 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeGerman Parliamentary Corpus (GerParCor)
Apr 21, 2022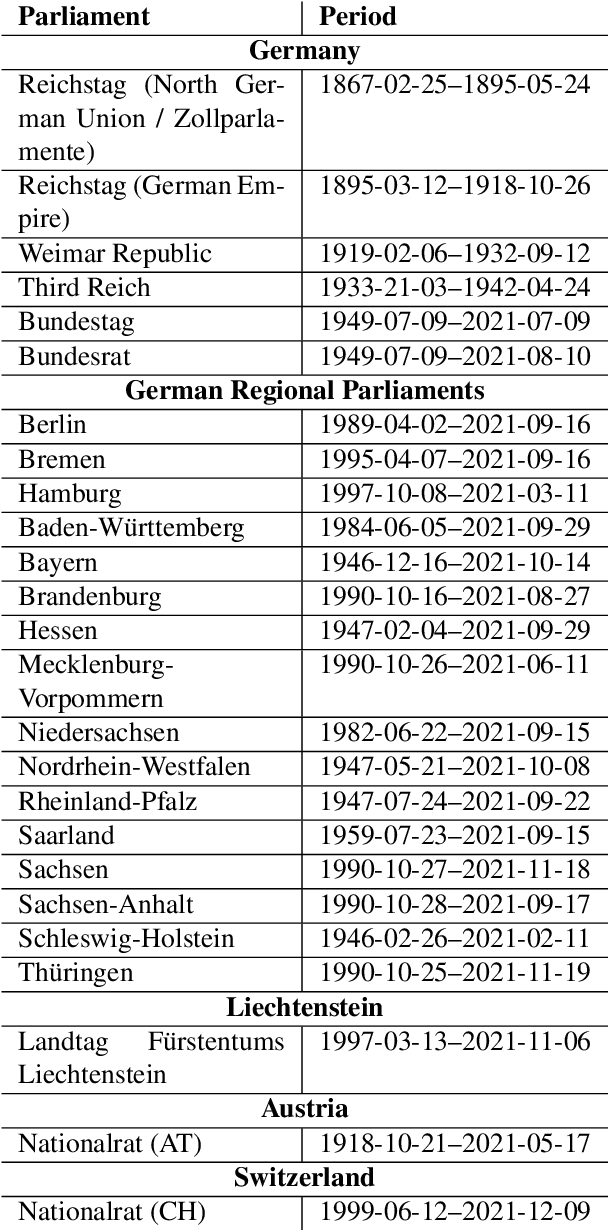
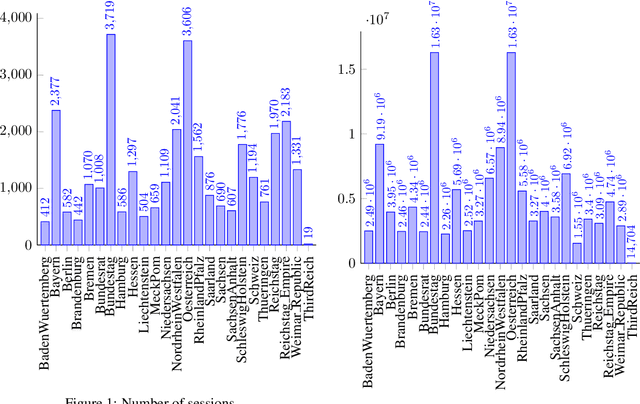
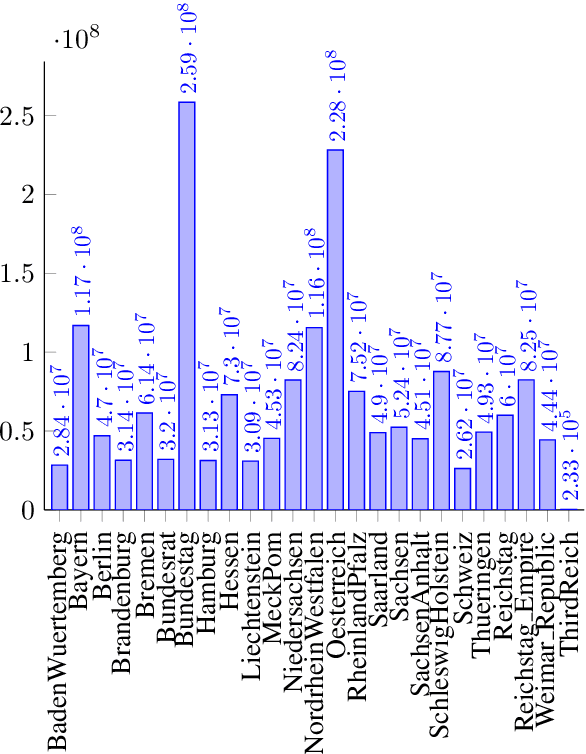
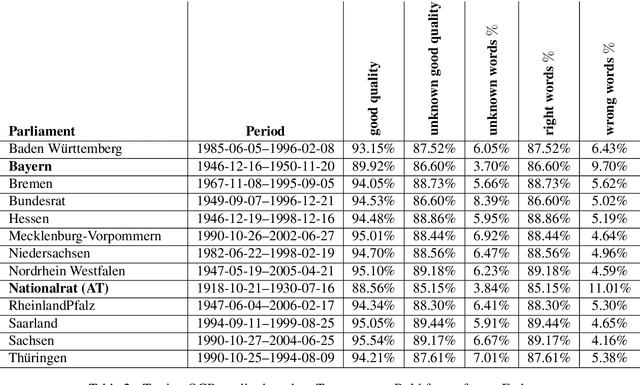
Parliamentary debates represent a large and partly unexploited treasure trove of publicly accessible texts. In the German-speaking area, there is a certain deficit of uniformly accessible and annotated corpora covering all German-speaking parliaments at the national and federal level. To address this gap, we introduce the German Parliament Corpus (GerParCor). GerParCor is a genre-specific corpus of (predominantly historical) German-language parliamentary protocols from three centuries and four countries, including state and federal level data. In addition, GerParCor contains conversions of scanned protocols and, in particular, of protocols in Fraktur converted via an OCR process based on Tesseract. All protocols were preprocessed by means of the NLP pipeline of spaCy3 and automatically annotated with metadata regarding their session date. GerParCor is made available in the XMI format of the UIMA project. In this way, GerParCor can be used as a large corpus of historical texts in the field of political communication for various tasks in NLP.
I still have Time: Extending HeidelTime for German Texts
Apr 19, 2022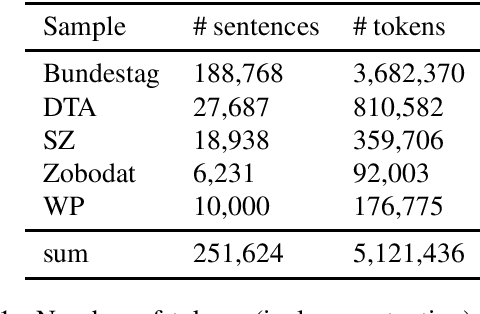
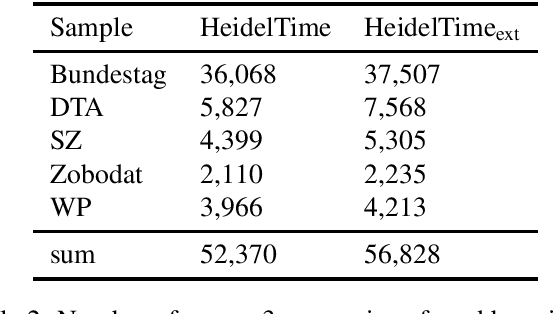
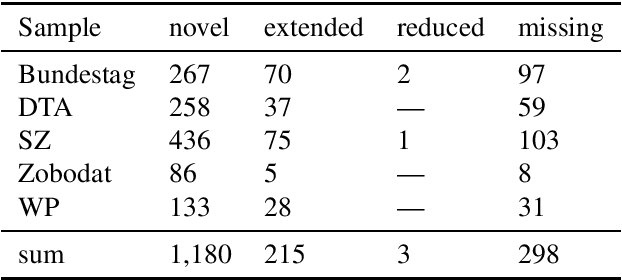
