 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeThe global convergence time of stochastic gradient descent in non-convex landscapes: Sharp estimates via large deviations
Mar 20, 2025In this paper, we examine the time it takes for stochastic gradient descent (SGD) to reach the global minimum of a general, non-convex loss function. We approach this question through the lens of randomly perturbed dynamical systems and large deviations theory, and we provide a tight characterization of the global convergence time of SGD via matching upper and lower bounds. These bounds are dominated by the most "costly" set of obstacles that the algorithm may need to overcome to reach a global minimizer from a given initialization, coupling in this way the global geometry of the underlying loss landscape with the statistics of the noise entering the process. Finally, motivated by applications to the training of deep neural networks, we also provide a series of refinements and extensions of our analysis for loss functions with shallow local minima.
$\texttt{skwdro}$: a library for Wasserstein distributionally robust machine learning
Oct 28, 2024
We present skwdro, a Python library for training robust machine learning models. The library is based on distributionally robust optimization using optimal transport distances. For ease of use, it features both scikit-learn compatible estimators for popular objectives, as well as a wrapper for PyTorch modules, enabling researchers and practitioners to use it in a wide range of models with minimal code changes. Its implementation relies on an entropic smoothing of the original robust objective in order to ensure maximal model flexibility. The library is available at https://github.com/iutzeler/skwdro
What is the long-run distribution of stochastic gradient descent? A large deviations analysis
Jun 13, 2024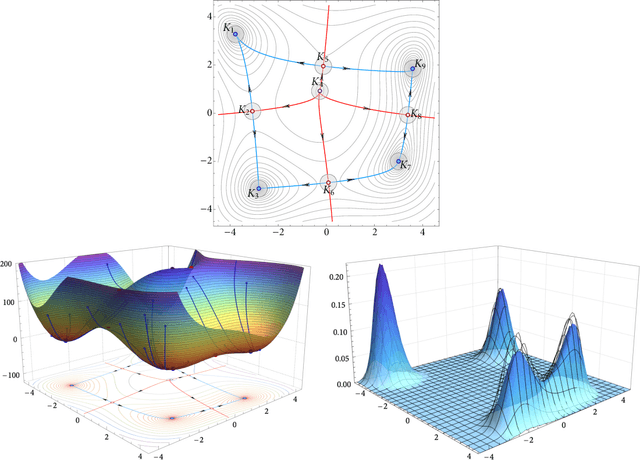
In this paper, we examine the long-run distribution of stochastic gradient descent (SGD) in general, non-convex problems. Specifically, we seek to understand which regions of the problem's state space are more likely to be visited by SGD, and by how much. Using an approach based on the theory of large deviations and randomly perturbed dynamical systems, we show that the long-run distribution of SGD resembles the Boltzmann-Gibbs distribution of equilibrium thermodynamics with temperature equal to the method's step-size and energy levels determined by the problem's objective and the statistics of the noise. In particular, we show that, in the long run, (a) the problem's critical region is visited exponentially more often than any non-critical region; (b) the iterates of SGD are exponentially concentrated around the problem's minimum energy state (which does not always coincide with the global minimum of the objective); (c) all other connected components of critical points are visited with frequency that is exponentially proportional to their energy level; and, finally (d) any component of local maximizers or saddle points is "dominated" by a component of local minimizers which is visited exponentially more often.
Universal Generalization Guarantees for Wasserstein Distributionally Robust Models
Feb 19, 2024


Distributionally robust optimization has emerged as an attractive way to train robust machine learning models, capturing data uncertainty and distribution shifts. Recent statistical analyses have proved that robust models built from Wasserstein ambiguity sets have nice generalization guarantees, breaking the curse of dimensionality. However, these results are obtained in specific cases, at the cost of approximations, or under assumptions difficult to verify in practice. In contrast, we establish, in this article, exact generalization guarantees that cover all practical cases, including any transport cost function and any loss function, potentially non-convex and nonsmooth. For instance, our result applies to deep learning, without requiring restrictive assumptions. We achieve this result through a novel proof technique that combines nonsmooth analysis rationale with classical concentration results. Our approach is general enough to extend to the recent versions of Wasserstein/Sinkhorn distributionally robust problems that involve (double) regularizations.
