 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeFiMI: A Domain-Specific Language Model for Indian Finance Ecosystem
Feb 05, 2026We present FiMI (Finance Model for India), a domain-specialized financial language model developed for Indian digital payment systems. We develop two model variants: FiMI Base and FiMI Instruct. FiMI adapts the Mistral Small 24B architecture through a multi-stage training pipeline, beginning with continuous pre-training on 68 Billion tokens of curated financial, multilingual (English, Hindi, Hinglish), and synthetic data. This is followed by instruction fine-tuning and domain-specific supervised fine-tuning focused on multi-turn, tool-driven conversations that model real-world workflows, such as transaction disputes and mandate lifecycle management. Evaluations reveal that FiMI Base achieves a 20% improvement over the Mistral Small 24B Base model on finance reasoning benchmark, while FiMI Instruct outperforms the Mistral Small 24B Instruct model by 87% on domain-specific tool-calling. Moreover, FiMI achieves these significant domain gains while maintaining comparable performance to models of similar size on general benchmarks.
Boundary-Aware Vision Transformer for Angiography Vascular Network Segmentation
Jun 15, 2025Accurate segmentation of vascular structures in coronary angiography remains a core challenge in medical image analysis due to the complexity of elongated, thin, and low-contrast vessels. Classical convolutional neural networks (CNNs) often fail to preserve topological continuity, while recent Vision Transformer (ViT)-based models, although strong in global context modeling, lack precise boundary awareness. In this work, we introduce BAVT, a Boundary-Aware Vision Transformer, a ViT-based architecture enhanced with an edge-aware loss that explicitly guides the segmentation toward fine-grained vascular boundaries. Unlike hybrid transformer-CNN models, BAVT retains a minimal, scalable structure that is fully compatible with large-scale vision foundation model (VFM) pretraining. We validate our approach on the DCA-1 coronary angiography dataset, where BAVT achieves superior performance across medical image segmentation metrics outperforming both CNN and hybrid baselines. These results demonstrate the effectiveness of combining plain ViT encoders with boundary-aware supervision for clinical-grade vascular segmentation.
DIPLI: Deep Image Prior Lucky Imaging for Blind Astronomical Image Restoration
Mar 20, 2025



Contemporary image restoration and super-resolution techniques effectively harness deep neural networks, markedly outperforming traditional methods. However, astrophotography presents unique challenges for deep learning due to limited training data. This work explores hybrid strategies, such as the Deep Image Prior (DIP) model, which facilitates blind training but is susceptible to overfitting, artifact generation, and instability when handling noisy images. We propose enhancements to the DIP model's baseline performance through several advanced techniques. First, we refine the model to process multiple frames concurrently, employing the Back Projection method and the TVNet model. Next, we adopt a Markov approach incorporating Monte Carlo estimation, Langevin dynamics, and a variational input technique to achieve unbiased estimates with minimal variance and counteract overfitting effectively. Collectively, these modifications reduce the likelihood of noise learning and mitigate loss function fluctuations during training, enhancing result stability. We validated our algorithm across multiple image sets of astronomical and celestial objects, achieving performance that not only mitigates limitations of Lucky Imaging, a classical computer vision technique that remains a standard in astronomical image reconstruction but surpasses the original DIP model, state of the art transformer- and diffusion-based models, underscoring the significance of our improvements.
SOAR: Advancements in Small Body Object Detection for Aerial Imagery Using State Space Models and Programmable Gradients
May 06, 2024



Small object detection in aerial imagery presents significant challenges in computer vision due to the minimal data inherent in small-sized objects and their propensity to be obscured by larger objects and background noise. Traditional methods using transformer-based models often face limitations stemming from the lack of specialized databases, which adversely affect their performance with objects of varying orientations and scales. This underscores the need for more adaptable, lightweight models. In response, this paper introduces two innovative approaches that significantly enhance detection and segmentation capabilities for small aerial objects. Firstly, we explore the use of the SAHI framework on the newly introduced lightweight YOLO v9 architecture, which utilizes Programmable Gradient Information (PGI) to reduce the substantial information loss typically encountered in sequential feature extraction processes. The paper employs the Vision Mamba model, which incorporates position embeddings to facilitate precise location-aware visual understanding, combined with a novel bidirectional State Space Model (SSM) for effective visual context modeling. This State Space Model adeptly harnesses the linear complexity of CNNs and the global receptive field of Transformers, making it particularly effective in remote sensing image classification. Our experimental results demonstrate substantial improvements in detection accuracy and processing efficiency, validating the applicability of these approaches for real-time small object detection across diverse aerial scenarios. This paper also discusses how these methodologies could serve as foundational models for future advancements in aerial object recognition technologies. The source code will be made accessible here.
