 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeCan LLMs Help You at Work? A Sandbox for Evaluating LLM Agents in Enterprise Environments
Oct 31, 2025Enterprise systems are crucial for enhancing productivity and decision-making among employees and customers. Integrating LLM based systems into enterprise systems enables intelligent automation, personalized experiences, and efficient information retrieval, driving operational efficiency and strategic growth. However, developing and evaluating such systems is challenging due to the inherent complexity of enterprise environments, where data is fragmented across multiple sources and governed by sophisticated access controls. We present EnterpriseBench, a comprehensive benchmark that simulates enterprise settings, featuring 500 diverse tasks across software engineering, HR, finance, and administrative domains. Our benchmark uniquely captures key enterprise characteristics including data source fragmentation, access control hierarchies, and cross-functional workflows. Additionally, we provide a novel data generation pipeline that creates internally consistent enterprise tasks from organizational metadata. Experiments with state-of-the-art LLM agents demonstrate that even the most capable models achieve only 41.8% task completion, highlighting significant opportunities for improvement in enterprise-focused AI systems.
Finding Needles in Images: Can Multimodal LLMs Locate Fine Details?
Aug 07, 2025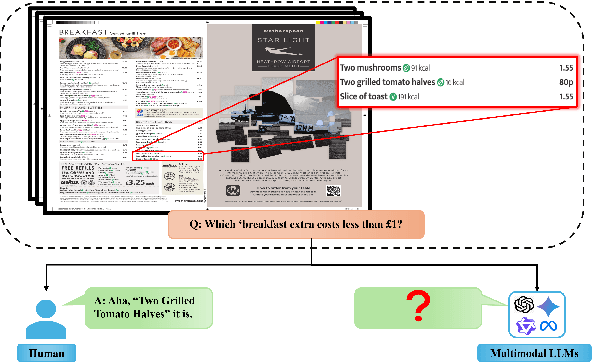
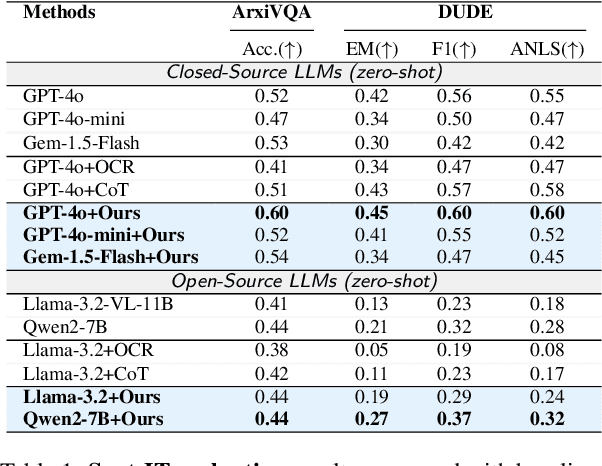
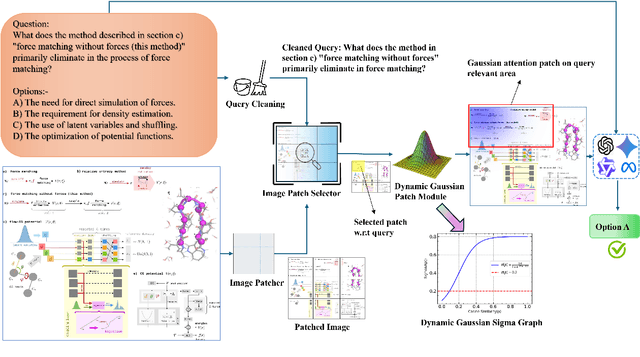
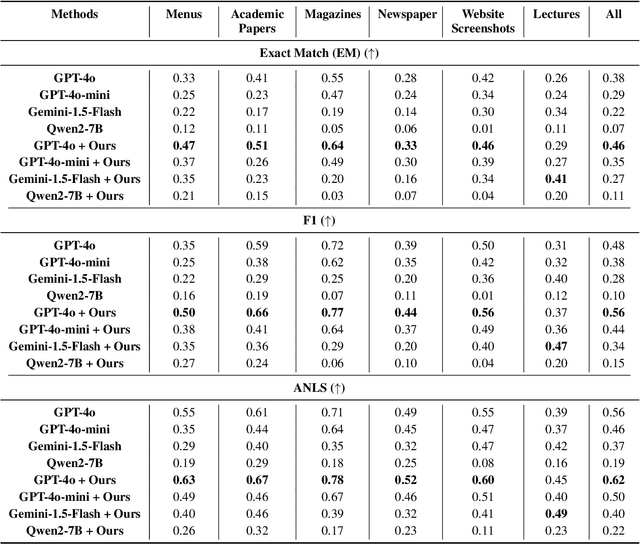
While Multi-modal Large Language Models (MLLMs) have shown impressive capabilities in document understanding tasks, their ability to locate and reason about fine-grained details within complex documents remains understudied. Consider searching a restaurant menu for a specific nutritional detail or identifying a disclaimer in a lengthy newspaper article tasks that demand careful attention to small but significant details within a broader narrative, akin to Finding Needles in Images (NiM). To address this gap, we introduce NiM, a carefully curated benchmark spanning diverse real-world documents including newspapers, menus, and lecture images, specifically designed to evaluate MLLMs' capability in these intricate tasks. Building on this, we further propose Spot-IT, a simple yet effective approach that enhances MLLMs capability through intelligent patch selection and Gaussian attention, motivated from how humans zoom and focus when searching documents. Our extensive experiments reveal both the capabilities and limitations of current MLLMs in handling fine-grained document understanding tasks, while demonstrating the effectiveness of our approach. Spot-IT achieves significant improvements over baseline methods, particularly in scenarios requiring precise detail extraction from complex layouts.
* Accepted at ACL 2025 in the main track
Hybrid Graphs for Table-and-Text based Question Answering using LLMs
Jan 29, 2025



Answering questions that require reasoning and aggregation across both structured (tables) and unstructured (raw text) data sources presents significant challenges. Current methods rely on fine-tuning and high-quality, human-curated data, which is difficult to obtain. Recent advances in Large Language Models (LLMs) have shown promising results for multi-hop question answering (QA) over single-source text data in a zero-shot setting, yet exploration into multi-source Table-Text QA remains limited. In this paper, we present a novel Hybrid Graph-based approach for Table-Text QA that leverages LLMs without fine-tuning. Our method constructs a unified Hybrid Graph from textual and tabular data, pruning information based on the input question to provide the LLM with relevant context concisely. We evaluate our approach on the challenging Hybrid-QA and OTT-QA datasets using state-of-the-art LLMs, including GPT-3.5, GPT-4, and LLaMA-3. Our method achieves the best zero-shot performance on both datasets, improving Exact Match scores by up to 10% on Hybrid-QA and 5.4% on OTT-QA. Moreover, our approach reduces token usage by up to 53% compared to the original context.
