 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgePDC-ViT : Source Camera Identification using Pixel Difference Convolution and Vision Transformer
Jan 27, 2025Source camera identification has emerged as a vital solution to unlock incidents involving critical cases like terrorism, violence, and other criminal activities. The ability to trace the origin of an image/video can aid law enforcement agencies in gathering evidence and constructing the timeline of events. Moreover, identifying the owner of a certain device narrows down the area of search in a criminal investigation where smartphone devices are involved. This paper proposes a new pixel-based method for source camera identification, integrating Pixel Difference Convolution (PDC) with a Vision Transformer network (ViT), and named PDC-ViT. While the PDC acts as the backbone for feature extraction by exploiting Angular PDC (APDC) and Radial PDC (RPDC). These techniques enhance the capability to capture subtle variations in pixel information, which are crucial for distinguishing between different source cameras. The second part of the methodology focuses on classification, which is based on a Vision Transformer network. Unlike traditional methods that utilize image patches directly for training the classification network, the proposed approach uniquely inputs PDC features into the Vision Transformer network. To demonstrate the effectiveness of the PDC-ViT approach, it has been assessed on five different datasets, which include various image contents and video scenes. The method has also been compared with state-of-the-art source camera identification methods. Experimental results demonstrate the effectiveness and superiority of the proposed system in terms of accuracy and robustness when compared to its competitors. For example, our proposed PDC-ViT has achieved an accuracy of 94.30%, 84%, 94.22% and 92.29% using the Vision dataset, Daxing dataset, Socrates dataset and QUFVD dataset, respectively.
Multimodal Ensemble with Conditional Feature Fusion for Dysgraphia Diagnosis in Children from Handwriting Samples
Aug 25, 2024Developmental dysgraphia is a neurological disorder that hinders children's writing skills. In recent years, researchers have increasingly explored machine learning methods to support the diagnosis of dysgraphia based on offline and online handwriting. In most previous studies, the two types of handwriting have been analysed separately, which does not necessarily lead to promising results. In this way, the relationship between online and offline data cannot be explored. To address this limitation, we propose a novel multimodal machine learning approach utilizing both online and offline handwriting data. We created a new dataset by transforming an existing online handwritten dataset, generating corresponding offline handwriting images. We considered only different types of word data (simple word, pseudoword & difficult word) in our multimodal analysis. We trained SVM and XGBoost classifiers separately on online and offline features as well as implemented multimodal feature fusion and soft-voted ensemble. Furthermore, we proposed a novel ensemble with conditional feature fusion method which intelligently combines predictions from online and offline classifiers, selectively incorporating feature fusion when confidence scores fall below a threshold. Our novel approach achieves an accuracy of 88.8%, outperforming SVMs for single modalities by 12-14%, existing methods by 8-9%, and traditional multimodal approaches (soft-vote ensemble and feature fusion) by 3% and 5%, respectively. Our methodology contributes to the development of accurate and efficient dysgraphia diagnosis tools, requiring only a single instance of multimodal word/pseudoword data to determine the handwriting impairment. This work highlights the potential of multimodal learning in enhancing dysgraphia diagnosis, paving the way for accessible and practical diagnostic tools.
Advancing Histopathology-Based Breast Cancer Diagnosis: Insights into Multi-Modality and Explainability
Jun 07, 2024It is imperative that breast cancer is detected precisely and timely to improve patient outcomes. Diagnostic methodologies have traditionally relied on unimodal approaches; however, medical data analytics is integrating diverse data sources beyond conventional imaging. Using multi-modal techniques, integrating both image and non-image data, marks a transformative advancement in breast cancer diagnosis. The purpose of this review is to explore the burgeoning field of multimodal techniques, particularly the fusion of histopathology images with non-image data. Further, Explainable AI (XAI) will be used to elucidate the decision-making processes of complex algorithms, emphasizing the necessity of explainability in diagnostic processes. This review utilizes multi-modal data and emphasizes explainability to enhance diagnostic accuracy, clinician confidence, and patient engagement, ultimately fostering more personalized treatment strategies for breast cancer, while also identifying research gaps in multi-modality and explainability, guiding future studies, and contributing to the strategic direction of the field.
