 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeDistributed Multirobot Control for Non-Cooperative Herding
Jan 09, 2023
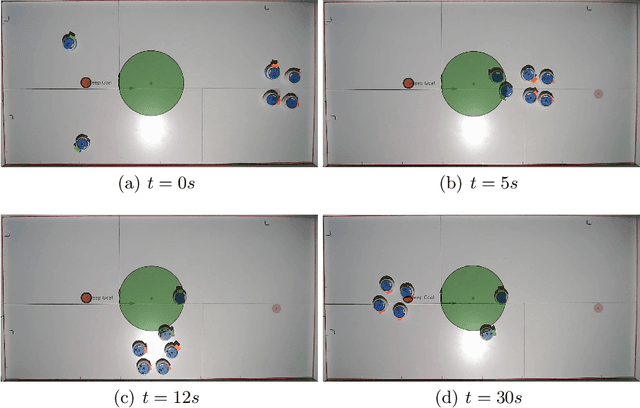
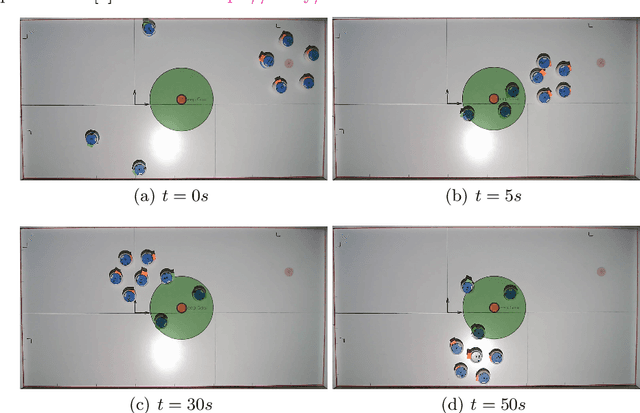
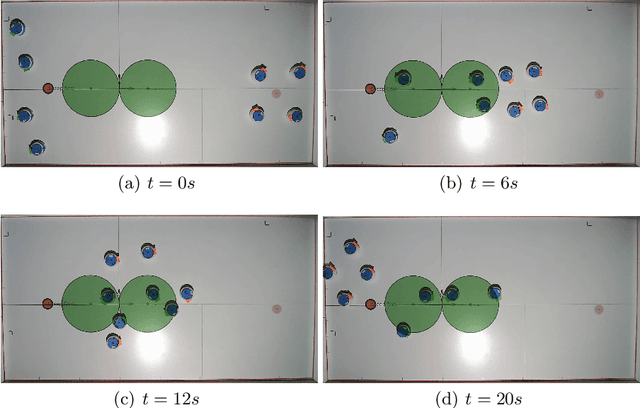
In this paper, we consider the problem of protecting a high-value area from being breached by sheep agents by crafting motions for dog robots. We use control barrier functions to pose constraints on the dogs' velocities that induce repulsions in the sheep relative to the high-value area. This paper extends the results developed in our prior work on the same topic in three ways. Firstly, we implement and validate our previously developed centralized herding algorithm on many robots. We show herding of up to five sheep agents using three dog robots. Secondly, as an extension to the centralized approach, we develop two distributed herding algorithms, one favoring feasibility while the other favoring optimality. In the first algorithm, we allocate a unique sheep to a unique dog, making that dog responsible for herding its allocated sheep away from the protected zone. We provide feasibility proof for this approach, along with numerical simulations. In the second algorithm, we develop an iterative distributed reformulation of the centralized algorithm, which inherits the optimality (i.e. budget efficiency) from the centralized approach. Lastly, we conduct real-world experiments of these distributed algorithms and demonstrate herding of up to five sheep agents using five dog robots.
