 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeBoundary-Aware Vision Transformer for Angiography Vascular Network Segmentation
Jun 15, 2025Accurate segmentation of vascular structures in coronary angiography remains a core challenge in medical image analysis due to the complexity of elongated, thin, and low-contrast vessels. Classical convolutional neural networks (CNNs) often fail to preserve topological continuity, while recent Vision Transformer (ViT)-based models, although strong in global context modeling, lack precise boundary awareness. In this work, we introduce BAVT, a Boundary-Aware Vision Transformer, a ViT-based architecture enhanced with an edge-aware loss that explicitly guides the segmentation toward fine-grained vascular boundaries. Unlike hybrid transformer-CNN models, BAVT retains a minimal, scalable structure that is fully compatible with large-scale vision foundation model (VFM) pretraining. We validate our approach on the DCA-1 coronary angiography dataset, where BAVT achieves superior performance across medical image segmentation metrics outperforming both CNN and hybrid baselines. These results demonstrate the effectiveness of combining plain ViT encoders with boundary-aware supervision for clinical-grade vascular segmentation.
DIPLI: Deep Image Prior Lucky Imaging for Blind Astronomical Image Restoration
Mar 20, 2025



Contemporary image restoration and super-resolution techniques effectively harness deep neural networks, markedly outperforming traditional methods. However, astrophotography presents unique challenges for deep learning due to limited training data. This work explores hybrid strategies, such as the Deep Image Prior (DIP) model, which facilitates blind training but is susceptible to overfitting, artifact generation, and instability when handling noisy images. We propose enhancements to the DIP model's baseline performance through several advanced techniques. First, we refine the model to process multiple frames concurrently, employing the Back Projection method and the TVNet model. Next, we adopt a Markov approach incorporating Monte Carlo estimation, Langevin dynamics, and a variational input technique to achieve unbiased estimates with minimal variance and counteract overfitting effectively. Collectively, these modifications reduce the likelihood of noise learning and mitigate loss function fluctuations during training, enhancing result stability. We validated our algorithm across multiple image sets of astronomical and celestial objects, achieving performance that not only mitigates limitations of Lucky Imaging, a classical computer vision technique that remains a standard in astronomical image reconstruction but surpasses the original DIP model, state of the art transformer- and diffusion-based models, underscoring the significance of our improvements.
PDC-ViT : Source Camera Identification using Pixel Difference Convolution and Vision Transformer
Jan 27, 2025Source camera identification has emerged as a vital solution to unlock incidents involving critical cases like terrorism, violence, and other criminal activities. The ability to trace the origin of an image/video can aid law enforcement agencies in gathering evidence and constructing the timeline of events. Moreover, identifying the owner of a certain device narrows down the area of search in a criminal investigation where smartphone devices are involved. This paper proposes a new pixel-based method for source camera identification, integrating Pixel Difference Convolution (PDC) with a Vision Transformer network (ViT), and named PDC-ViT. While the PDC acts as the backbone for feature extraction by exploiting Angular PDC (APDC) and Radial PDC (RPDC). These techniques enhance the capability to capture subtle variations in pixel information, which are crucial for distinguishing between different source cameras. The second part of the methodology focuses on classification, which is based on a Vision Transformer network. Unlike traditional methods that utilize image patches directly for training the classification network, the proposed approach uniquely inputs PDC features into the Vision Transformer network. To demonstrate the effectiveness of the PDC-ViT approach, it has been assessed on five different datasets, which include various image contents and video scenes. The method has also been compared with state-of-the-art source camera identification methods. Experimental results demonstrate the effectiveness and superiority of the proposed system in terms of accuracy and robustness when compared to its competitors. For example, our proposed PDC-ViT has achieved an accuracy of 94.30%, 84%, 94.22% and 92.29% using the Vision dataset, Daxing dataset, Socrates dataset and QUFVD dataset, respectively.
Advancing Histopathology-Based Breast Cancer Diagnosis: Insights into Multi-Modality and Explainability
Jun 07, 2024It is imperative that breast cancer is detected precisely and timely to improve patient outcomes. Diagnostic methodologies have traditionally relied on unimodal approaches; however, medical data analytics is integrating diverse data sources beyond conventional imaging. Using multi-modal techniques, integrating both image and non-image data, marks a transformative advancement in breast cancer diagnosis. The purpose of this review is to explore the burgeoning field of multimodal techniques, particularly the fusion of histopathology images with non-image data. Further, Explainable AI (XAI) will be used to elucidate the decision-making processes of complex algorithms, emphasizing the necessity of explainability in diagnostic processes. This review utilizes multi-modal data and emphasizes explainability to enhance diagnostic accuracy, clinician confidence, and patient engagement, ultimately fostering more personalized treatment strategies for breast cancer, while also identifying research gaps in multi-modality and explainability, guiding future studies, and contributing to the strategic direction of the field.
FS-Net: Full Scale Network and Adaptive Threshold for Improving Extraction of Micro-Retinal Vessel Structures
Nov 19, 2023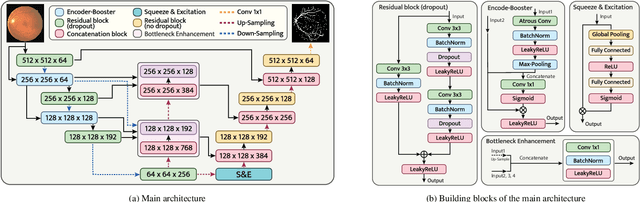

