 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeAdaptive LLM Routing under Budget Constraints
Aug 28, 2025Large Language Models (LLMs) have revolutionized natural language processing, but their varying capabilities and costs pose challenges in practical applications. LLM routing addresses this by dynamically selecting the most suitable LLM for each query/task. Previous approaches treat this as a supervised learning problem, assuming complete knowledge of optimal query-LLM pairings. However, real-world scenarios lack such comprehensive mappings and face evolving user queries. We thus propose to study LLM routing as a contextual bandit problem, enabling adaptive decision-making using bandit feedback without requiring exhaustive inference across all LLMs for all queries (in contrast to supervised routing). To address this problem, we develop a shared embedding space for queries and LLMs, where query and LLM embeddings are aligned to reflect their affinity. This space is initially learned from offline human preference data and refined through online bandit feedback. We instantiate this idea through Preference-prior Informed Linucb fOr adaptive rouTing (PILOT), a novel extension of LinUCB. To handle diverse user budgets for model routing, we introduce an online cost policy modeled as a multi-choice knapsack problem, ensuring resource-efficient routing.
Interpretable Model Drift Detection
Mar 09, 2025Data in the real world often has an evolving distribution. Thus, machine learning models trained on such data get outdated over time. This phenomenon is called model drift. Knowledge of this drift serves two purposes: (i) Retain an accurate model and (ii) Discovery of knowledge or insights about change in the relationship between input features and output variable w.r.t. the model. Most existing works focus only on detecting model drift but offer no interpretability. In this work, we take a principled approach to study the problem of interpretable model drift detection from a risk perspective using a feature-interaction aware hypothesis testing framework, which enjoys guarantees on test power. The proposed framework is generic, i.e., it can be adapted to both classification and regression tasks. Experiments on several standard drift detection datasets show that our method is superior to existing interpretable methods (especially on real-world datasets) and on par with state-of-the-art black-box drift detection methods. We also quantitatively and qualitatively study the interpretability aspect including a case study on USENET2 dataset. We find our method focuses on model and drift sensitive features compared to baseline interpretable drift detectors.
FW-Shapley: Real-time Estimation of Weighted Shapley Values
Mar 09, 2025Fair credit assignment is essential in various machine learning (ML) applications, and Shapley values have emerged as a valuable tool for this purpose. However, in critical ML applications such as data valuation and feature attribution, the uniform weighting of Shapley values across subset cardinalities leads to unintuitive credit assignments. To address this, weighted Shapley values were proposed as a generalization, allowing different weights for subsets with different cardinalities. Despite their advantages, similar to Shapley values, Weighted Shapley values suffer from exponential compute costs, making them impractical for high-dimensional datasets. To tackle this issue, we present two key contributions. Firstly, we provide a weighted least squares characterization of weighted Shapley values. Next, using this characterization, we propose Fast Weighted Shapley (FW-Shapley), an amortized framework for efficiently computing weighted Shapley values using a learned estimator. We further show that our estimator's training procedure is theoretically valid even though we do not use ground truth Weighted Shapley values during training. On the feature attribution task, we outperform the learned estimator FastSHAP by $27\%$ (on average) in terms of Inclusion AUC. For data valuation, we are much faster (14 times) while being comparable to the state-of-the-art KNN Shapley.
HOLMES: Hyper-Relational Knowledge Graphs for Multi-hop Question Answering using LLMs
Jun 10, 2024



Given unstructured text, Large Language Models (LLMs) are adept at answering simple (single-hop) questions. However, as the complexity of the questions increase, the performance of LLMs degrade. We believe this is due to the overhead associated with understanding the complex question followed by filtering and aggregating unstructured information in the raw text. Recent methods try to reduce this burden by integrating structured knowledge triples into the raw text, aiming to provide a structured overview that simplifies information processing. However, this simplistic approach is query-agnostic and the extracted facts are ambiguous as they lack context. To address these drawbacks and to enable LLMs to answer complex (multi-hop) questions with ease, we propose to use a knowledge graph (KG) that is context-aware and is distilled to contain query-relevant information. The use of our compressed distilled KG as input to the LLM results in our method utilizing up to $67\%$ fewer tokens to represent the query relevant information present in the supporting documents, compared to the state-of-the-art (SoTA) method. Our experiments show consistent improvements over the SoTA across several metrics (EM, F1, BERTScore, and Human Eval) on two popular benchmark datasets (HotpotQA and MuSiQue).
C2FDrone: Coarse-to-Fine Drone-to-Drone Detection using Vision Transformer Networks
Apr 30, 2024A vision-based drone-to-drone detection system is crucial for various applications like collision avoidance, countering hostile drones, and search-and-rescue operations. However, detecting drones presents unique challenges, including small object sizes, distortion, occlusion, and real-time processing requirements. Current methods integrating multi-scale feature fusion and temporal information have limitations in handling extreme blur and minuscule objects. To address this, we propose a novel coarse-to-fine detection strategy based on vision transformers. We evaluate our approach on three challenging drone-to-drone detection datasets, achieving F1 score enhancements of 7%, 3%, and 1% on the FL-Drones, AOT, and NPS-Drones datasets, respectively. Additionally, we demonstrate real-time processing capabilities by deploying our model on an edge-computing device. Our code will be made publicly available.
Instance-wise Causal Feature Selection for Model Interpretation
Apr 26, 2021



