 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeDynadiff: Single-stage Decoding of Images from Continuously Evolving fMRI
May 20, 2025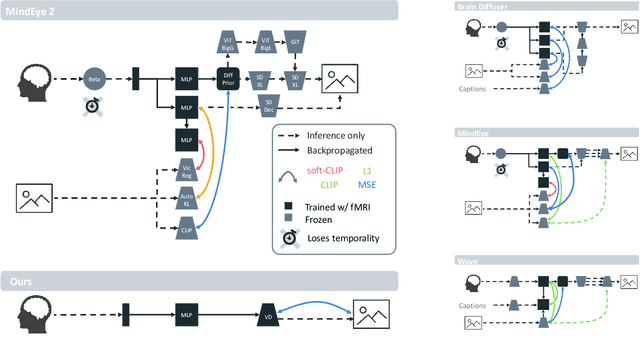

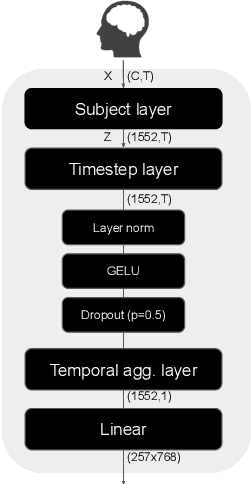

Brain-to-image decoding has been recently propelled by the progress in generative AI models and the availability of large ultra-high field functional Magnetic Resonance Imaging (fMRI). However, current approaches depend on complicated multi-stage pipelines and preprocessing steps that typically collapse the temporal dimension of brain recordings, thereby limiting time-resolved brain decoders. Here, we introduce Dynadiff (Dynamic Neural Activity Diffusion for Image Reconstruction), a new single-stage diffusion model designed for reconstructing images from dynamically evolving fMRI recordings. Our approach offers three main contributions. First, Dynadiff simplifies training as compared to existing approaches. Second, our model outperforms state-of-the-art models on time-resolved fMRI signals, especially on high-level semantic image reconstruction metrics, while remaining competitive on preprocessed fMRI data that collapse time. Third, this approach allows a precise characterization of the evolution of image representations in brain activity. Overall, this work lays the foundation for time-resolved brain-to-image decoding.
Towards image compression with perfect realism at ultra-low bitrates
Oct 16, 2023Image codecs are typically optimized to trade-off bitrate vs, distortion metrics. At low bitrates, this leads to compression artefacts which are easily perceptible, even when training with perceptual or adversarial losses. To improve image quality, and to make it less dependent on the bitrate, we propose to decode with iterative diffusion models, instead of feed-forward decoders trained using MSE or LPIPS distortions used in most neural codecs. In addition to conditioning the model on a vector-quantized image representation, we also condition on a global textual image description to provide additional context. We dub our model PerCo for 'perceptual compression', and compare it to state-of-the-art codecs at rates from 0.1 down to 0.003 bits per pixel. The latter rate is an order of magnitude smaller than those considered in most prior work. At this bitrate a 512x768 Kodak image is encoded in less than 153 bytes. Despite this ultra-low bitrate, our approach maintains the ability to reconstruct realistic images. We find that our model leads to reconstructions with state-of-the-art visual quality as measured by FID and KID, and that the visual quality is less dependent on the bitrate than previous methods.
Zero-shot spatial layout conditioning for text-to-image diffusion models
Jun 23, 2023