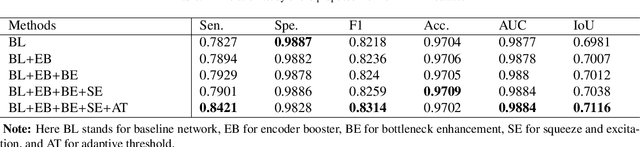
Retinal vascular segmentation, is a widely researched subject in biomedical image processing, aims to relieve ophthalmologists' workload when treating and detecting retinal disorders. However, segmenting retinal vessels has its own set of challenges, with prior techniques failing to generate adequate results when segmenting branches and microvascular structures. The neural network approaches used recently are characterized by the inability to keep local and global properties together and the failure to capture tiny end vessels make it challenging to attain the desired result. To reduce this retinal vessel segmentation problem, we propose a full-scale micro-vessel extraction mechanism based on an encoder-decoder neural network architecture, sigmoid smoothing, and an adaptive threshold method. The network consists of of residual, encoder booster, bottleneck enhancement, squeeze, and excitation building blocks. All of these blocks together help to improve the feature extraction and prediction of the segmentation map. The proposed solution has been evaluated using the DRIVE, CHASE-DB1, and STARE datasets, and competitive results are obtained when compared with previous studies. The AUC and accuracy on the DRIVE dataset are 0.9884 and 0.9702, respectively. On the CHASE-DB1 dataset, the scores are 0.9903 and 0.9755, respectively. On the STARE dataset, the scores are 0.9916 and 0.9750, respectively. The performance achieved is one step ahead of what has been done in previous studies, and this results in a higher chance of having this solution in real-life diagnostic centers that seek ophthalmologists attention.
Convolutional Neural Network-Based Automatic Classification of Colorectal and Prostate Tumor Biopsies Using Multispectral Imagery: System Development Study
Jan 30, 2023Colorectal and prostate cancers are the most common types of cancer in men worldwide. To diagnose colorectal and prostate cancer, a pathologist performs a histological analysis on needle biopsy samples. This manual process is time-consuming and error-prone, resulting in high intra and interobserver variability, which affects diagnosis reliability. This study aims to develop an automatic computerized system for diagnosing colorectal and prostate tumors by using images of biopsy samples to reduce time and diagnosis error rates associated with human analysis. We propose a CNN model for classifying colorectal and prostate tumors from multispectral images of biopsy samples. The key idea was to remove the last block of the convolutional layers and halve the number of filters per layer. Our results showed excellent performance, with an average test accuracy of 99.8% and 99.5% for the prostate and colorectal data sets, respectively. The system showed excellent performance when compared with pretrained CNNs and other classification methods, as it avoids the preprocessing phase while using a single CNN model for classification. Overall, the proposed CNN architecture was globally the best-performing system for classifying colorectal and prostate tumor images. The proposed CNN was detailed and compared with previously trained network models used as feature extractors. These CNNs were also compared with other classification techniques. As opposed to pretrained CNNs and other classification approaches, the proposed CNN yielded excellent results. The computational complexity of the CNNs was also investigated, it was shown that the proposed CNN is better at classifying images than pretrained networks because it does not require preprocessing. Thus, the overall analysis was that the proposed CNN architecture was globally the best-performing system for classifying colorectal and prostate tumor images.
Explainable, Domain-Adaptive, and Federated Artificial Intelligence in Medicine
Nov 17, 2022



