 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeMMTM: Tri-Modal Topic Modeling for Long-Form Video via Similarity-Gated Fusion
May 28, 2026We introduce MMTM, a modular pipeline for topic discovery in long-form video that integrates speech recognition, audio and visual embeddings, and BERTopic clustering through a deterministic similarity-gated fusion. Evaluated cross-lingually on German (Tagesschau) and English (NBC) broadcast news, joint tri-modal modeling substantially improves topic quality: noise drops from 0.27 to 0.06, transition rate from 0.70 to 0.21, and normalized entropy rises from 0.84 to 0.92, indicating more coherent and temporally stable topics. Cluster validity (Calinski-Harabasz) improves by 5-12X across embedding spaces. Lexical coherence (NPMI) rises from 0.77 to 0.86 on German but is corpus-dependent and does not transfer to the shorter NBC broadcasts. We release the pipeline code and a human-validated 54-hour multimodal video topic corpus with dual-annotator visual evaluation and LLM-assisted labeling.
Large Language Models Decide Early and Explain Later
Apr 24, 2026Large Language Models often achieve strong performance by generating long intermediate chain-of-thought reasoning. However, it remains unclear when a model's final answer is actually determined during generation. If the answer is already fixed at an intermediate stage, subsequent reasoning tokens may constitute post-decision explanation, increasing inference cost and latency without improving correctness. We study the evolution of predicted answers over reasoning steps using forced answer completion, which elicits the model's intermediate predictions at partial reasoning prefixes. Focusing on Qwen3-4B and averaging results across all datasets considered, we find that predicted answers change in only 32% of queries. Moreover, once the final answer switch occurs, the model generates an average of 760 additional reasoning tokens per query, accounting for a substantial fraction of the total reasoning budget. Motivated by these findings, we investigate early stopping strategies that halt generation once the answer has stabilized. We show that simple heuristics, including probe-based stopping, can reduce reasoning token usage by 500 tokens per query while incurring only a 2% drop in accuracy. Together, our results indicate that a large portion of chain-of-thought generation is redundant and can be reduced with minimal impact on performance.
From Early Encoding to Late Suppression: Interpreting LLMs on Character Counting Tasks
Apr 01, 2026Large language models (LLMs) exhibit failures on elementary symbolic tasks such as character counting in a word, despite excelling on complex benchmarks. Although this limitation has been noted, the internal reasons remain unclear. We use character counting (e.g., "How many p's are in apple?") as a minimal, controlled probe that isolates token-level reasoning from higher-level confounds. Using this setting, we uncover a consistent phenomenon across modern architectures, including LLaMA, Qwen, and Gemma: models often compute the correct answer internally yet fail to express it at the output layer. Through mechanistic analysis combining probing classifiers, activation patching, logit lens analysis, and attention head tracing, we show that character-level information is encoded in early and mid-layer representations. However, this information is attenuated by a small set of components in later layers, especially the penultimate and final layer MLP. We identify these components as negative circuits: subnetworks that downweight correct signals in favor of higher-probability but incorrect outputs. Our results lead to two contributions. First, we show that symbolic reasoning failures in LLMs are not due to missing representations or insufficient scale, but arise from structured interference within the model's computation graph. This explains why such errors persist and can worsen under scaling and instruction tuning. Second, we provide evidence that LLM forward passes implement a form of competitive decoding, in which correct and incorrect hypotheses coexist and are dynamically reweighted, with final outputs determined by suppression as much as by amplification. These findings carry implications for interpretability and robustness: simple symbolic reasoning exposes weaknesses in modern LLMs, underscoring need for design strategies that ensure information is encoded and reliably used.
Extending a Parliamentary Corpus with MPs' Tweets: Automatic Annotation and Evaluation Using MultiParTweet
Dec 12, 2025Social media serves as a critical medium in modern politics because it both reflects politicians' ideologies and facilitates communication with younger generations. We present MultiParTweet, a multilingual tweet corpus from X that connects politicians' social media discourse with German political corpus GerParCor, thereby enabling comparative analyses between online communication and parliamentary debates. MultiParTweet contains 39 546 tweets, including 19 056 media items. Furthermore, we enriched the annotation with nine text-based models and one vision-language model (VLM) to annotate MultiParTweet with emotion, sentiment, and topic annotations. Moreover, the automated annotations are evaluated against a manually annotated subset. MultiParTweet can be reconstructed using our tool, TTLABTweetCrawler, which provides a framework for collecting data from X. To demonstrate a methodological demonstration, we examine whether the models can predict each other using the outputs of the remaining models. In summary, we provide MultiParTweet, a resource integrating automatic text and media-based annotations validated with human annotations, and TTLABTweetCrawler, a general-purpose X data collection tool. Our analysis shows that the models are mutually predictable. In addition, VLM-based annotation were preferred by human annotators, suggesting that multimodal representations align more with human interpretation.
