 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeSignificance of Anatomical Constraints in Virtual Try-On
Jan 04, 2024



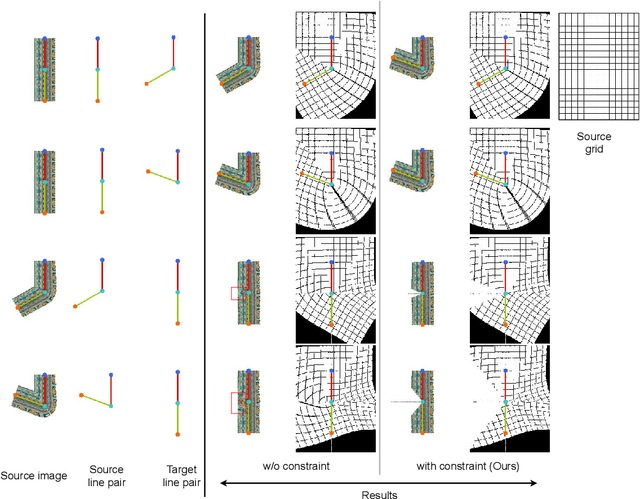
The system of Virtual Try-ON (VTON) allows a user to try a product virtually. In general, a VTON system takes a clothing source and a person's image to predict the try-on output of the person in the given clothing. Although existing methods perform well for simple poses, in case of bent or crossed arms posture or when there is a significant difference between the alignment of the source clothing and the pose of the target person, these methods fail by generating inaccurate clothing deformations. In the VTON methods that employ Thin Plate Spline (TPS) based clothing transformations, this mainly occurs for two reasons - (1)~the second-order smoothness constraint of TPS that restricts the bending of the object plane. (2)~Overlaps among different clothing parts (e.g., sleeves and torso) can not be modeled by a single TPS transformation, as it assumes the clothing as a single planar object; therefore, disregards the independence of movement of different clothing parts. To this end, we make two major contributions. Concerning the bending limitations of TPS, we propose a human AnaTomy-Aware Geometric (ATAG) transformation. Regarding the overlap issue, we propose a part-based warping approach that divides the clothing into independently warpable parts to warp them separately and later combine them. Extensive analysis shows the efficacy of this approach.
Significance of Skeleton-based Features in Virtual Try-On
Sep 01, 2022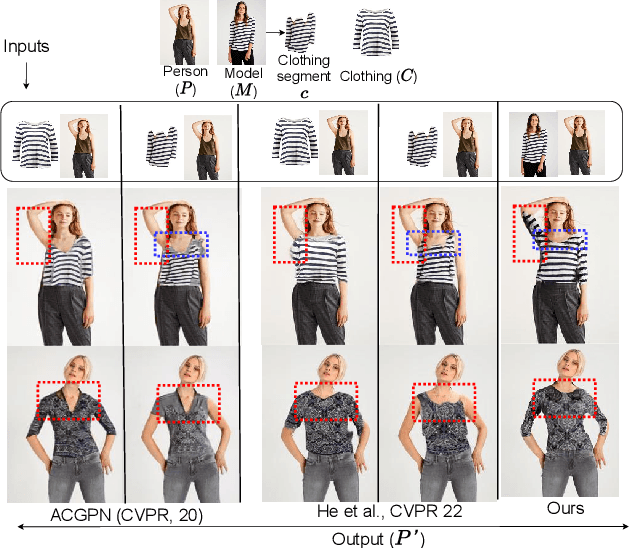


The idea of \textit{Virtual Try-ON} (VTON) benefits e-retailing by giving an user the convenience of trying a clothing at the comfort of their home. In general, most of the existing VTON methods produce inconsistent results when a person posing with his arms folded i.e., bent or crossed, wants to try an outfit. The problem becomes severe in the case of long-sleeved outfits. As then, for crossed arm postures, overlap among different clothing parts might happen. The existing approaches, especially the warping-based methods employing \textit{Thin Plate Spline (TPS)} transform can not tackle such cases. To this end, we attempt a solution approach where the clothing from the source person is segmented into semantically meaningful parts and each part is warped independently to the shape of the person. To address the bending issue, we employ hand-crafted geometric features consistent with human body geometry for warping the source outfit. In addition, we propose two learning-based modules: a synthesizer network and a mask prediction network. All these together attempt to produce a photo-realistic, pose-robust VTON solution without requiring any paired training data. Comparison with some of the benchmark methods clearly establishes the effectiveness of the approach.
LGVTON: A Landmark Guided Approach to Virtual Try-On
Apr 01, 2020



