 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeSyntactic Language Change in English and German: Metrics, Parsers, and Convergences
Feb 18, 2024



Many studies have shown that human languages tend to optimize for lower complexity and increased communication efficiency. Syntactic dependency distance, which measures the linear distance between dependent words, is often considered a key indicator of language processing difficulty and working memory load. The current paper looks at diachronic trends in syntactic language change in both English and German, using corpora of parliamentary debates from the last c. 160 years. We base our observations on five dependency parsers, including the widely used Stanford CoreNLP as well as 4 newer alternatives. Our analysis of syntactic language change goes beyond linear dependency distance and explores 15 metrics relevant to dependency distance minimization (DDM) and/or based on tree graph properties, such as the tree height and degree variance. Even though we have evidence that recent parsers trained on modern treebanks are not heavily affected by data 'noise' such as spelling changes and OCR errors in our historic data, we find that results of syntactic language change are sensitive to the parsers involved, which is a caution against using a single parser for evaluating syntactic language change as done in previous work. We also show that syntactic language change over the time period investigated is largely similar between English and German across the different metrics explored: only 4% of cases we examine yield opposite conclusions regarding upwards and downtrends of syntactic metrics across German and English. We also show that changes in syntactic measures seem to be more frequent at the tails of sentence length distributions. To our best knowledge, ours is the most comprehensive analysis of syntactic language using modern NLP technology in recent corpora of English and German.
I still have Time: Extending HeidelTime for German Texts
Apr 19, 2022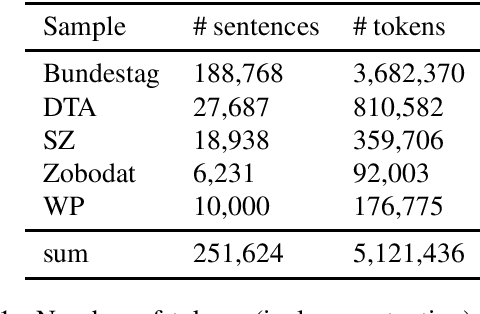
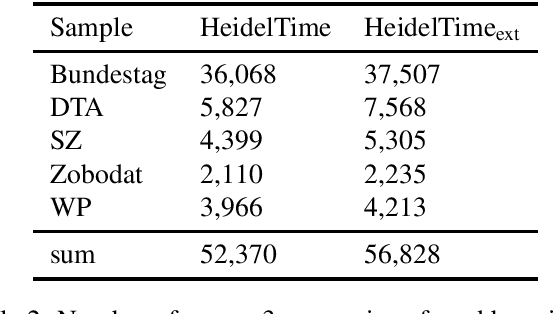
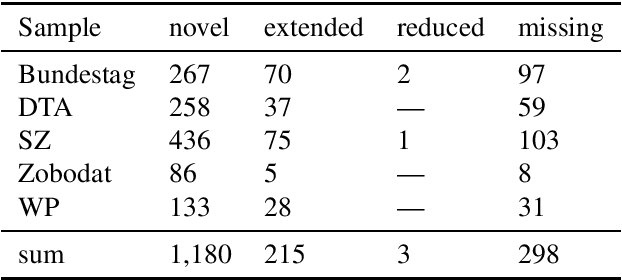
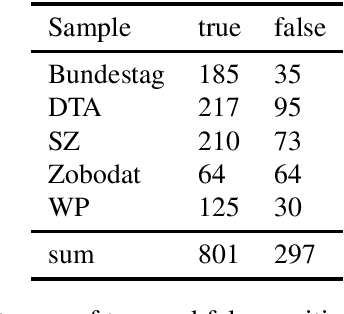
HeidelTime is one of the most widespread and successful tools for detecting temporal expressions in texts. Since HeidelTime's pattern matching system is based on regular expression, it can be extended in a convenient way. We present such an extension for the German resources of HeidelTime: HeidelTime-EXT . The extension has been brought about by means of observing false negatives within real world texts and various time banks. The gain in coverage is 2.7% or 8.5%, depending on the admitted degree of potential overgeneralization. We describe the development of HeidelTime-EXT, its evaluation on text samples from various genres, and share some linguistic observations. HeidelTime ext can be obtained from https://github.com/texttechnologylab/heideltime.