Finding Needles in Emb(a)dding Haystacks: Legal Document Retrieval via Bagging and SVR Ensembles
Jan 09, 2025We introduce a retrieval approach leveraging Support Vector Regression (SVR) ensembles, bootstrap aggregation (bagging), and embedding spaces on the German Dataset for Legal Information Retrieval (GerDaLIR). By conceptualizing the retrieval task in terms of multiple binary needle-in-a-haystack subtasks, we show improved recall over the baselines (0.849 > 0.803 | 0.829) using our voting ensemble, suggesting promising initial results, without training or fine-tuning any deep learning models. Our approach holds potential for further enhancement, particularly through refining the encoding models and optimizing hyperparameters.
You Shall Know a Tool by the Traces it Leaves: The Predictability of Sentiment Analysis Tools
Oct 18, 2024



If sentiment analysis tools were valid classifiers, one would expect them to provide comparable results for sentiment classification on different kinds of corpora and for different languages. In line with results of previous studies we show that sentiment analysis tools disagree on the same dataset. Going beyond previous studies we show that the sentiment tool used for sentiment annotation can even be predicted from its outcome, revealing an algorithmic bias of sentiment analysis. Based on Twitter, Wikipedia and different news corpora from the English, German and French languages, our classifiers separate sentiment tools with an averaged F1-score of 0.89 (for the English corpora). We therefore warn against taking sentiment annotations as face value and argue for the need of more and systematic NLP evaluation studies.
Iconic Gesture Semantics
Apr 29, 2024The "meaning" of an iconic gesture is conditioned on its informational evaluation. Only informational evaluation lifts a gesture to a quasi-linguistic level that can interact with verbal content. Interaction is either vacuous or regimented by usual lexicon-driven inferences. Informational evaluation is spelled out as extended exemplification (extemplification) in terms of perceptual classification of a gesture's visual iconic model. The iconic model is derived from Frege/Montague-like truth-functional evaluation of a gesture's form within spatially extended domains. We further argue that the perceptual classification of instances of visual communication requires a notion of meaning different from Frege/Montague frameworks. Therefore, a heuristic for gesture interpretation is provided that can guide the working semanticist. In sum, an iconic gesture semantics is introduced which covers the full range from kinematic gesture representations over model-theoretic evaluation to inferential interpretation in dynamic semantic frameworks.
Syntactic Language Change in English and German: Metrics, Parsers, and Convergences
Feb 18, 2024



Many studies have shown that human languages tend to optimize for lower complexity and increased communication efficiency. Syntactic dependency distance, which measures the linear distance between dependent words, is often considered a key indicator of language processing difficulty and working memory load. The current paper looks at diachronic trends in syntactic language change in both English and German, using corpora of parliamentary debates from the last c. 160 years. We base our observations on five dependency parsers, including the widely used Stanford CoreNLP as well as 4 newer alternatives. Our analysis of syntactic language change goes beyond linear dependency distance and explores 15 metrics relevant to dependency distance minimization (DDM) and/or based on tree graph properties, such as the tree height and degree variance. Even though we have evidence that recent parsers trained on modern treebanks are not heavily affected by data 'noise' such as spelling changes and OCR errors in our historic data, we find that results of syntactic language change are sensitive to the parsers involved, which is a caution against using a single parser for evaluating syntactic language change as done in previous work. We also show that syntactic language change over the time period investigated is largely similar between English and German across the different metrics explored: only 4% of cases we examine yield opposite conclusions regarding upwards and downtrends of syntactic metrics across German and English. We also show that changes in syntactic measures seem to be more frequent at the tails of sentence length distributions. To our best knowledge, ours is the most comprehensive analysis of syntactic language using modern NLP technology in recent corpora of English and German.