Backbones-Review: Feature Extraction Networks for Deep Learning and Deep Reinforcement Learning Approaches
Jun 16, 2022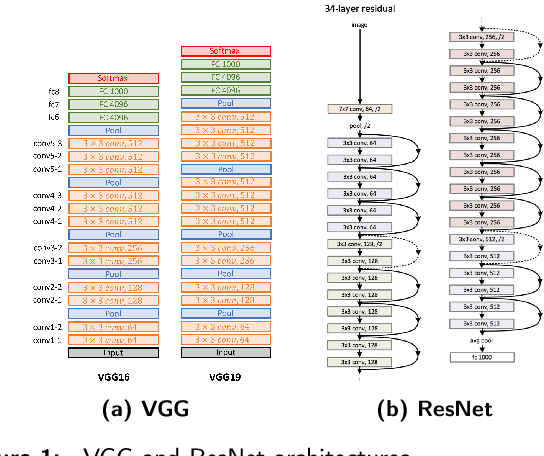

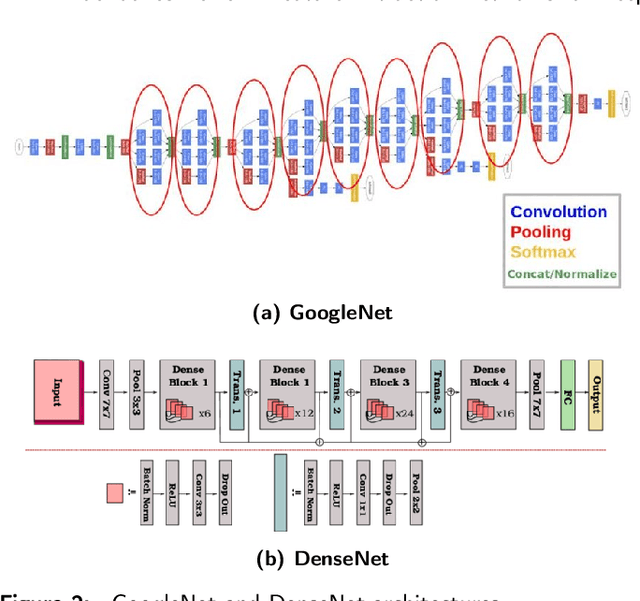
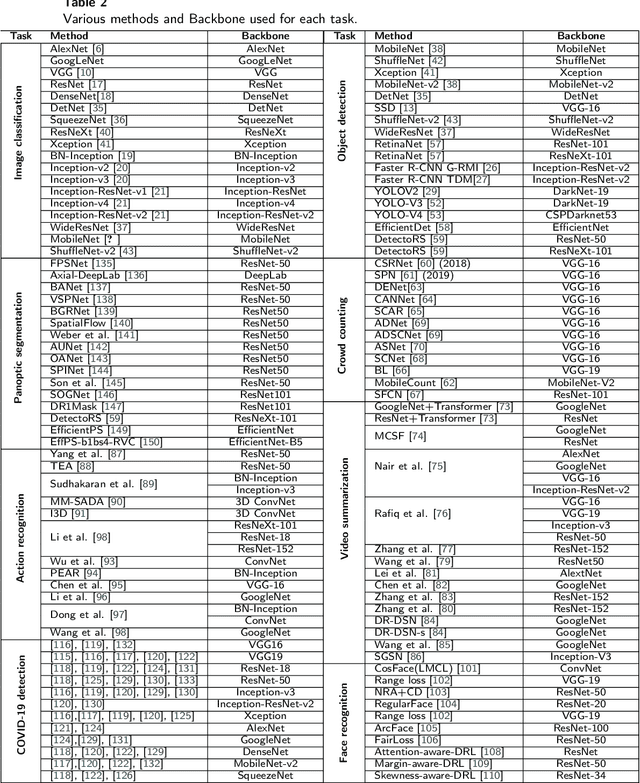
To understand the real world using various types of data, Artificial Intelligence (AI) is the most used technique nowadays. While finding the pattern within the analyzed data represents the main task. This is performed by extracting representative features step, which is proceeded using the statistical algorithms or using some specific filters. However, the selection of useful features from large-scale data represented a crucial challenge. Now, with the development of convolution neural networks (CNNs), the feature extraction operation has become more automatic and easier. CNNs allow to work on large-scale size of data, as well as cover different scenarios for a specific task. For computer vision tasks, convolutional networks are used to extract features also for the other parts of a deep learning model. The selection of a suitable network for feature extraction or the other parts of a DL model is not random work. So, the implementation of such a model can be related to the target task as well as the computational complexity of it. Many networks have been proposed and become the famous networks used for any DL models in any AI task. These networks are exploited for feature extraction or at the beginning of any DL model which is named backbones. A backbone is a known network trained in many other tasks before and demonstrates its effectiveness. In this paper, an overview of the existing backbones, e.g. VGGs, ResNets, DenseNet, etc, is given with a detailed description. Also, a couple of computer vision tasks are discussed by providing a review of each task regarding the backbones used. In addition, a comparison in terms of performance is also provided, based on the backbone used for each task.