Artificial intelligence (AI) continues to transform data analysis in many domains. Progress in each domain is driven by a growing body of annotated data, increased computational resources, and technological innovations. In medicine, the sensitivity of the data, the complexity of the tasks, the potentially high stakes, and a requirement of accountability give rise to a particular set of challenges. In this review, we focus on three key methodological approaches that address some of the particular challenges in AI-driven medical decision making. (1) Explainable AI aims to produce a human-interpretable justification for each output. Such models increase confidence if the results appear plausible and match the clinicians expectations. However, the absence of a plausible explanation does not imply an inaccurate model. Especially in highly non-linear, complex models that are tuned to maximize accuracy, such interpretable representations only reflect a small portion of the justification. (2) Domain adaptation and transfer learning enable AI models to be trained and applied across multiple domains. For example, a classification task based on images acquired on different acquisition hardware. (3) Federated learning enables learning large-scale models without exposing sensitive personal health information. Unlike centralized AI learning, where the centralized learning machine has access to the entire training data, the federated learning process iteratively updates models across multiple sites by exchanging only parameter updates, not personal health data. This narrative review covers the basic concepts, highlights relevant corner-stone and state-of-the-art research in the field, and discusses perspectives.
Gaze Estimation Approach Using Deep Differential Residual Network
Aug 08, 2022

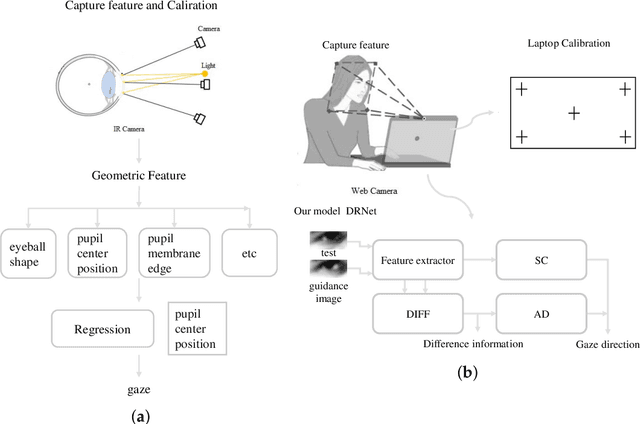
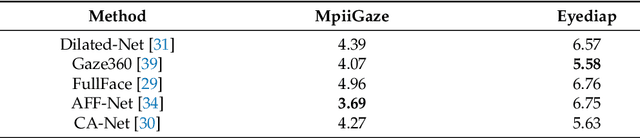
Gaze estimation, which is a method to determine where a person is looking at given the person's full face, is a valuable clue for understanding human intention. Similarly to other domains of computer vision, deep learning (DL) methods have gained recognition in the gaze estimation domain. However, there are still gaze calibration problems in the gaze estimation domain, thus preventing existing methods from further improving the performances. An effective solution is to directly predict the difference information of two human eyes, such as the differential network (Diff-Nn). However, this solution results in a loss of accuracy when using only one inference image. We propose a differential residual model (DRNet) combined with a new loss function to make use of the difference information of two eye images. We treat the difference information as auxiliary information. We assess the proposed model (DRNet) mainly using two public datasets (1) MpiiGaze and (2) Eyediap. Considering only the eye features, DRNet outperforms the state-of-the-art gaze estimation methods with $angular-error$ of 4.57 and 6.14 using MpiiGaze and Eyediap datasets, respectively. Furthermore, the experimental results also demonstrate that DRNet is extremely robust to noise images.
Private Facial Diagnosis as an Edge Service for Parkinson's DBS Treatment Valuation
May 16, 2021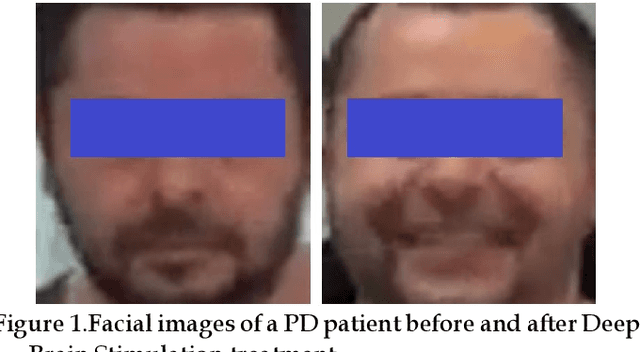

