Interpretable Latent Space in Structured Models for Video Prediction
Paper and Code
Jul 16, 2021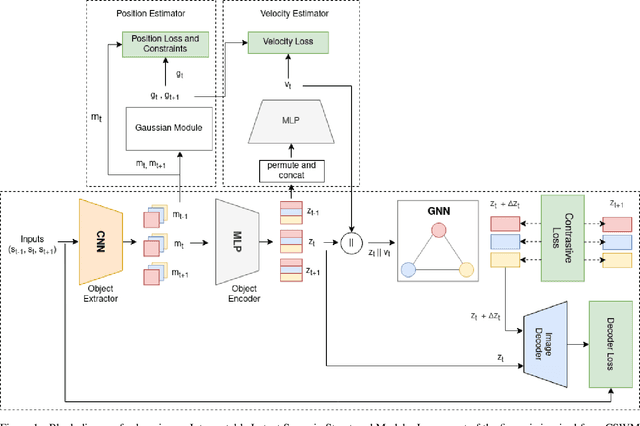
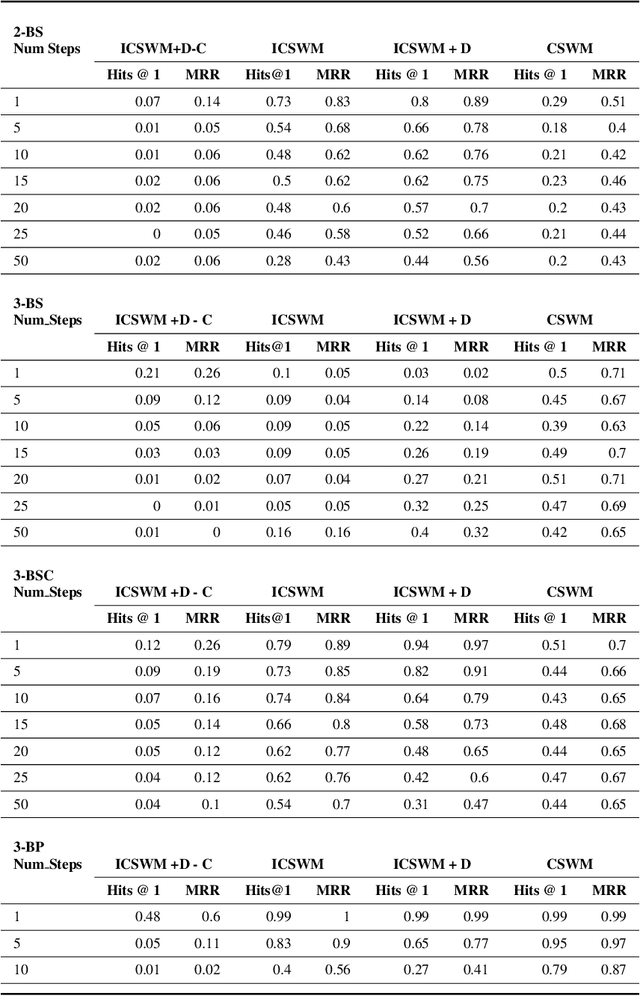
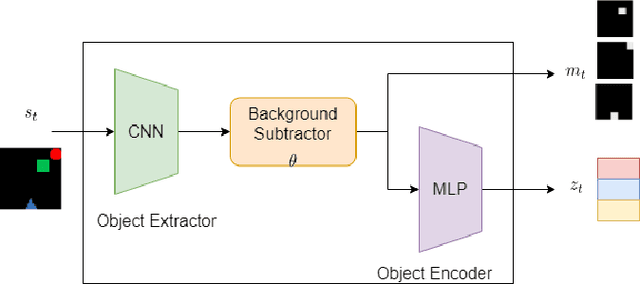
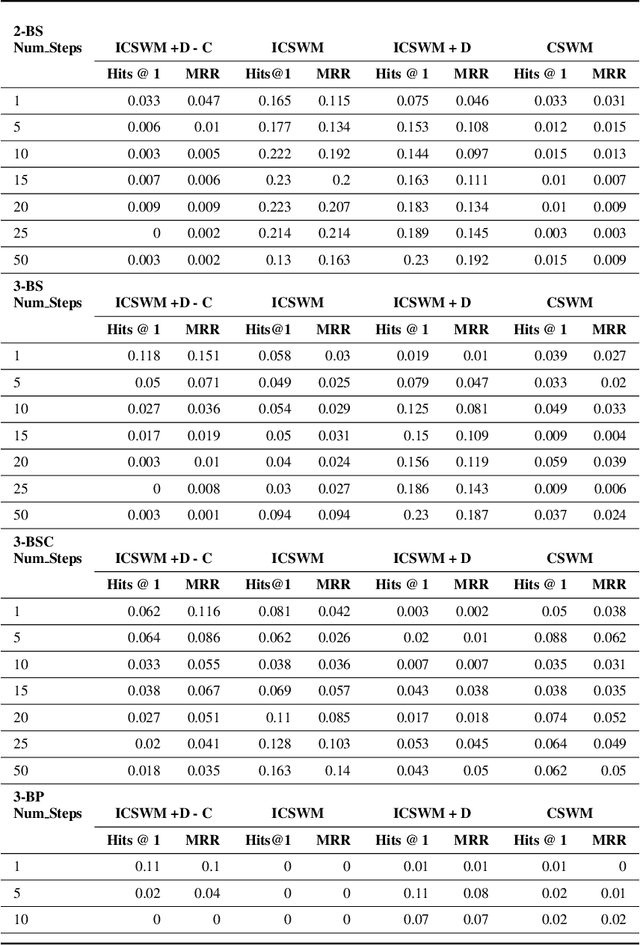
We focus on the task of future frame prediction in video governed by underlying physical dynamics. We work with models which are object-centric, i.e., explicitly work with object representations, and propagate a loss in the latent space. Specifically, our research builds on recent work by Kipf et al. \cite{kipf&al20}, which predicts the next state via contrastive learning of object interactions in a latent space using a Graph Neural Network. We argue that injecting explicit inductive bias in the model, in form of general physical laws, can help not only make the model more interpretable, but also improve the overall prediction of model. As a natural by-product, our model can learn feature maps which closely resemble actual object positions in the image, without having any explicit supervision about the object positions at the training time. In comparison with earlier works \cite{jaques&al20}, which assume a complete knowledge of the dynamics governing the motion in the form of a physics engine, we rely only on the knowledge of general physical laws, such as, world consists of objects, which have position and velocity. We propose an additional decoder based loss in the pixel space, imposed in a curriculum manner, to further refine the latent space predictions. Experiments in multiple different settings demonstrate that while Kipf et al. model is effective at capturing object interactions, our model can be significantly more effective at localising objects, resulting in improved performance in 3 out of 4 domains that we experiment with. Additionally, our model can learn highly intrepretable feature maps, resembling actual object positions.