 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeBeyond the Policy Gradient Theorem for Efficient Policy Updates in Actor-Critic Algorithms
Paper and Code
Feb 15, 2022

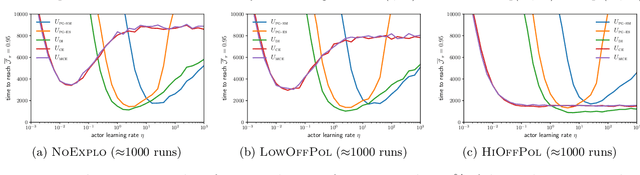
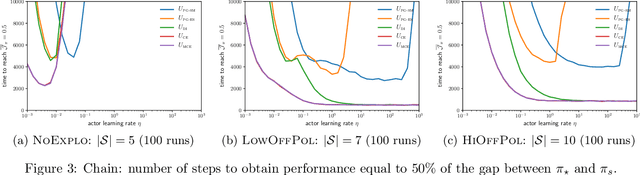
In Reinforcement Learning, the optimal action at a given state is dependent on policy decisions at subsequent states. As a consequence, the learning targets evolve with time and the policy optimization process must be efficient at unlearning what it previously learnt. In this paper, we discover that the policy gradient theorem prescribes policy updates that are slow to unlearn because of their structural symmetry with respect to the value target. To increase the unlearning speed, we study a novel policy update: the gradient of the cross-entropy loss with respect to the action maximizing $q$, but find that such updates may lead to a decrease in value. Consequently, we introduce a modified policy update devoid of that flaw, and prove its guarantees of convergence to global optimality in $\mathcal{O}(t^{-1})$ under classic assumptions. Further, we assess standard policy updates and our cross-entropy policy updates along six analytical dimensions. Finally, we empirically validate our theoretical findings.