Large-scale text-to-image diffusion models have significantly improved the state of the art in generative image modelling and allow for an intuitive and powerful user interface to drive the image generation process. Expressing spatial constraints, e.g. to position specific objects in particular locations, is cumbersome using text; and current text-based image generation models are not able to accurately follow such instructions. In this paper we consider image generation from text associated with segments on the image canvas, which combines an intuitive natural language interface with precise spatial control over the generated content. We propose ZestGuide, a zero-shot segmentation guidance approach that can be plugged into pre-trained text-to-image diffusion models, and does not require any additional training. It leverages implicit segmentation maps that can be extracted from cross-attention layers, and uses them to align the generation with input masks. Our experimental results combine high image quality with accurate alignment of generated content with input segmentations, and improve over prior work both quantitatively and qualitatively, including methods that require training on images with corresponding segmentations. Compared to Paint with Words, the previous state-of-the art in image generation with zero-shot segmentation conditioning, we improve by 5 to 10 mIoU points on the COCO dataset with similar FID scores.
Controllable Image Generation via Collage Representations
Apr 26, 2023Recent advances in conditional generative image models have enabled impressive results. On the one hand, text-based conditional models have achieved remarkable generation quality, by leveraging large-scale datasets of image-text pairs. To enable fine-grained controllability, however, text-based models require long prompts, whose details may be ignored by the model. On the other hand, layout-based conditional models have also witnessed significant advances. These models rely on bounding boxes or segmentation maps for precise spatial conditioning in combination with coarse semantic labels. The semantic labels, however, cannot be used to express detailed appearance characteristics. In this paper, we approach fine-grained scene controllability through image collages which allow a rich visual description of the desired scene as well as the appearance and location of the objects therein, without the need of class nor attribute labels. We introduce "mixing and matching scenes" (M&Ms), an approach that consists of an adversarially trained generative image model which is conditioned on appearance features and spatial positions of the different elements in a collage, and integrates these into a coherent image. We train our model on the OpenImages (OI) dataset and evaluate it on collages derived from OI and MS-COCO datasets. Our experiments on the OI dataset show that M&Ms outperforms baselines in terms of fine-grained scene controllability while being very competitive in terms of image quality and sample diversity. On the MS-COCO dataset, we highlight the generalization ability of our model by outperforming DALL-E in terms of the zero-shot FID metric, despite using two magnitudes fewer parameters and data. Collage based generative models have the potential to advance content creation in an efficient and effective way as they are intuitive to use and yield high quality generations.
Few-shot Semantic Image Synthesis with Class Affinity Transfer
Apr 05, 2023Semantic image synthesis aims to generate photo realistic images given a semantic segmentation map. Despite much recent progress, training them still requires large datasets of images annotated with per-pixel label maps that are extremely tedious to obtain. To alleviate the high annotation cost, we propose a transfer method that leverages a model trained on a large source dataset to improve the learning ability on small target datasets via estimated pairwise relations between source and target classes. The class affinity matrix is introduced as a first layer to the source model to make it compatible with the target label maps, and the source model is then further finetuned for the target domain. To estimate the class affinities we consider different approaches to leverage prior knowledge: semantic segmentation on the source domain, textual label embeddings, and self-supervised vision features. We apply our approach to GAN-based and diffusion-based architectures for semantic synthesis. Our experiments show that the different ways to estimate class affinity can be effectively combined, and that our approach significantly improves over existing state-of-the-art transfer approaches for generative image models.
Unifying conditional and unconditional semantic image synthesis with OCO-GAN
Nov 25, 2022Generative image models have been extensively studied in recent years. In the unconditional setting, they model the marginal distribution from unlabelled images. To allow for more control, image synthesis can be conditioned on semantic segmentation maps that instruct the generator the position of objects in the image. While these two tasks are intimately related, they are generally studied in isolation. We propose OCO-GAN, for Optionally COnditioned GAN, which addresses both tasks in a unified manner, with a shared image synthesis network that can be conditioned either on semantic maps or directly on latents. Trained adversarially in an end-to-end approach with a shared discriminator, we are able to leverage the synergy between both tasks. We experiment with Cityscapes, COCO-Stuff, ADE20K datasets in a limited data, semi-supervised and full data regime and obtain excellent performance, improving over existing hybrid models that can generate both with and without conditioning in all settings. Moreover, our results are competitive or better than state-of-the art specialised unconditional and conditional models.
Instance-Conditioned GAN
Sep 10, 2021
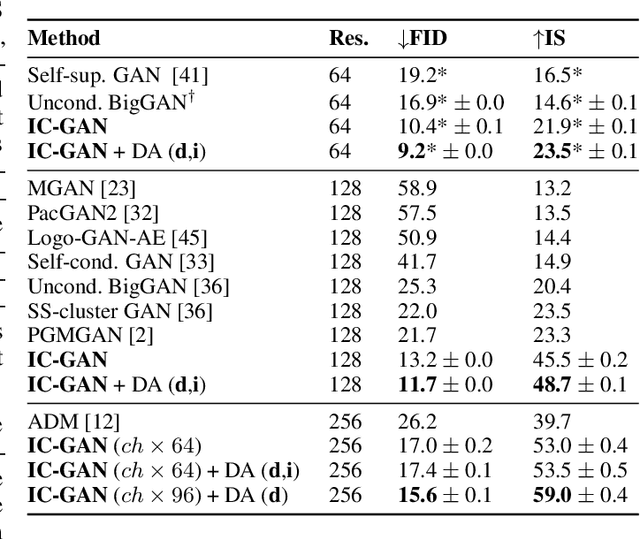

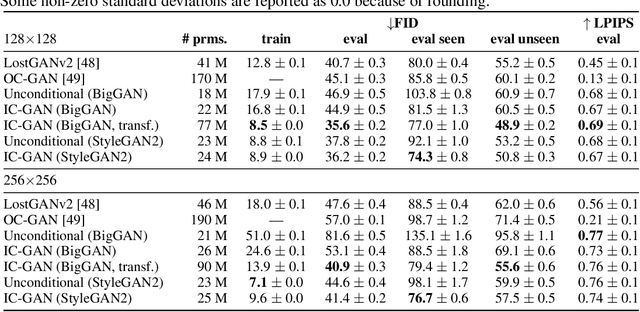
Generative Adversarial Networks (GANs) can generate near photo realistic images in narrow domains such as human faces. Yet, modeling complex distributions of datasets such as ImageNet and COCO-Stuff remains challenging in unconditional settings. In this paper, we take inspiration from kernel density estimation techniques and introduce a non-parametric approach to modeling distributions of complex datasets. We partition the data manifold into a mixture of overlapping neighborhoods described by a datapoint and its nearest neighbors, and introduce a model, called instance-conditioned GAN (IC-GAN), which learns the distribution around each datapoint. Experimental results on ImageNet and COCO-Stuff show that IC-GAN significantly improves over unconditional models and unsupervised data partitioning baselines. Moreover, we show that IC-GAN can effortlessly transfer to datasets not seen during training by simply changing the conditioning instances, and still generate realistic images. Finally, we extend IC-GAN to the class-conditional case and show semantically controllable generation and competitive quantitative results on ImageNet; while improving over BigGAN on ImageNet-LT. We will opensource our code and trained models to reproduce the reported results.