We address the problem of image based virtual try-on (VTON), where the goal is to synthesize an image of a person wearing the cloth of a model. An essential requirement for generating a perceptually convincing VTON result is preserving the characteristics of the cloth and the person. Keeping this in mind we propose \textit{LGVTON}, a novel self-supervised landmark guided approach to image based virtual try-on. The incorporation of self-supervision tackles the problem of lack of paired training data in model to person VTON scenario. LGVTON uses two types of landmarks to warp the model cloth according to the shape and pose of the person, one, human landmarks, the locations of anatomical keypoints of human, two, fashion landmarks, the structural keypoints of cloth. We introduce an unique way of using landmarks for warping which is more efficient and effective compared to existing warping based methods in current problem scenario. In addition to that, to make the method robust in cases of noisy landmark estimates that causes inaccurate warping, we propose a mask generator module that attempts to predict the true segmentation mask of the model cloth on the person, which in turn guides our image synthesizer module in tackling warping issues. Experimental results show the effectiveness of our method in comparison to the state-of-the-art VTON methods.
Morphological Networks for Image De-raining
Jan 08, 2019

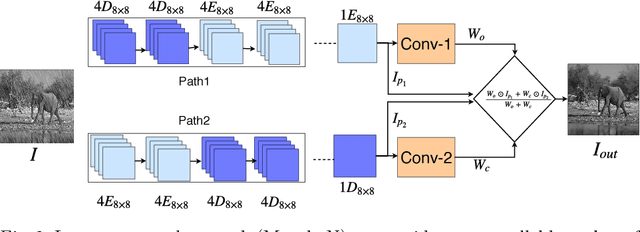

Mathematical morphological methods have successfully been applied to filter out (emphasize or remove) different structures of an image. However, it is argued that these methods could be suitable for the task only if the type and order of the filter(s) as well as the shape and size of operator kernel are designed properly. Thus the existing filtering operators are problem (instance) specific and are designed by the domain experts. In this work we propose a morphological network that emulates classical morphological filtering consisting of a series of erosion and dilation operators with trainable structuring elements. We evaluate the proposed network for image de-raining task where the SSIM and mean absolute error (MAE) loss corresponding to predicted and ground-truth clean image is back-propagated through the network to train the structuring elements. We observe that a single morphological network can de-rain an image with any arbitrary shaped rain-droplets and achieves similar performance with the contemporary CNNs for this task with a fraction of trainable parameters (network size). The proposed morphological network(MorphoN) is not designed specifically for de-raining and can readily be applied to similar filtering / noise cleaning tasks. The source code can be found here https://github.com/ranjanZ/2D-Morphological-Network
* Mathematical Morphology \and Optimization \and Morphological Network \and Image Filtering
Dense Morphological Network: An Universal Function Approximator
Jan 01, 2019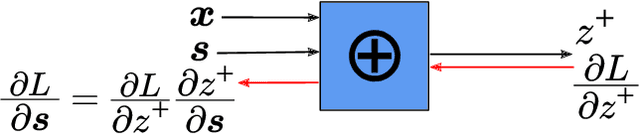

