 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeWhen Specialization Helps: Using Pooled Contextualized Embeddings to Detect Chemical and Biomedical Entities in Spanish
Paper and Code
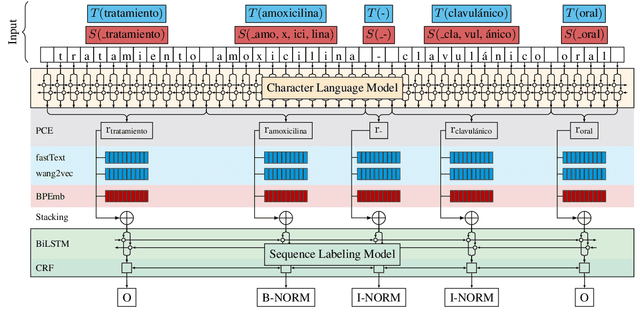
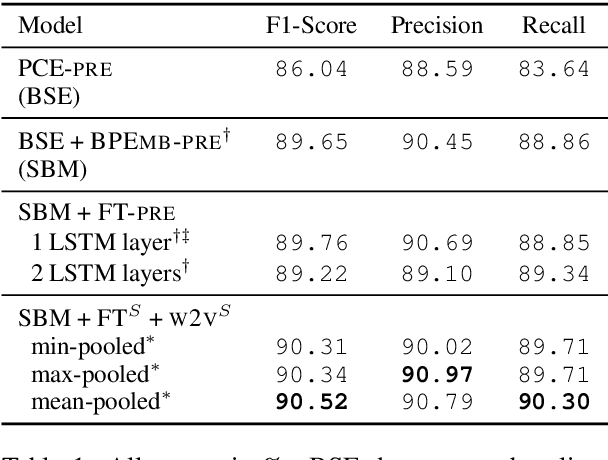
The recognition of pharmacological substances, compounds and proteins is an essential preliminary work for the recognition of relations between chemicals and other biomedically relevant units. In this paper, we describe an approach to Task 1 of the PharmaCoNER Challenge, which involves the recognition of mentions of chemicals and drugs in Spanish medical texts. We train a state-of-the-art BiLSTM-CRF sequence tagger with stacked Pooled Contextualized Embeddings, word and sub-word embeddings using the open-source framework FLAIR. We present a new corpus composed of articles and papers from Spanish health science journals, termed the Spanish Health Corpus, and use it to train domain-specific embeddings which we incorporate in our model training. We achieve a result of 89.76% F1-score using pre-trained embeddings and are able to improve these results to 90.52% F1-score using specialized embeddings.