Image inpainting: A review
Sep 13, 2019
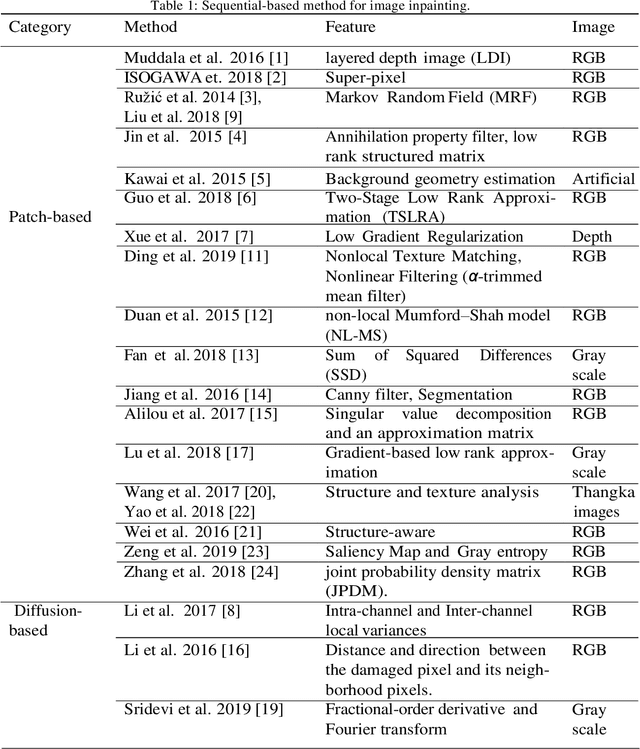

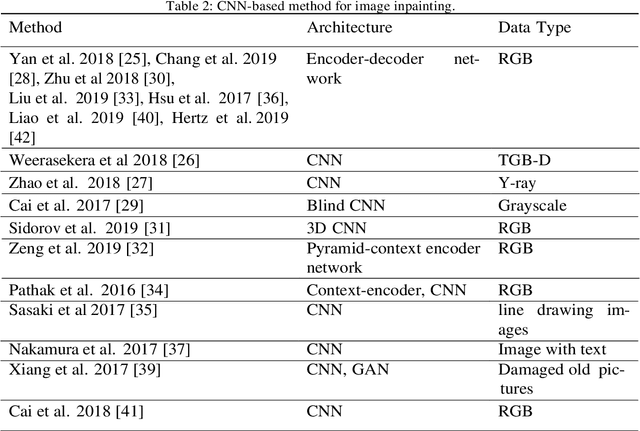
Although image inpainting, or the art of repairing the old and deteriorated images, has been around for many years, it has gained even more popularity because of the recent development in image processing techniques. With the improvement of image processing tools and the flexibility of digital image editing, automatic image inpainting has found important applications in computer vision and has also become an important and challenging topic of research in image processing. This paper is a brief review of the existing image inpainting approaches we first present a global vision on the existing methods for image inpainting. We attempt to collect most of the existing approaches and classify them into three categories, namely, sequential-based, CNN-based and GAN-based methods. In addition, for each category, a list of methods for the different types of distortion on the images is presented. Furthermore, collect a list of the available datasets and discuss these in our paper. This is a contribution for digital image inpainting researchers trying to look for the available datasets because there is a lack of datasets available for image inpainting. As the final step in this overview, we present the results of real evaluations of the three categories of image inpainting methods performed on the datasets used, for the different types of image distortion. In the end, we also present the evaluations metrics and discuss the performance of these methods in terms of these metrics. This overview can be used as a reference for image inpainting researchers, and it can also facilitate the comparison of the methods as well as the datasets used. The main contribution of this paper is the presentation of the three categories of image inpainting methods along with a list of available datasets that the researchers can use to evaluate their proposed methodology against.