German Parliamentary Corpus (GerParCor)
Apr 21, 2022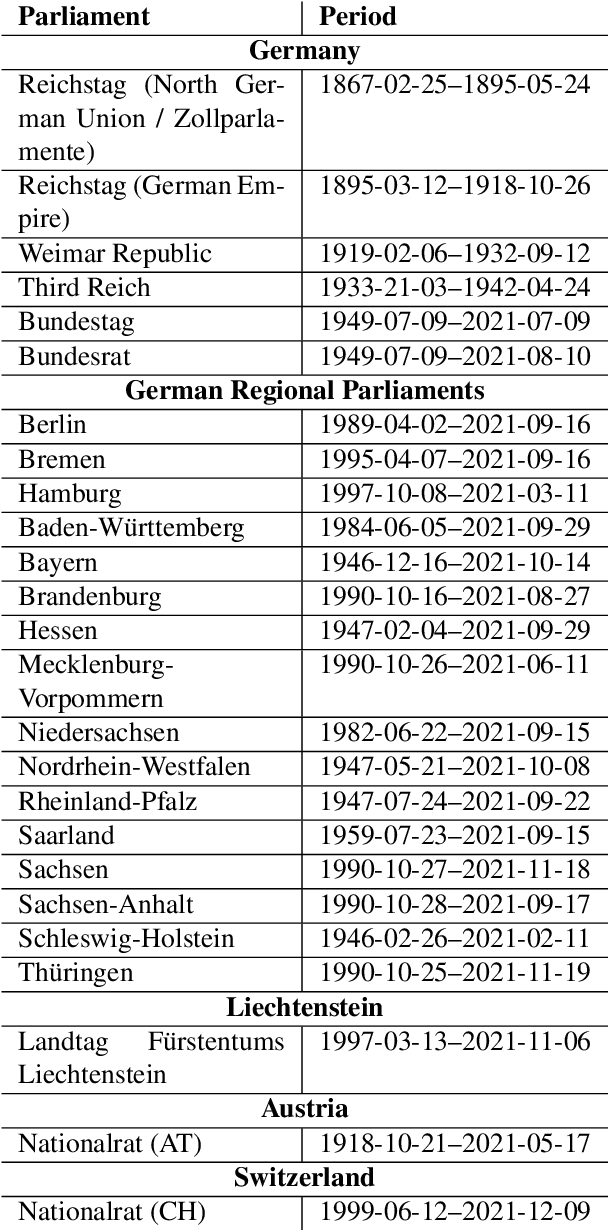
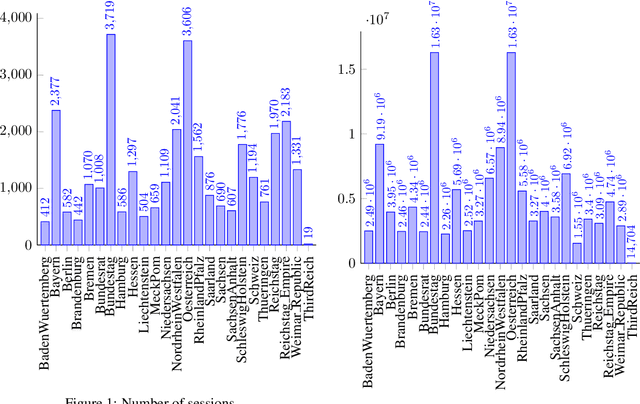
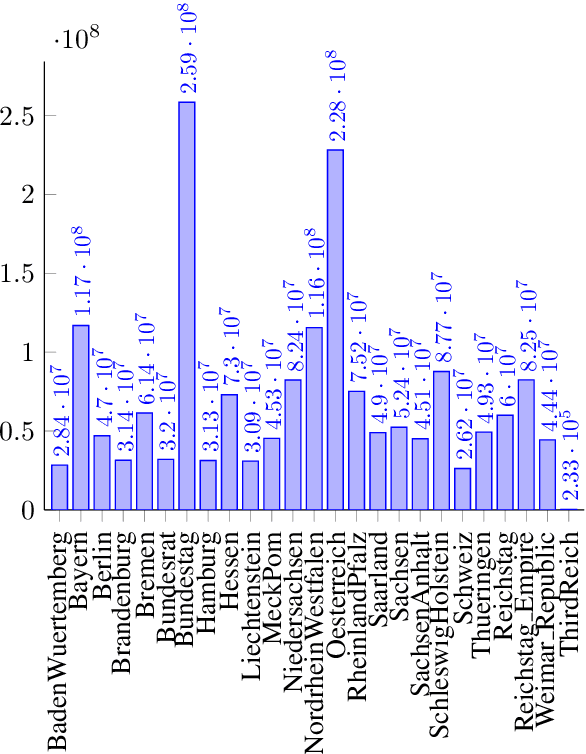
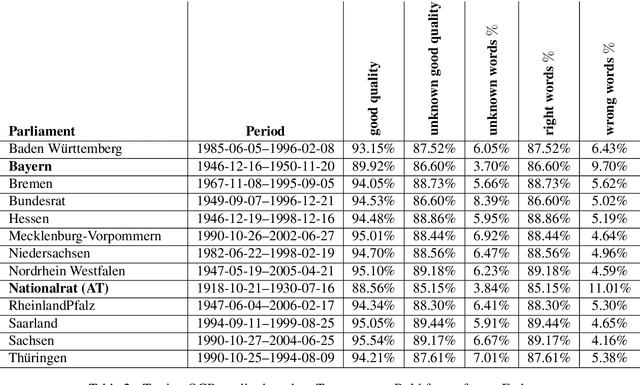
Parliamentary debates represent a large and partly unexploited treasure trove of publicly accessible texts. In the German-speaking area, there is a certain deficit of uniformly accessible and annotated corpora covering all German-speaking parliaments at the national and federal level. To address this gap, we introduce the German Parliament Corpus (GerParCor). GerParCor is a genre-specific corpus of (predominantly historical) German-language parliamentary protocols from three centuries and four countries, including state and federal level data. In addition, GerParCor contains conversions of scanned protocols and, in particular, of protocols in Fraktur converted via an OCR process based on Tesseract. All protocols were preprocessed by means of the NLP pipeline of spaCy3 and automatically annotated with metadata regarding their session date. GerParCor is made available in the XMI format of the UIMA project. In this way, GerParCor can be used as a large corpus of historical texts in the field of political communication for various tasks in NLP.