Integrating Artificial Intelligence Models and Synthetic Image Data for Enhanced Asset Inspection and Defect Identification
Oct 15, 2024


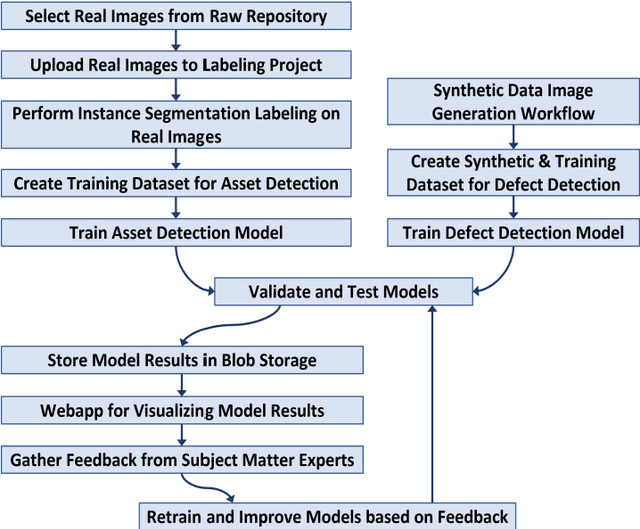
In the past utilities relied on in-field inspections to identify asset defects. Recently, utilities have started using drone-based inspections to enhance the field-inspection process. We consider a vast repository of drone images, providing a wealth of information about asset health and potential issues. However, making the collected imagery data useful for automated defect detection requires significant manual labeling effort. We propose a novel solution that combines synthetic asset defect images with manually labeled drone images. This solution has several benefits: improves performance of defect detection, reduces the number of hours spent on manual labeling, and enables the capability to generate realistic images of rare defects where not enough real-world data is available. We employ a workflow that combines 3D modeling tools such as Maya and Unreal Engine to create photorealistic 3D models and 2D renderings of defective assets and their surroundings. These synthetic images are then integrated into our training pipeline augmenting the real data. This study implements an end-to-end Artificial Intelligence solution to detect assets and asset defects from the combined imagery repository. The unique contribution of this research lies in the application of advanced computer vision models and the generation of photorealistic 3D renderings of defective assets, aiming to transform the asset inspection process. Our asset detection model has achieved an accuracy of 92 percent, we achieved a performance lift of 67 percent when introducing approximately 2,000 synthetic images of 2k resolution. In our tests, the defect detection model achieved an accuracy of 73 percent across two batches of images. Our analysis demonstrated that synthetic data can be successfully used in place of real-world manually labeled data to train defect detection model.
HOLMES: Hyper-Relational Knowledge Graphs for Multi-hop Question Answering using LLMs
Jun 10, 2024



Given unstructured text, Large Language Models (LLMs) are adept at answering simple (single-hop) questions. However, as the complexity of the questions increase, the performance of LLMs degrade. We believe this is due to the overhead associated with understanding the complex question followed by filtering and aggregating unstructured information in the raw text. Recent methods try to reduce this burden by integrating structured knowledge triples into the raw text, aiming to provide a structured overview that simplifies information processing. However, this simplistic approach is query-agnostic and the extracted facts are ambiguous as they lack context. To address these drawbacks and to enable LLMs to answer complex (multi-hop) questions with ease, we propose to use a knowledge graph (KG) that is context-aware and is distilled to contain query-relevant information. The use of our compressed distilled KG as input to the LLM results in our method utilizing up to $67\%$ fewer tokens to represent the query relevant information present in the supporting documents, compared to the state-of-the-art (SoTA) method. Our experiments show consistent improvements over the SoTA across several metrics (EM, F1, BERTScore, and Human Eval) on two popular benchmark datasets (HotpotQA and MuSiQue).
KITLM: Domain-Specific Knowledge InTegration into Language Models for Question Answering
Aug 07, 2023



Large language models (LLMs) have demonstrated remarkable performance in a wide range of natural language tasks. However, as these models continue to grow in size, they face significant challenges in terms of computational costs. Additionally, LLMs often lack efficient domain-specific understanding, which is particularly crucial in specialized fields such as aviation and healthcare. To boost the domain-specific understanding, we propose, KITLM, a novel knowledge base integration approach into language model through relevant information infusion. By integrating pertinent knowledge, not only the performance of the language model is greatly enhanced, but the model size requirement is also significantly reduced while achieving comparable performance. Our proposed knowledge-infused model surpasses the performance of both GPT-3.5-turbo and the state-of-the-art knowledge infusion method, SKILL, achieving over 1.5 times improvement in exact match scores on the MetaQA. KITLM showed a similar performance boost in the aviation domain with AeroQA. The drastic performance improvement of KITLM over the existing methods can be attributed to the infusion of relevant knowledge while mitigating noise. In addition, we release two curated datasets to accelerate knowledge infusion research in specialized fields: a) AeroQA, a new benchmark dataset designed for multi-hop question-answering within the aviation domain, and b) Aviation Corpus, a dataset constructed from unstructured text extracted from the National Transportation Safety Board reports. Our research contributes to advancing the field of domain-specific language understanding and showcases the potential of knowledge infusion techniques in improving the performance of language models on question-answering.
