 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeInterpretable Model Drift Detection
Mar 09, 2025Data in the real world often has an evolving distribution. Thus, machine learning models trained on such data get outdated over time. This phenomenon is called model drift. Knowledge of this drift serves two purposes: (i) Retain an accurate model and (ii) Discovery of knowledge or insights about change in the relationship between input features and output variable w.r.t. the model. Most existing works focus only on detecting model drift but offer no interpretability. In this work, we take a principled approach to study the problem of interpretable model drift detection from a risk perspective using a feature-interaction aware hypothesis testing framework, which enjoys guarantees on test power. The proposed framework is generic, i.e., it can be adapted to both classification and regression tasks. Experiments on several standard drift detection datasets show that our method is superior to existing interpretable methods (especially on real-world datasets) and on par with state-of-the-art black-box drift detection methods. We also quantitatively and qualitatively study the interpretability aspect including a case study on USENET2 dataset. We find our method focuses on model and drift sensitive features compared to baseline interpretable drift detectors.
Linguistically-aware Attention for Reducing the Semantic-Gap in Vision-Language Tasks
Aug 18, 2020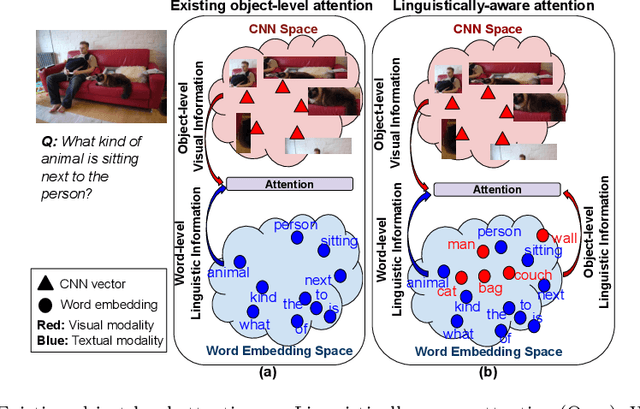
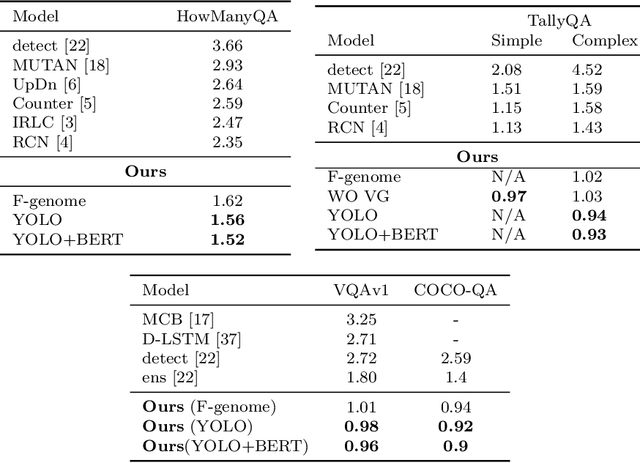
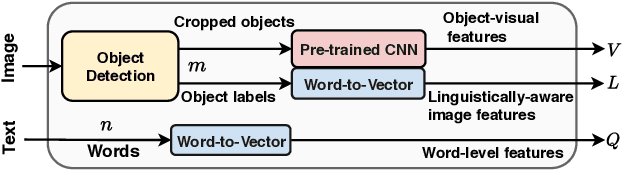
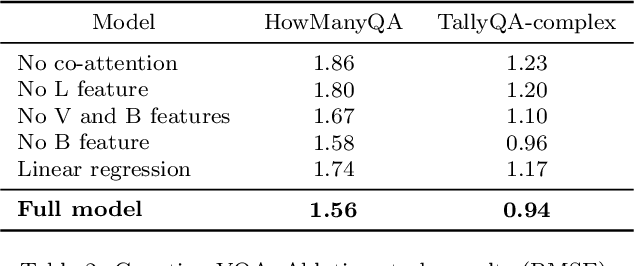
Attention models are widely used in Vision-language (V-L) tasks to perform the visual-textual correlation. Humans perform such a correlation with a strong linguistic understanding of the visual world. However, even the best performing attention model in V-L tasks lacks such a high-level linguistic understanding, thus creating a semantic gap between the modalities. In this paper, we propose an attention mechanism - Linguistically-aware Attention (LAT) - that leverages object attributes obtained from generic object detectors along with pre-trained language models to reduce this semantic gap. LAT represents visual and textual modalities in a common linguistically-rich space, thus providing linguistic awareness to the attention process. We apply and demonstrate the effectiveness of LAT in three V-L tasks: Counting-VQA, VQA, and Image captioning. In Counting-VQA, we propose a novel counting-specific VQA model to predict an intuitive count and achieve state-of-the-art results on five datasets. In VQA and Captioning, we show the generic nature and effectiveness of LAT by adapting it into various baselines and consistently improving their performance.