I still have Time: Extending HeidelTime for German Texts
Apr 19, 2022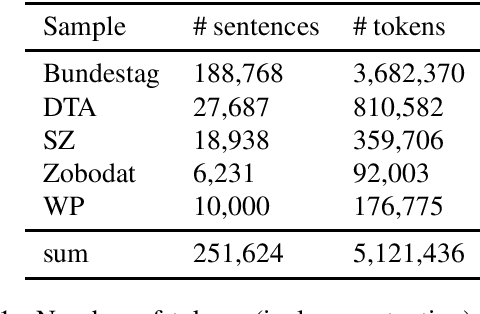
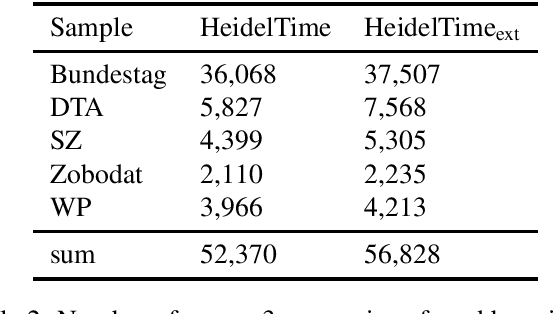
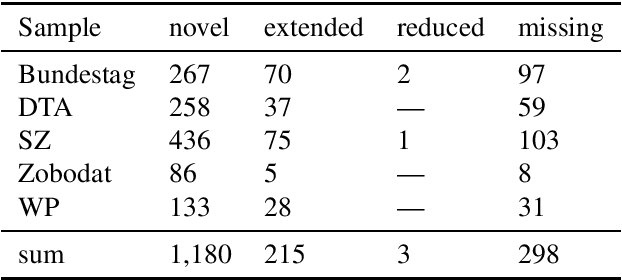
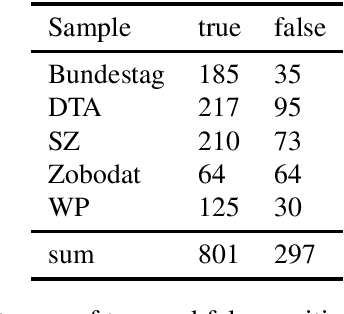
HeidelTime is one of the most widespread and successful tools for detecting temporal expressions in texts. Since HeidelTime's pattern matching system is based on regular expression, it can be extended in a convenient way. We present such an extension for the German resources of HeidelTime: HeidelTime-EXT . The extension has been brought about by means of observing false negatives within real world texts and various time banks. The gain in coverage is 2.7% or 8.5%, depending on the admitted degree of potential overgeneralization. We describe the development of HeidelTime-EXT, its evaluation on text samples from various genres, and share some linguistic observations. HeidelTime ext can be obtained from https://github.com/texttechnologylab/heideltime.