 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeAn Approach Towards Learning K-means-friendly Deep Latent Representation
Nov 29, 2024Clustering is a long-standing problem area in data mining. The centroid-based classical approaches to clustering mainly face difficulty in the case of high dimensional inputs such as images. With the advent of deep neural networks, a common approach to this problem is to map the data to some latent space of comparatively lower dimensions and then do the clustering in that space. Network architectures adopted for this are generally autoencoders that reconstruct a given input in the output. To keep the input in some compact form, the encoder in AE's learns to extract useful features that get decoded at the reconstruction end. A well-known centroid-based clustering algorithm is K-means. In the context of deep feature learning, recent works have empirically shown the importance of learning the representations and the cluster centroids together. However, in this aspect of joint learning, recently a continuous variant of K-means has been proposed; where the softmax function is used in place of argmax to learn the clustering and network parameters jointly using stochastic gradient descent (SGD). However, unlike K-means, where the input space stays constant, here the learning of the centroid is done in parallel to the learning of the latent space for every batch of data. Such batch updates disagree with the concept of classical K-means, where the clustering space remains constant as it is the input space itself. To this end, we propose to alternatively learn a clustering-friendly data representation and K-means based cluster centers. Experiments on some benchmark datasets have shown improvements of our approach over the previous approaches.
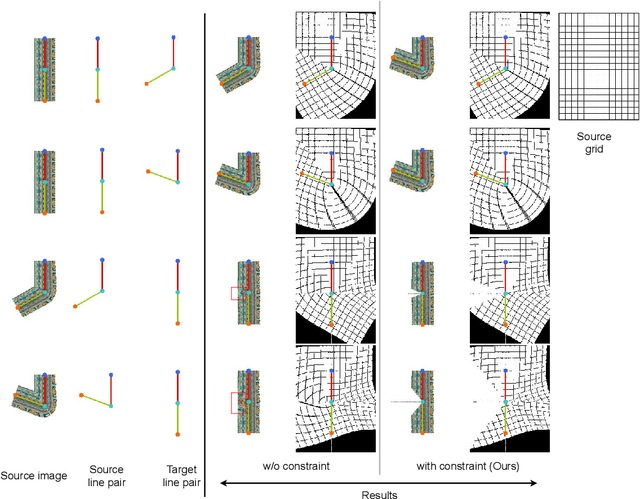
Significance of Anatomical Constraints in Virtual Try-On
Jan 04, 2024



The system of Virtual Try-ON (VTON) allows a user to try a product virtually. In general, a VTON system takes a clothing source and a person's image to predict the try-on output of the person in the given clothing. Although existing methods perform well for simple poses, in case of bent or crossed arms posture or when there is a significant difference between the alignment of the source clothing and the pose of the target person, these methods fail by generating inaccurate clothing deformations. In the VTON methods that employ Thin Plate Spline (TPS) based clothing transformations, this mainly occurs for two reasons - (1)~the second-order smoothness constraint of TPS that restricts the bending of the object plane. (2)~Overlaps among different clothing parts (e.g., sleeves and torso) can not be modeled by a single TPS transformation, as it assumes the clothing as a single planar object; therefore, disregards the independence of movement of different clothing parts. To this end, we make two major contributions. Concerning the bending limitations of TPS, we propose a human AnaTomy-Aware Geometric (ATAG) transformation. Regarding the overlap issue, we propose a part-based warping approach that divides the clothing into independently warpable parts to warp them separately and later combine them. Extensive analysis shows the efficacy of this approach.
Significance of Skeleton-based Features in Virtual Try-On
Sep 01, 2022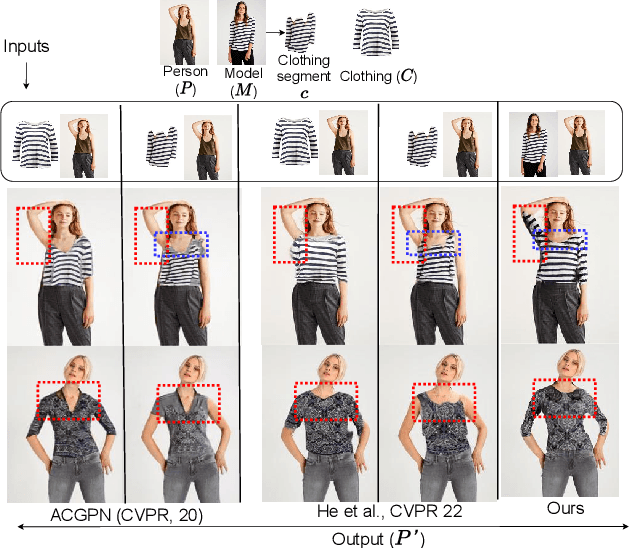


