 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeAverage-case Acceleration Through Spectral Density Estimation
Paper and Code
Feb 13, 2020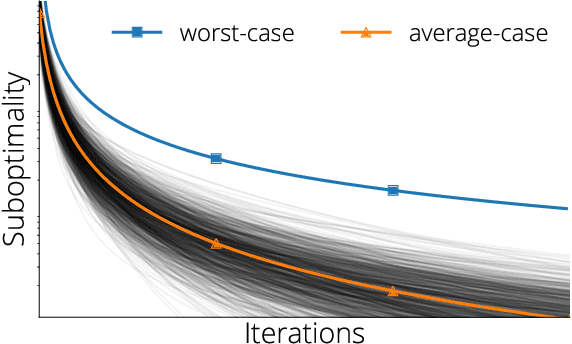
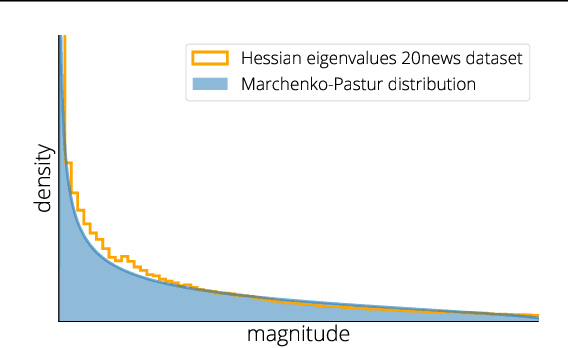
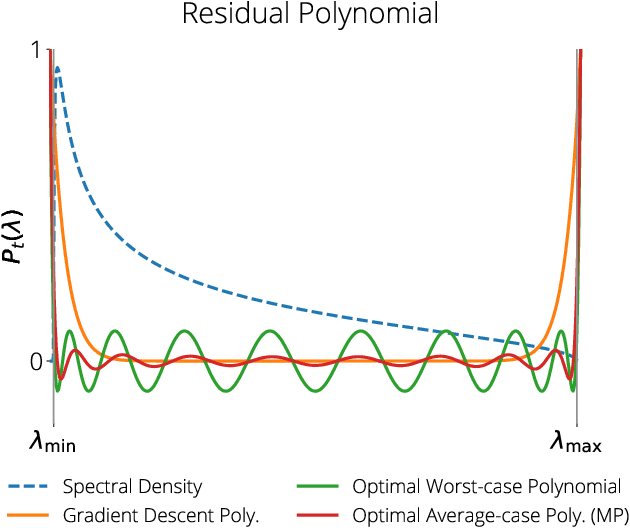
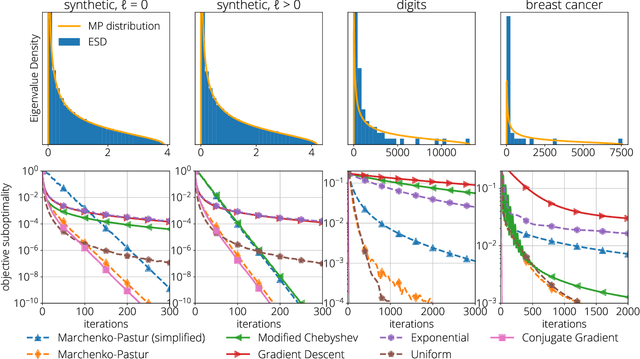
We develop a framework for designing optimal quadratic optimization methods in terms of their average-case runtime. This yields a new class of methods that achieve acceleration through a model of the Hessian's expected spectral density. We develop explicit algorithms for the uniform, Marchenko-Pastur, and exponential distributions. These methods are momentum-based gradient algorithms whose hyper-parameters can be estimated without knowledge of the Hessian's smallest singular value, in contrast with classical accelerated methods like Nesterov acceleration and Polyak momentum. Empirical results on quadratic, logistic regression and neural networks show the proposed methods always match and in many cases significantly improve over classical accelerated methods.