There is No Big Brother or Small Brother: Knowledge Infusion in Language Models for Link Prediction and Question Answering
Jan 10, 2023The integration of knowledge graphs with deep learning is thriving in improving the performance of various natural language processing (NLP) tasks. In this paper, we focus on knowledge-infused link prediction and question answering using language models, T5, and BLOOM across three domains: Aviation, Movie, and Web. In this context, we infuse knowledge in large and small language models and study their performance, and find the performance to be similar. For the link prediction task on the Aviation Knowledge Graph, we obtain a 0.2 hits@1 score using T5-small, T5-base, T5-large, and BLOOM. Using template-based scripts, we create a set of 1 million synthetic factoid QA pairs in the aviation domain from National Transportation Safety Board (NTSB) reports. On our curated QA pairs, the three models of T5 achieve a 0.7 hits@1 score. We validate out findings with the paired student t-test and Cohen's kappa scores. For link prediction on Aviation Knowledge Graph using T5-small and T5-large, we obtain a Cohen's kappa score of 0.76, showing substantial agreement between the models. Thus, we infer that small language models perform similar to large language models with the infusion of knowledge.
Knowledge Graph -- Deep Learning: A Case Study in Question Answering in Aviation Safety Domain
May 31, 2022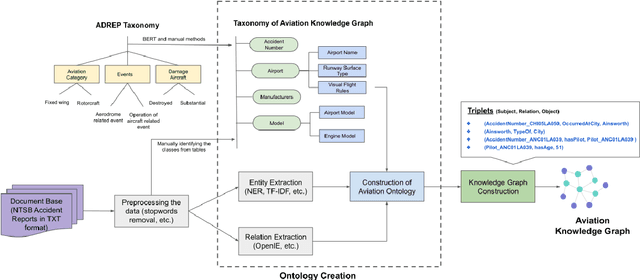
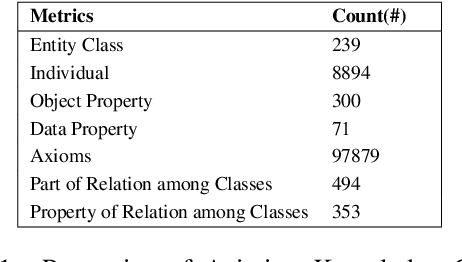
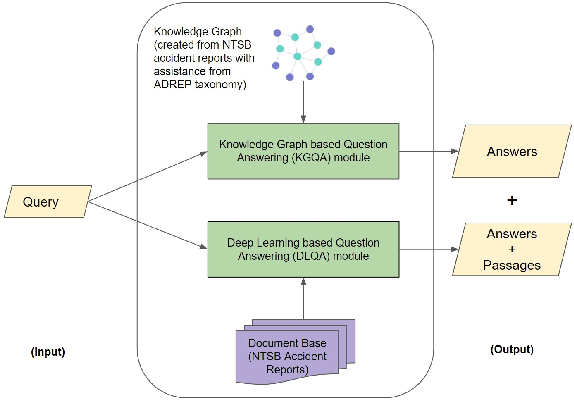

In the commercial aviation domain, there are a large number of documents, like, accident reports (NTSB, ASRS) and regulatory directives (ADs). There is a need for a system to access these diverse repositories efficiently in order to service needs in the aviation industry, like maintenance, compliance, and safety. In this paper, we propose a Knowledge Graph (KG) guided Deep Learning (DL) based Question Answering (QA) system for aviation safety. We construct a Knowledge Graph from Aircraft Accident reports and contribute this resource to the community of researchers. The efficacy of this resource is tested and proved by the aforesaid QA system. Natural Language Queries constructed from the documents mentioned above are converted into SPARQL (the interface language of the RDF graph database) queries and answered. On the DL side, we have two different QA models: (i) BERT QA which is a pipeline of Passage Retrieval (Sentence-BERT based) and Question Answering (BERT based), and (ii) the recently released GPT-3. We evaluate our system on a set of queries created from the accident reports. Our combined QA system achieves 9.3% increase in accuracy over GPT-3 and 40.3% increase over BERT QA. Thus, we infer that KG-DL performs better than either singly.