Noncooperative Herding With Control Barrier Functions: Theory and Experiments
Apr 22, 2022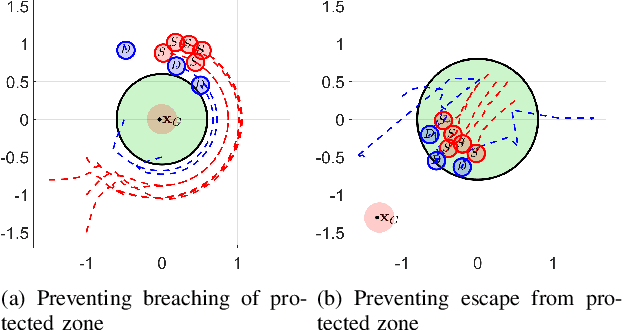
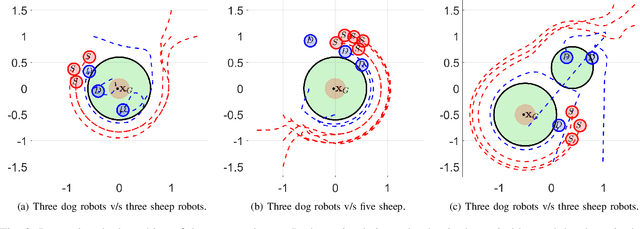


In this paper, we consider the problem of protecting a high-value unit from inadvertent attack by a group of agents using defending robots. Specifically, we develop a control strategy for the defending agents that we call "dog robots" to prevent a flock of "sheep agents" from breaching a protected zone. We take recourse to control barrier functions to pose this problem and exploit the interaction dynamics between the sheep and dogs to find dogs' velocities that result in the sheep getting repelled from the zone. We solve a QP reactively that incorporates the defending constraints to compute the desired velocities for all dogs. Owing to this, our proposed framework is composable \textit{i.e.} it allows for simultaneous inclusion of multiple protected zones in the constraints on dog robots' velocities. We provide a theoretical proof of feasibility of our strategy for the one dog/one sheep case. Additionally, we provide empirical results of two dogs defending the protected zone from upto ten sheep averaged over a hundred simulations and report high success rates. We also demonstrate this algorithm experimentally on non-holonomic robots. Videos of these results are available at https://tinyurl.com/4dj2kjwx.
Fast Obstacle Avoidance Motion in SmallQuadcopter operation in a Cluttered Environment
Sep 19, 2021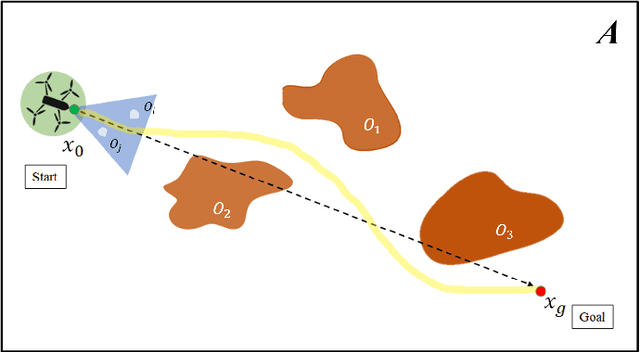
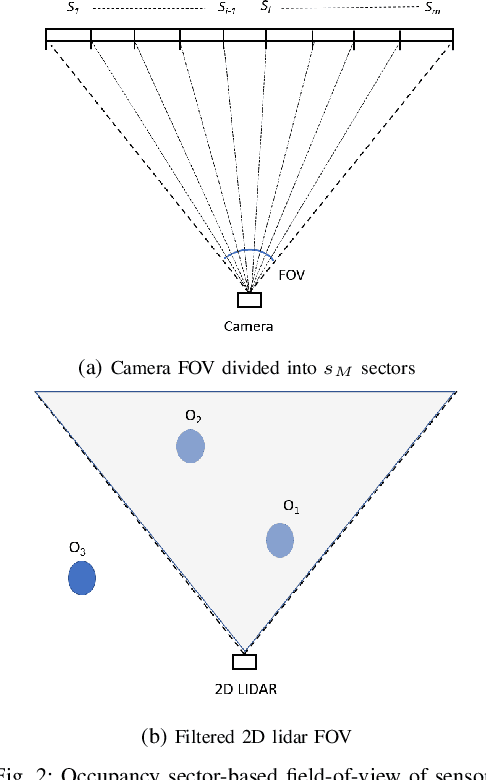
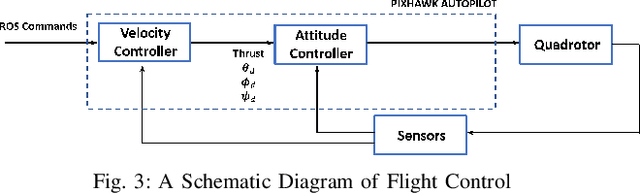
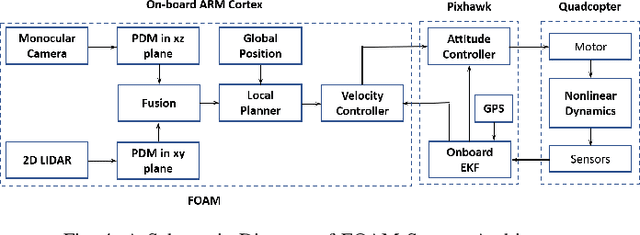