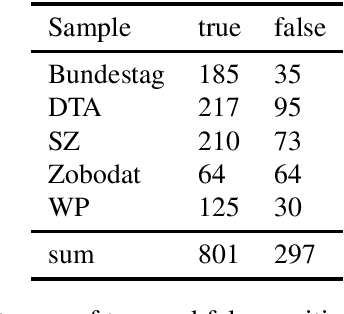
HeidelTime is one of the most widespread and successful tools for detecting temporal expressions in texts. Since HeidelTime's pattern matching system is based on regular expression, it can be extended in a convenient way. We present such an extension for the German resources of HeidelTime: HeidelTime-EXT . The extension has been brought about by means of observing false negatives within real world texts and various time banks. The gain in coverage is 2.7% or 8.5%, depending on the admitted degree of potential overgeneralization. We describe the development of HeidelTime-EXT, its evaluation on text samples from various genres, and share some linguistic observations. HeidelTime ext can be obtained from https://github.com/texttechnologylab/heideltime.
Multi-Type-TD-TSR -- Extracting Tables from Document Images using a Multi-stage Pipeline for Table Detection and Table Structure Recognition: from OCR to Structured Table Representations
May 23, 2021
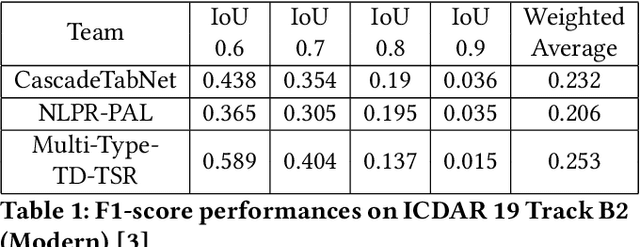
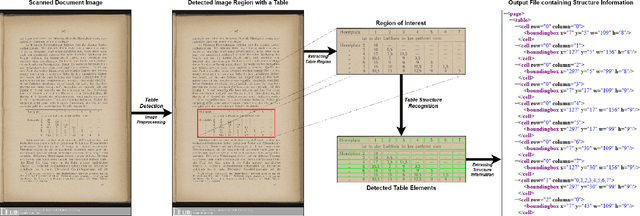
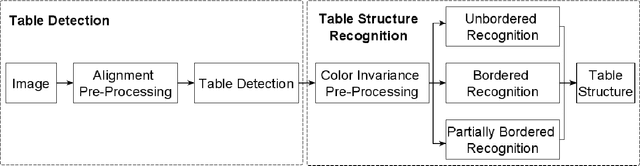
As global trends are shifting towards data-driven industries, the demand for automated algorithms that can convert digital images of scanned documents into machine readable information is rapidly growing. Besides the opportunity of data digitization for the application of data analytic tools, there is also a massive improvement towards automation of processes, which previously would require manual inspection of the documents. Although the introduction of optical character recognition technologies mostly solved the task of converting human-readable characters from images into machine-readable characters, the task of extracting table semantics has been less focused on over the years. The recognition of tables consists of two main tasks, namely table detection and table structure recognition. Most prior work on this problem focuses on either task without offering an end-to-end solution or paying attention to real application conditions like rotated images or noise artefacts inside the document image. Recent work shows a clear trend towards deep learning approaches coupled with the use of transfer learning for the task of table structure recognition due to the lack of sufficiently large datasets. In this paper we present a multistage pipeline named Multi-Type-TD-TSR, which offers an end-to-end solution for the problem of table recognition. It utilizes state-of-the-art deep learning models for table detection and differentiates between 3 different types of tables based on the tables' borders. For the table structure recognition we use a deterministic non-data driven algorithm, which works on all table types. We additionally present two algorithms. One for unbordered tables and one for bordered tables, which are the base of the used table structure recognition algorithm. We evaluate Multi-Type-TD-TSR on the ICDAR 2019 table structure recognition dataset and achieve a new state-of-the-art.