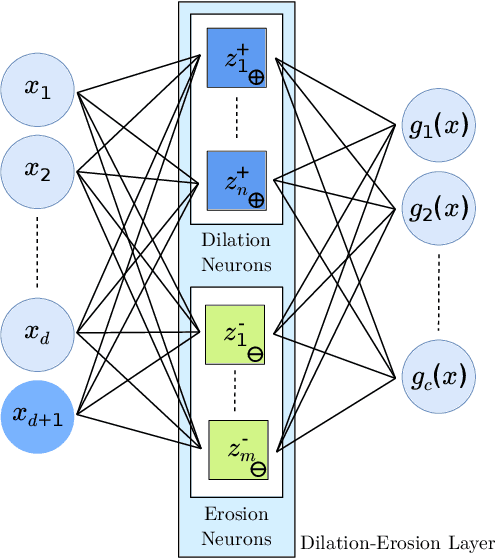
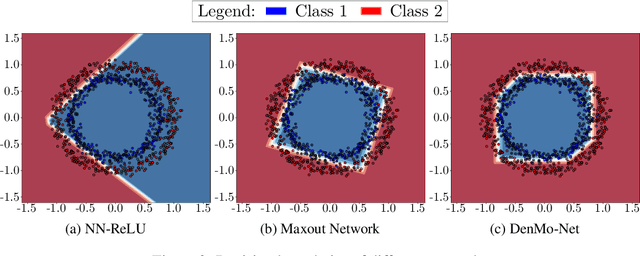
Artificial neural networks are built on the basic operation of linear combination and non-linear activation function. Theoretically this structure can approximate any continuous function with three layer architecture. But in practice learning the parameters of such network can be hard. Also the choice of activation function can greatly impact the performance of the network. In this paper we are proposing to replace the basic linear combination operation with non-linear operations that do away with the need of additional non-linear activation function. To this end we are proposing the use of elementary morphological operations (dilation and erosion) as the basic operation in neurons. We show that these networks (Denoted as DenMo-Net) with morphological operations can approximate any smooth function requiring less number of parameters than what is necessary for normal neural networks. The results show that our network perform favorably when compared with similar structured network.
Image Dehazing via Joint Estimation of Transmittance Map and Environmental Illumination
Dec 04, 2018
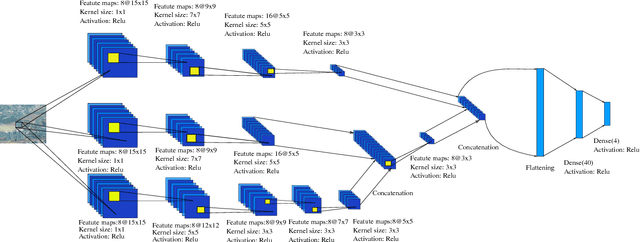
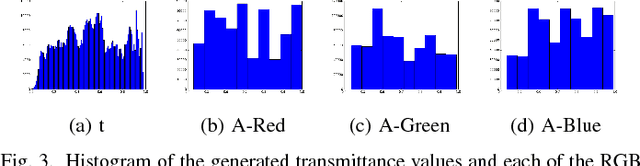

Haze limits the visibility of outdoor images, due to the existence of fog, smoke and dust in the atmosphere. Image dehazing methods try to recover haze-free image by removing the effect of haze from a given input image. In this paper, we present an end to end system, which takes a hazy image as its input and returns a dehazed image. The proposed method learns the mapping between a hazy image and its corresponding transmittance map and the environmental illumination, by using a multi-scale Convolutional Neural Network. Although most of the time haze appears grayish in color, its color may vary depending on the color of the environmental illumination. Very few of the existing image dehazing methods have laid stress on its accurate estimation. But the color of the dehazed image and the estimated transmittance depends on the environmental illumination. Our proposed method exploits the relationship between the transmittance values and the environmental illumination as per the haze imaging model and estimates both of them. Qualitative and quantitative evaluations show, the estimates are accurate enough.
Reconstruction Loss Minimized FCN for Single Image Dehazing
Nov 27, 2018
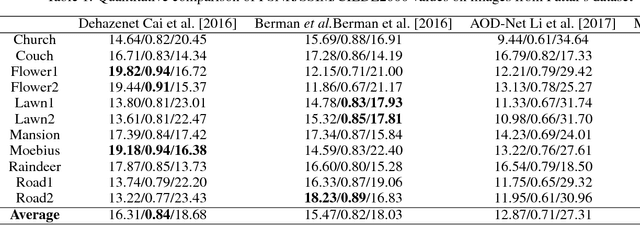
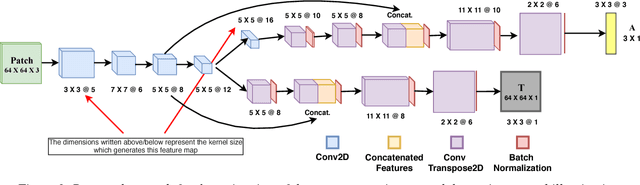

Haze and fog reduce the visibility of outdoor scenes as a veil like semi-transparent layer appears over the objects. As a result, images captured under such conditions lack contrast. Image dehazing methods try to alleviate this problem by recovering a clear version of the image. In this paper, we propose a Fully Convolutional Neural Network based model to recover the clear scene radiance by estimating the environmental illumination and the scene transmittance jointly from a hazy image. The method uses a relaxed haze imaging model to allow for the situations with non-uniform illumination. We have trained the network by minimizing a custom-defined loss that measures the error of reconstructing the hazy image in three different ways. Additionally, we use a multilevel approach to determine the scene transmittance and the environmental illumination in order to reduce the dependence of the estimate on image scale. Evaluations show that our model performs well compared to the existing state-of-the-art methods. It also verifies the potential of our model in diverse situations and various lighting conditions.