The autonomous operation of small quadcopters moving at high speed in an unknown cluttered environment is a challenging task. Current works in the literature formulate it as a Sense-And-Avoid (SAA) problem and address it by either developing new sensing capabilities or small form-factor processors. However, the SAA, with the high-speed operation, remains an open problem. The significant complexity arises due to the computational latency, which is critical for fast-moving quadcopters. In this paper, a novel Fast Obstacle Avoidance Motion (FOAM) algorithm is proposed to perform SAA operations. FOAM is a low-latency perception-based algorithm that uses multi-sensor fusion of a monocular camera and a 2-D LIDAR. A 2-D probabilistic occupancy map of the sensing region is generated to estimate a free space for avoiding obstacles. Also, a local planner is used to navigate the high-speed quadcopter towards a given target location while avoiding obstacles. The performance evaluation of FOAM is evaluated in simulated environments in Gazebo and AIRSIM. Real-time implementation of the same has been presented in outdoor environments using a custom-designed quadcopter operating at a speed of $4.5$ m/s. The FOAM algorithm is implemented on a low-cost computing device to demonstrate its efficacy. The results indicate that FOAM enables a small quadcopter to operate at high speed in a cluttered environment efficiently.
Scaffolding Reflection in Reinforcement Learning Framework for Confinement Escape Problem
Nov 13, 2020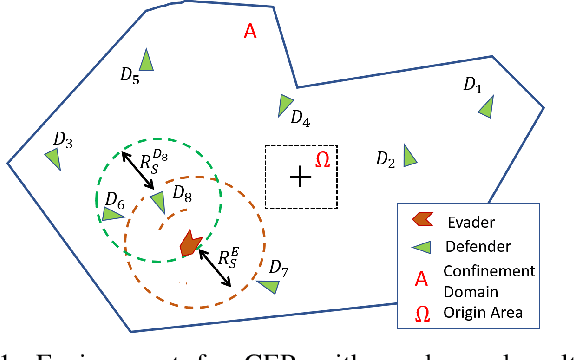
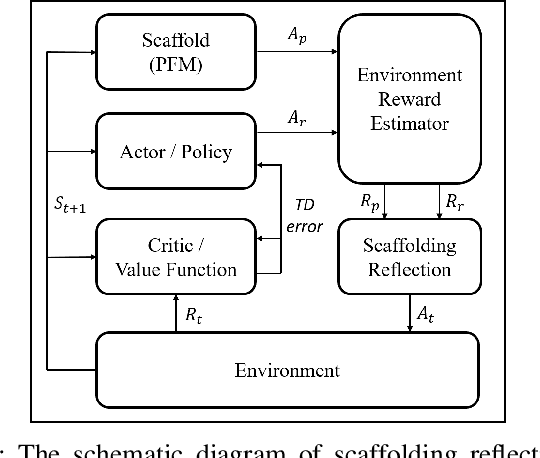
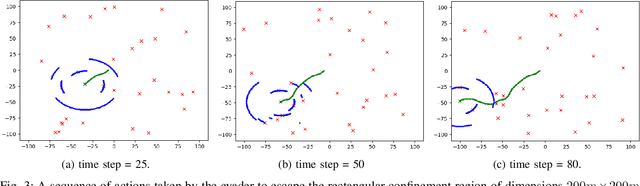
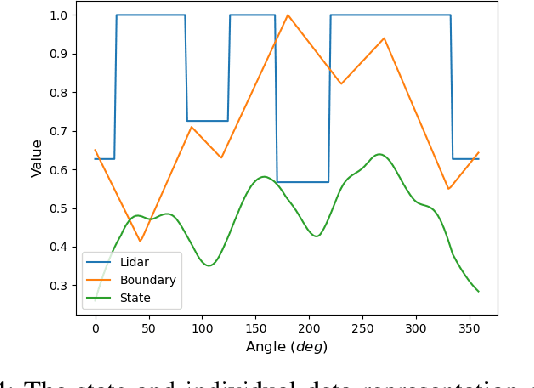
This paper formulates an application of reinforcement learning for an evader in a confinement escape problem. An evader's objective is to attempt escaping a confinement region patrolled by multiple defenders, with minimum use of energy. Meanwhile, the defenders aim to reach and capture the evader without any communication between them. The problem formulation uses the actor-critic approach for the defender. In