ICML 2023 Topological Deep Learning Challenge : Design and Results
Oct 02, 2023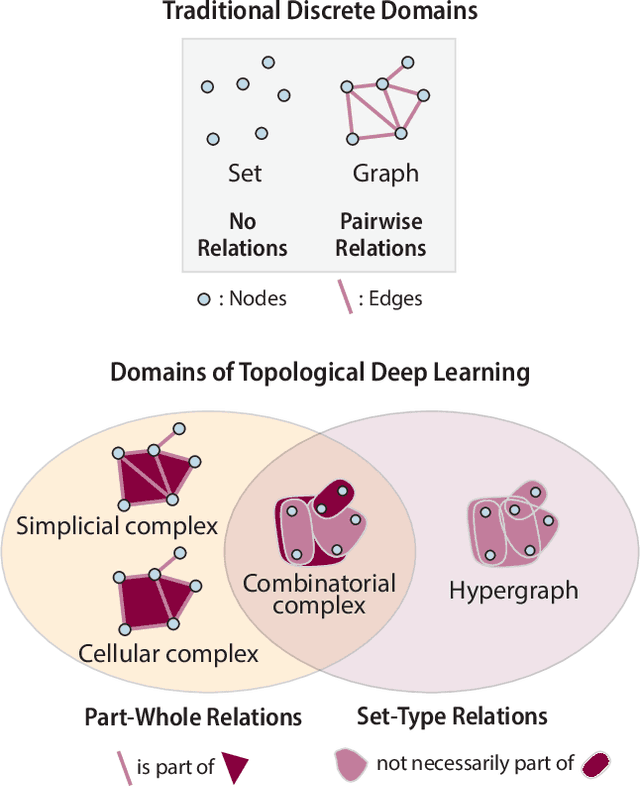
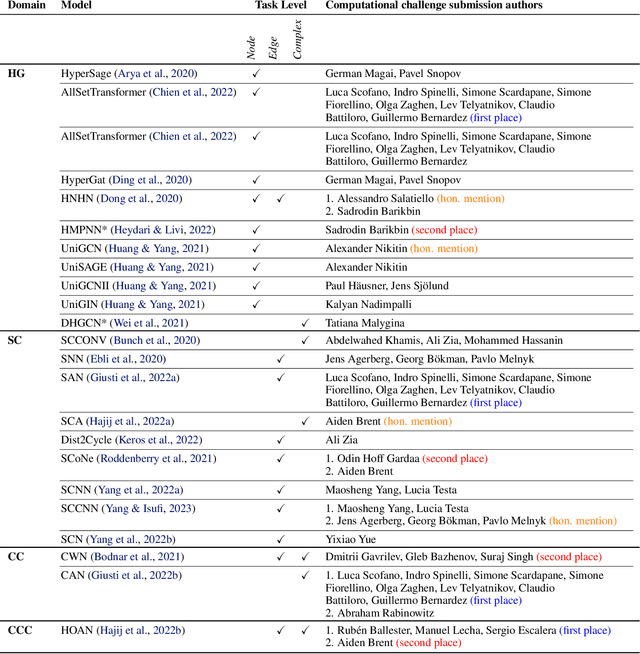
This paper presents the computational challenge on topological deep learning that was hosted within the ICML 2023 Workshop on Topology and Geometry in Machine Learning. The competition asked participants to provide open-source implementations of topological neural networks from the literature by contributing to the python packages TopoNetX (data processing) and TopoModelX (deep learning). The challenge attracted twenty-eight qualifying submissions in its two-month duration. This paper describes the design of the challenge and summarizes its main findings.