We formulate a causal extension to the recently introduced paradigm of instance-wise feature selection to explain black-box visual classifiers. Our method selects a subset of input features that has the greatest causal effect on the models output. We quantify the causal influence of a subset of features by the Relative Entropy Distance measure. Under certain assumptions this is equivalent to the conditional mutual information between the selected subset and the output variable. The resulting causal selections are sparser and cover salient objects in the scene. We show the efficacy of our approach on multiple vision datasets by measuring the post-hoc accuracy and Average Causal Effect of selected features on the models output.
Blending of Learning-based Tracking and Object Detection for Monocular Camera-based Target Following
Aug 21, 2020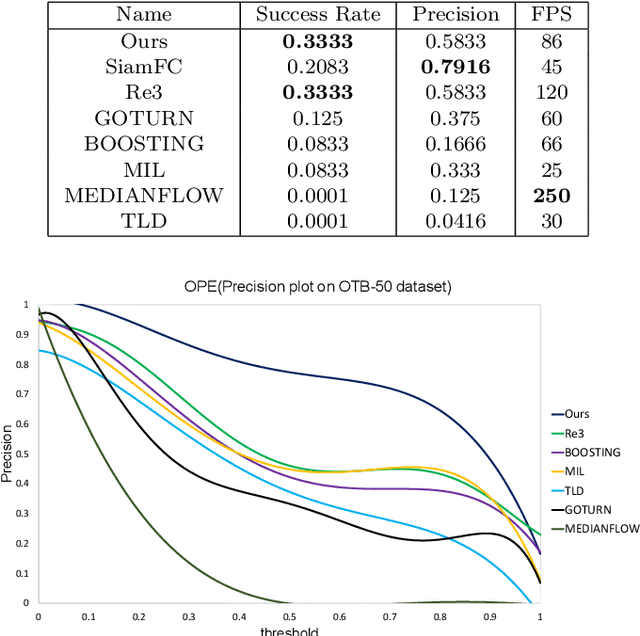
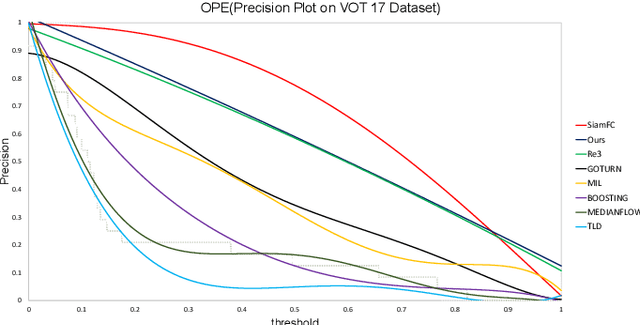
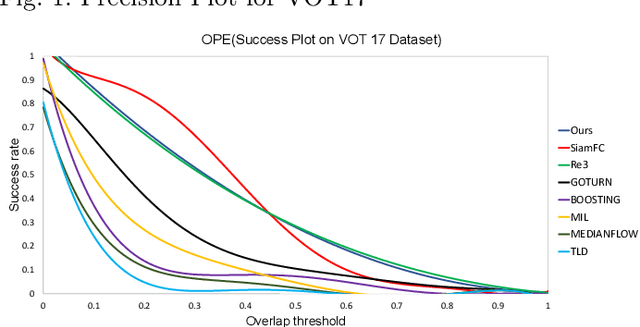

Deep learning has recently started being applied to visual tracking of generic objects in video streams. For the purposes of robotics applications, it is very important for a target tracker to recover its track if it is lost due to heavy or prolonged occlusions or motion blur of the target. We present a real-time approach which fuses a generic target tracker and object detection module with a target re-identification module. Our work focuses on improving the performance of Convolutional Recurrent Neural Network-based object trackers in cases where the object of interest belongs to the category of \emph{familiar} objects. Our proposed approach is sufficiently lightweight to track objects at 85-90 FPS while attaining competitive results on challenging benchmarks.
Image Dehazing via Joint Estimation of Transmittance Map and Environmental Illumination
Dec 04, 2018
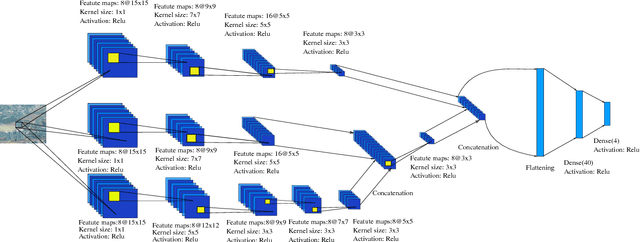

Haze limits the visibility of outdoor images, due to the existence of fog, smoke and dust in the atmosphere. Image dehazing methods try to recover haze-free image by removing the effect of haze from a given input image. In this paper, we present an end to end system, which takes a hazy image as its input and returns a dehazed image. The proposed method learns the mapping between a hazy image and its corresponding transmittance map and the environmental illumination, by using a multi-scale Convolutional Neural Network. Although most of the time haze appears grayish in color, its color may vary depending on the color of the environmental illumination. Very few of the existing image dehazing methods have laid stress on its accurate estimation. But the color of the dehazed image and the estimated transmittance depends on the environmental illumination. Our proposed method exploits the relationship between the transmittance values and the environmental illumination as per the haze imaging model and estimates both of them. Qualitative and quantitative evaluations show, the estimates are accurate enough.