Computational linguistic assessment of textbook and online learning media by means of threshold concepts in business education
Aug 05, 2020
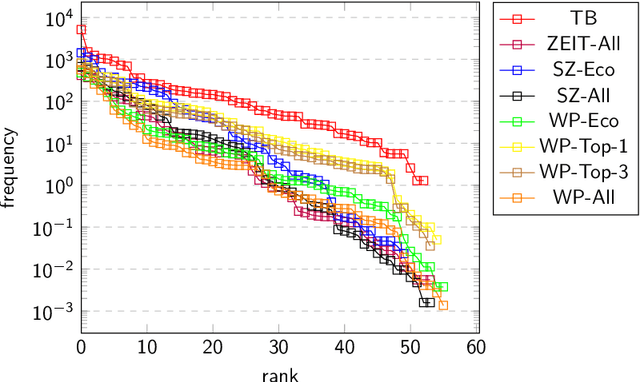
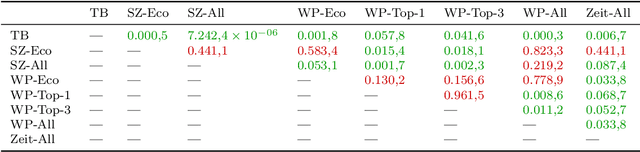
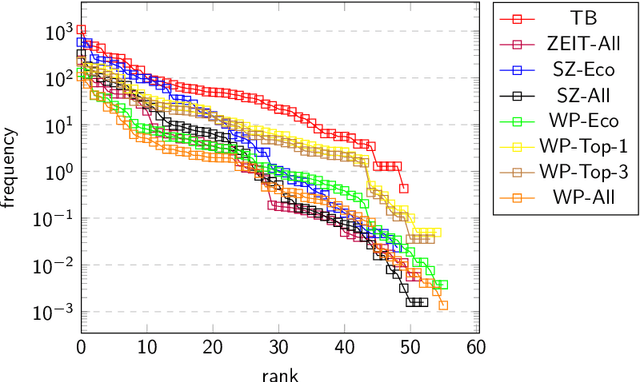
Threshold concepts are key terms in domain-based knowledge acquisition. They are regarded as building blocks of the conceptual development of domain knowledge within particular learners. From a linguistic perspective, however, threshold concepts are instances of specialized vocabularies, exhibiting particular linguistic features. Threshold concepts are typically used in specialized texts such as textbooks -- that is, within a formal learning environment. However, they also occur in informal learning environments like newspapers. In this article, a first approach is taken to combine both lines into an overarching research program - that is, to provide a computational linguistic assessment of different resources, including in particular online resources, by means of threshold concepts. To this end, the distributive profiles of 63 threshold concepts from business education (which have been collected from threshold concept research) has been investigated in three kinds of (German) resources, namely textbooks, newspapers, and Wikipedia. Wikipedia is (one of) the largest and most widely used online resources. We looked at the threshold concepts' frequency distribution, their compound distribution, and their network structure within the three kind of resources. The two main findings can be summarized as follows: Firstly, the three kinds of resources can indeed be distinguished in terms of their threshold concepts' profiles. Secondly, Wikipedia definitely appears to be a formal learning resource.