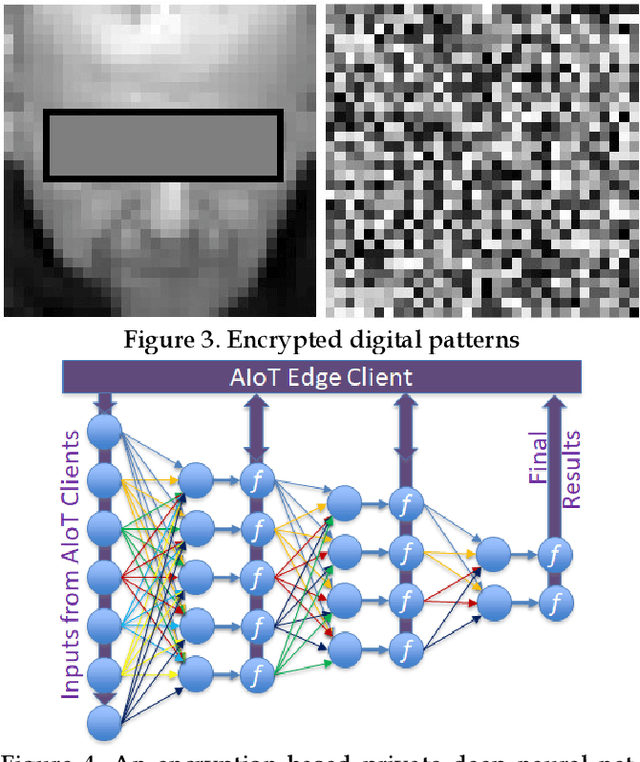

Facial phenotyping has recently been successfully exploited for medical diagnosis as a novel way to diagnose a range of diseases, where facial biometrics has been revealed to have rich links to underlying genetic or medical causes. In this paper, taking Parkinson's Diseases (PD) as a case study, we proposed an Artificial-Intelligence-of-Things (AIoT) edge-oriented privacy-preserving facial diagnosis framework to analyze the treatment of Deep Brain Stimulation (DBS) on PD patients. In the proposed framework, a new edge-based information theoretically secure framework is proposed to implement private deep facial diagnosis as a service over a privacy-preserving AIoT-oriented multi-party communication scheme, where partial homomorphic encryption (PHE) is leveraged to enable privacy-preserving deep facial diagnosis directly on encrypted facial patterns. In our experiments with a collected facial dataset from PD patients, for the first time, we demonstrated that facial patterns could be used to valuate the improvement of PD patients undergoing DBS treatment. We further implemented a privacy-preserving deep facial diagnosis framework that can achieve the same accuracy as the non-encrypted one, showing the potential of our privacy-preserving facial diagnosis as an trustworthy edge service for grading the severity of PD in patients.
Computer-Aided Automated Detection of Gene-Controlled Social Actions of Drosophila
Sep 11, 2019

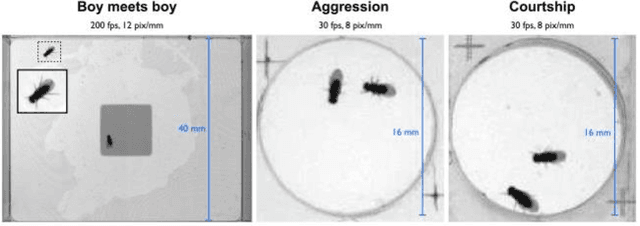
Gene expression of social actions in Drosophilae has been attracting wide interest from biologists, medical scientists and psychologists. Gene-edited Drosophilae have been used as a test platform for experimental investigation. For example, Parkinson's genes can be embedded into a group of newly bred Drosophilae for research purpose. However, human observation of numerous tiny Drosophilae for a long term is an arduous work, and the dependence on human's acute perception is highly unreliable. As a result, an automated system of social action detection using machine learning has been highly demanded. In this study, we propose to automate the detection and classification of two innate aggressive actions demonstrated by Drosophilae. Robust keypoint detection is achieved using selective spatio-temporal interest points (sSTIP) which are then described using the 3D Scale Invariant Feature Transform (3D-SIFT) descriptors. Dimensionality reduction is performed using Spectral Regression Kernel Discriminant Analysis (SR-KDA) and classification is done using the nearest centre rule. The classification accuracy shown demonstrates the feasibility of the proposed system.
* published on International Conference on Smart Cities at Cambridge 2018