Exact Generalization Guarantees for (Regularized) Wasserstein Distributionally Robust Models
May 26, 2023Wasserstein distributionally robust estimators have emerged as powerful models for prediction and decision-making under uncertainty. These estimators provide attractive generalization guarantees: the robust objective obtained from the training distribution is an exact upper bound on the true risk with high probability. However, existing guarantees either suffer from the curse of dimensionality, are restricted to specific settings, or lead to spurious error terms. In this paper, we show that these generalization guarantees actually hold on general classes of models, do not suffer from the curse of dimensionality, and can even cover distribution shifts at testing. We also prove that these results carry over to the newly-introduced regularized versions of Wasserstein distributionally robust problems.
On the rate of convergence of Bregman proximal methods in constrained variational inequalities
Nov 15, 2022We examine the last-iterate convergence rate of Bregman proximal methods - from mirror descent to mirror-prox - in constrained variational inequalities. Our analysis shows that the convergence speed of a given method depends sharply on the Legendre exponent of the underlying Bregman regularizer (Euclidean, entropic, or other), a notion that measures the growth rate of said regularizer near a solution. In particular, we show that boundary solutions exhibit a clear separation of regimes between methods with a zero and non-zero Legendre exponent respectively, with linear convergence for the former versus sublinear for the latter. This dichotomy becomes even more pronounced in linearly constrained problems where, specifically, Euclidean methods converge along sharp directions in a finite number of steps, compared to a linear rate for entropic methods.
Push--Pull with Device Sampling
Jun 08, 2022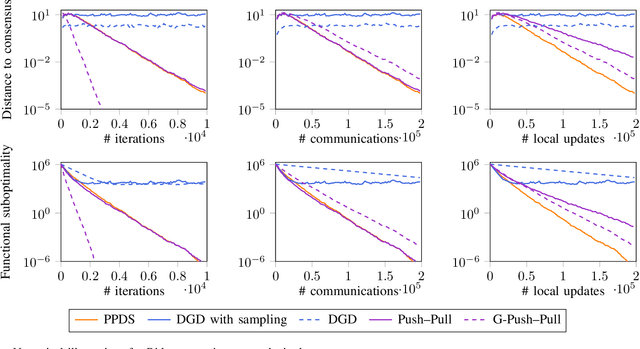
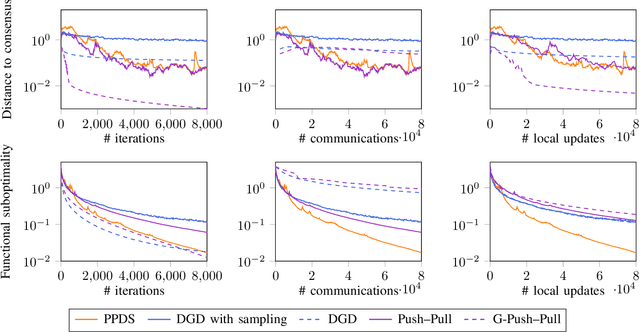
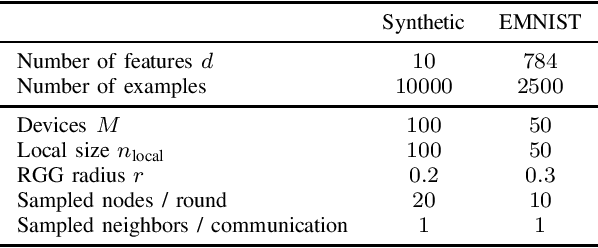
We consider decentralized optimization problems in which a number of agents collaborate to minimize the average of their local functions by exchanging over an underlying communication graph. Specifically, we place ourselves in an asynchronous model where only a random portion of nodes perform computation at each iteration, while the information exchange can be conducted between all the nodes and in an asymmetric fashion. For this setting, we propose an algorithm that combines gradient tracking and variance reduction over the entire network. This enables each node to track the average of the gradients of the objective functions. Our theoretical analysis shows that the algorithm converges linearly, when the local objective functions are strongly convex, under mild connectivity conditions on the expected mixing matrices. In particular, our result does not require the mixing matrices to be doubly stochastic. In the experiments, we investigate a broadcast mechanism that transmits information from computing nodes to their neighbors, and confirm the linear convergence of our method on both synthetic and real-world datasets.