The Frankfurt Latin Lexicon: From Morphological Expansion and Word Embeddings to SemioGraphs
May 21, 2020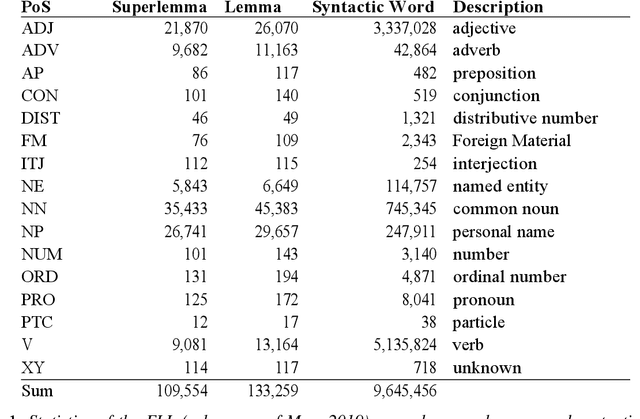
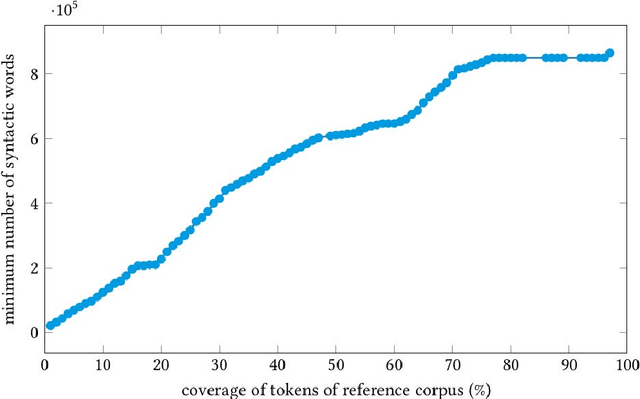
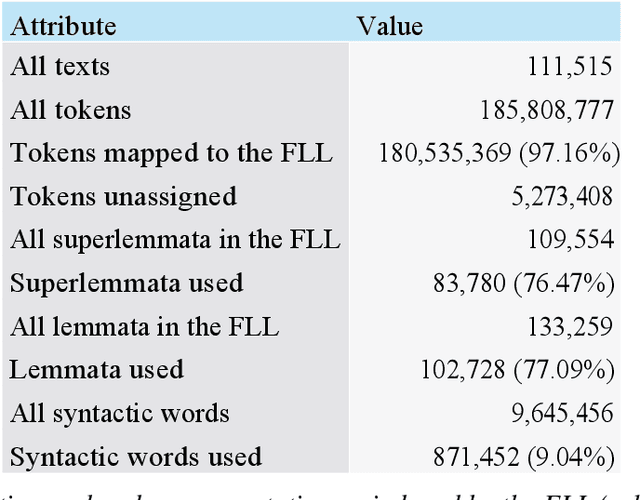
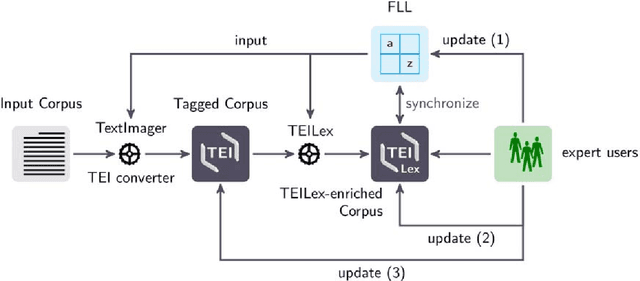
In this article we present the Frankfurt Latin Lexicon (FLL), a lexical resource for Medieval Latin that is used both for the lemmatization of Latin texts and for the post-editing of lemmatizations. We describe recent advances in the development of lemmatizers and test them against the Capitularies corpus (comprising Frankish royal edicts, mid-6th to mid-9th century), a corpus created as a reference for processing Medieval Latin. We also consider the post-correction of lemmatizations using a limited crowdsourcing process aimed at continuous review and updating of the FLL. Starting from the texts resulting from this lemmatization process, we describe the extension of the FLL by means of word embeddings, whose interactive traversing by means of SemioGraphs completes the digital enhanced hermeneutic circle. In this way, the article argues for a more comprehensive understanding of lemmatization, encompassing classical machine learning as well as intellectual post-corrections and, in particular, human computation in the form of interpretation processes based on graph representations of the underlying lexical resources.