The idea of \textit{Virtual Try-ON} (VTON) benefits e-retailing by giving an user the convenience of trying a clothing at the comfort of their home. In general, most of the existing VTON methods produce inconsistent results when a person posing with his arms folded i.e., bent or crossed, wants to try an outfit. The problem becomes severe in the case of long-sleeved outfits. As then, for crossed arm postures, overlap among different clothing parts might happen. The existing approaches, especially the warping-based methods employing \textit{Thin Plate Spline (TPS)} transform can not tackle such cases. To this end, we attempt a solution approach where the clothing from the source person is segmented into semantically meaningful parts and each part is warped independently to the shape of the person. To address the bending issue, we employ hand-crafted geometric features consistent with human body geometry for warping the source outfit. In addition, we propose two learning-based modules: a synthesizer network and a mask prediction network. All these together attempt to produce a photo-realistic, pose-robust VTON solution without requiring any paired training data. Comparison with some of the benchmark methods clearly establishes the effectiveness of the approach.
An Unsupervised Approach towards Varying Human Skin Tone Using Generative Adversarial Networks
Oct 30, 2020



With the increasing popularity of augmented and virtual reality, retailers are now focusing more towards customer satisfaction to increase the amount of sales. Although augmented reality is not a new concept but it has gained much needed attention over the past few years. Our present work is targeted towards this direction which may be used to enhance user experience in various virtual and augmented reality based applications. We propose a model to change skin tone of a person. Given any input image of a person or a group of persons with some value indicating the desired change of skin color towards fairness or darkness, this method can change the skin tone of the persons in the image. This is an unsupervised method and also unconstrained in terms of pose, illumination, number of persons in the image etc. The goal of this work is to reduce the time and effort which is generally required for changing the skin tone using existing applications (e.g., Photoshop) by professionals or novice. To establish the efficacy of this method we have compared our result with that of some popular photo editor and also with the result of some existing benchmark method related to human attribute manipulation. Rigorous experiments on different datasets show the effectiveness of this method in terms of synthesizing perceptually convincing outputs.
LGVTON: A Landmark Guided Approach to Virtual Try-On
Apr 01, 2020



We address the problem of image based virtual try-on (VTON), where the goal is to synthesize an image of a person wearing the cloth of a model. An essential requirement for generating a perceptually convincing VTON result is preserving the characteristics of the cloth and the person. Keeping this in mind we propose \textit{LGVTON}, a novel self-supervised landmark guided approach to image based virtual try-on. The incorporation of self-supervision tackles the problem of lack of paired training data in model to person VTON scenario. LGVTON uses two types of landmarks to warp the model cloth according to the shape and pose of the person, one, human landmarks, the locations of anatomical keypoints of human, two, fashion landmarks, the structural keypoints of cloth. We introduce an unique way of using landmarks for warping which is more efficient and effective compared to existing warping based methods in current problem scenario. In addition to that, to make the method robust in cases of noisy landmark estimates that causes inaccurate warping, we propose a mask generator module that attempts to predict the true segmentation mask of the model cloth on the person, which in turn guides our image synthesizer module in tackling warping issues. Experimental results show the effectiveness of our method in comparison to the state-of-the-art VTON methods.