this paper, the novel Scaffolding Reflection in Reinforcement Learning (SR2L) framework is proposed, using a potential field method as a scaffold to assist the actor's action-reflection. Through the user's clearly articulated intent, the action-reflection enables the actor to learn by observing the probable actions and their values based on experience. Extensive Monte-Carlo simulations show the performance of a trained SR2L against the baseline approach. The SR2L framework achieves at least one order fewer episodes to learn the policy than the conventional RL framework.
Image Dehazing via Joint Estimation of Transmittance Map and Environmental Illumination
Dec 04, 2018
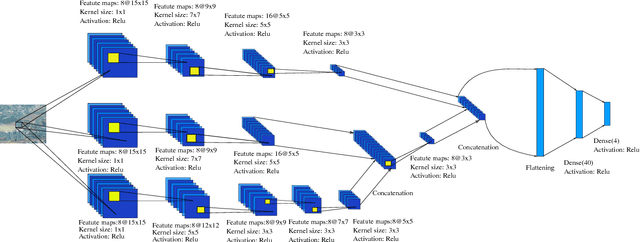
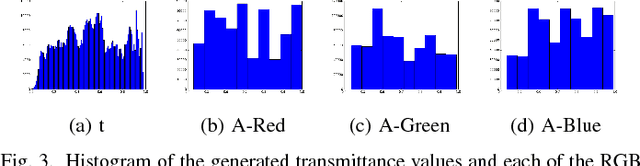

Haze limits the visibility of outdoor images, due to the existence of fog, smoke and dust in the atmosphere. Image dehazing methods try to recover haze-free image by removing the effect of haze from a given input image. In this paper, we present an end to end system, which takes a hazy image as its input and returns a dehazed image. The proposed method learns the mapping between a hazy image and its corresponding transmittance map and the environmental illumination, by using a multi-scale Convolutional Neural Network. Although most of the time haze appears grayish in color, its color may vary depending on the color of the environmental illumination. Very few of the existing image dehazing methods have laid stress on its accurate estimation. But the color of the dehazed image and the estimated transmittance depends on the environmental illumination. Our proposed method exploits the relationship between the transmittance values and the environmental illumination as per the haze imaging model and estimates both of them. Qualitative and quantitative evaluations show, the estimates are accurate enough.