Get our free extension to see links to code for papers anywhere online!Free add-on: code for papers everywhere!Free add-on: See code for papers anywhere!
 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeCtrl-V: Higher Fidelity Video Generation with Bounding-Box Controlled Object Motion
Paper and Code
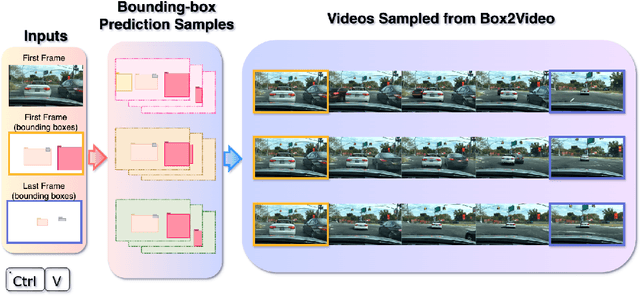
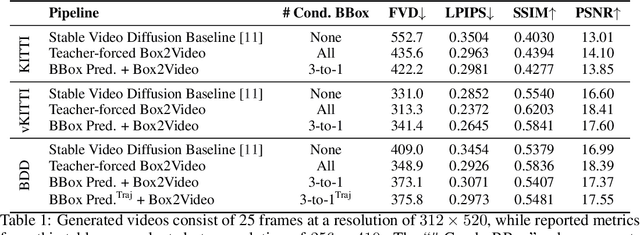


With recent advances in video prediction, controllable video generation has been attracting more attention. Generating high fidelity videos according to simple and flexible conditioning is of particular interest. To this end, we propose a controllable video generation model using pixel level renderings of 2D or 3D bounding boxes as conditioning. In addition, we also create a bounding box predictor that, given the initial and ending frames' bounding boxes, can predict up to 15 bounding boxes per frame for all the frames in a 25-frame clip. We perform experiments across 3 well-known AV video datasets: KITTI, Virtual-KITTI 2 and BDD100k.
View paper on