 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeMulti-Type-TD-TSR -- Extracting Tables from Document Images using a Multi-stage Pipeline for Table Detection and Table Structure Recognition: from OCR to Structured Table Representations
Paper and Code
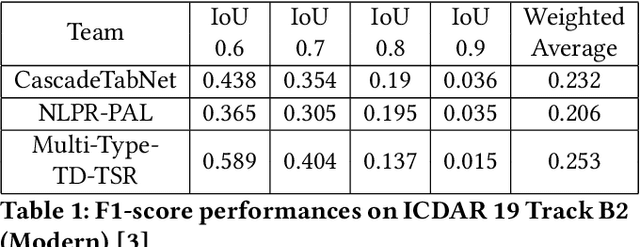
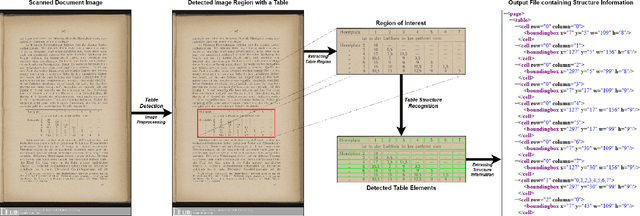
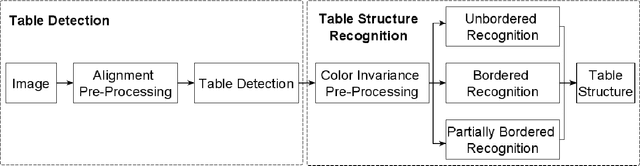
As global trends are shifting towards data-driven industries, the demand for automated algorithms that can convert digital images of scanned documents into machine readable information is rapidly growing. Besides the opportunity of data digitization for the application of data analytic tools, there is also a massive improvement towards automation of processes, which previously would require manual inspection of the documents. Although the introduction of optical character recognition technologies mostly solved the task of converting human-readable characters from images into machine-readable characters, the task of extracting table semantics has been less focused on over the years. The recognition of tables consists of two main tasks, namely table detection and table structure recognition. Most prior work on this problem focuses on either task without offering an end-to-end solution or paying attention to real application conditions like rotated images or noise artefacts inside the document image. Recent work shows a clear trend towards deep learning approaches coupled with the use of transfer learning for the task of table structure recognition due to the lack of sufficiently large datasets. In this paper we present a multistage pipeline named Multi-Type-TD-TSR, which offers an end-to-end solution for the problem of table recognition. It utilizes state-of-the-art deep learning models for table detection and differentiates between 3 different types of tables based on the tables' borders. For the table structure recognition we use a deterministic non-data driven algorithm, which works on all table types. We additionally present two algorithms. One for unbordered tables and one for bordered tables, which are the base of the used table structure recognition algorithm. We evaluate Multi-Type-TD-TSR on the ICDAR 2019 table structure recognition dataset and achieve a new state-of-the-art.