When Specialization Helps: Using Pooled Contextualized Embeddings to Detect Chemical and Biomedical Entities in Spanish
Oct 08, 2019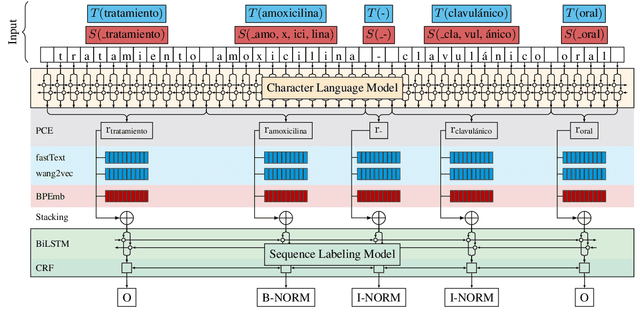
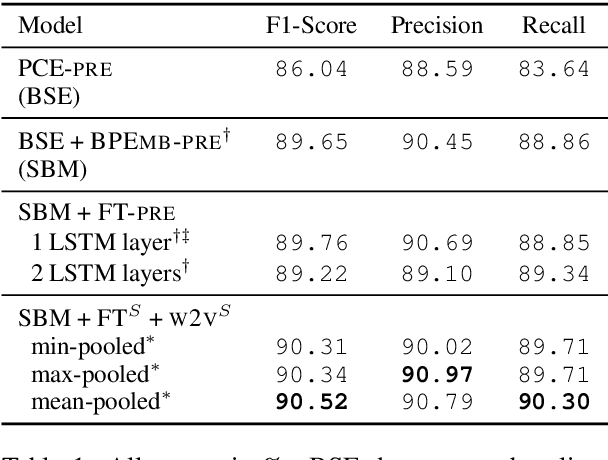
The recognition of pharmacological substances, compounds and proteins is an essential preliminary work for the recognition of relations between chemicals and other biomedically relevant units. In this paper, we describe an approach to Task 1 of the PharmaCoNER Challenge, which involves the recognition of mentions of chemicals and drugs in Spanish medical texts. We train a state-of-the-art BiLSTM-CRF sequence tagger with stacked Pooled Contextualized Embeddings, word and sub-word embeddings using the open-source framework FLAIR. We present a new corpus composed of articles and papers from Spanish health science journals, termed the Spanish Health Corpus, and use it to train domain-specific embeddings which we incorporate in our model training. We achieve a result of 89.76% F1-score using pre-trained embeddings and are able to improve these results to 90.52% F1-score using specialized embeddings.
SenseFitting: Sense Level Semantic Specialization of Word Embeddings for Word Sense Disambiguation
Jul 30, 2019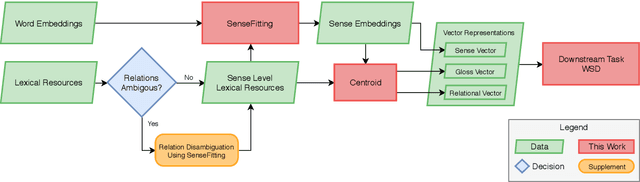

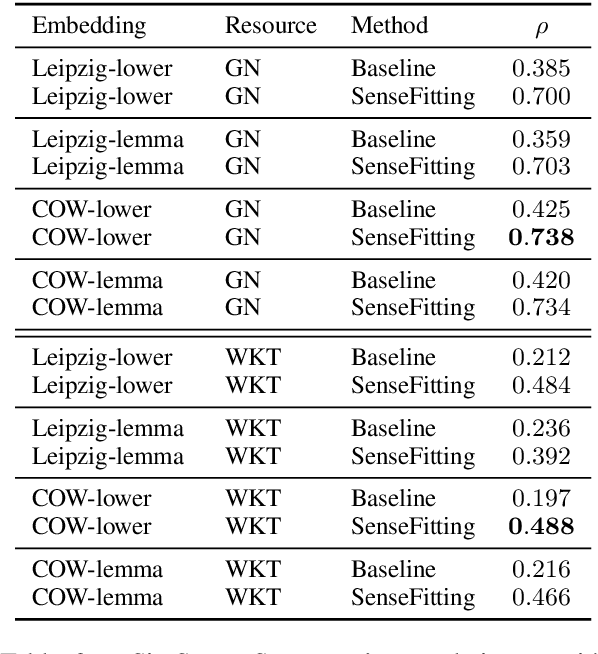
We introduce a neural network-based system of Word Sense Disambiguation (WSD) for German that is based on SenseFitting, a novel method for optimizing WSD. We outperform knowledge-based WSD methods by up to 25% F1-score and produce a new state-of-the-art on the German sense-annotated dataset WebCAGe. Our method uses three feature vectors consisting of a) sense, b) gloss, and c) relational vectors to represent target senses and to compare them with the vector centroids of sample contexts. Utilizing widely available word embeddings and lexical resources, we are able to compensate for the lower resource availability of German. SenseFitting builds upon the recently introduced semantic specialization procedure Attract-Repel, and leverages sense level semantic constraints from lexical-semantic networks (e.g. GermaNet) or online social dictionaries (e.g. Wiktionary) to produce high-quality sense embeddings from pre-trained word embeddings. We evaluate our sense embeddings with a new SimLex-999 based similarity dataset, called SimSense, that we developed for this work. We achieve results that outperform current lemma-based specialization methods for German, making them comparable to results achieved for English.