Federated Learning with Heterogeneous Data: A Superquantile Optimization Approach
Dec 17, 2021



We present a federated learning framework that is designed to robustly deliver good predictive performance across individual clients with heterogeneous data. The proposed approach hinges upon a superquantile-based learning objective that captures the tail statistics of the error distribution over heterogeneous clients. We present a stochastic training algorithm which interleaves differentially private client reweighting steps with federated averaging steps. The proposed algorithm is supported with finite time convergence guarantees that cover both convex and non-convex settings. Experimental results on benchmark datasets for federated learning demonstrate that our approach is competitive with classical ones in terms of average error and outperforms them in terms of tail statistics of the error.
The Last-Iterate Convergence Rate of Optimistic Mirror Descent in Stochastic Variational Inequalities
Jul 05, 2021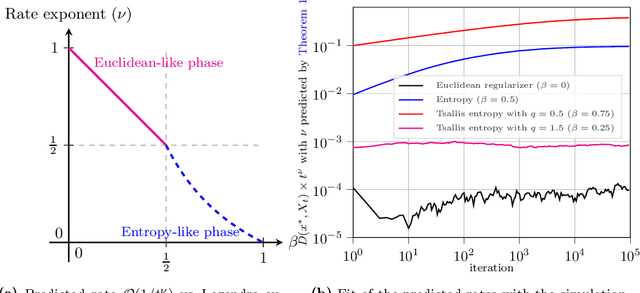
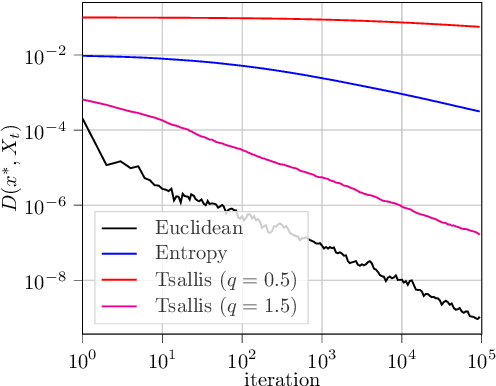
In this paper, we analyze the local convergence rate of optimistic mirror descent methods in stochastic variational inequalities, a class of optimization problems with important applications to learning theory and machine learning. Our analysis reveals an intricate relation between the algorithm's rate of convergence and the local geometry induced by the method's underlying Bregman function. We quantify this relation by means of the Legendre exponent, a notion that we introduce to measure the growth rate of the Bregman divergence relative to the ambient norm near a solution. We show that this exponent determines both the optimal step-size policy of the algorithm and the optimal rates attained, explaining in this way the differences observed for some popular Bregman functions (Euclidean projection, negative entropy, fractional power, etc.).
Optimization in Open Networks via Dual Averaging
May 27, 2021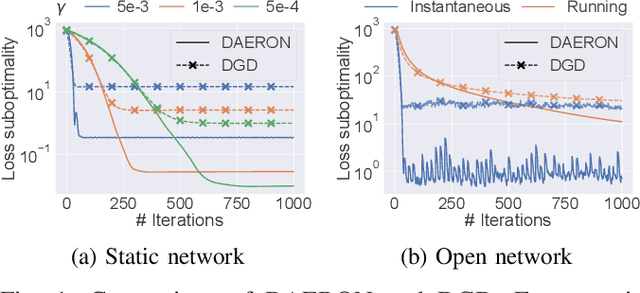
In networks of autonomous agents (e.g., fleets of vehicles, scattered sensors), the problem of minimizing the sum of the agents' local functions has received a lot of interest. We tackle here this distributed optimization problem in the case of open networks when agents can join and leave the network at any time. Leveraging recent online optimization techniques, we propose and analyze the convergence of a decentralized asynchronous optimization method for open networks.