 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeSenseFitting: Sense Level Semantic Specialization of Word Embeddings for Word Sense Disambiguation
Jul 30, 2019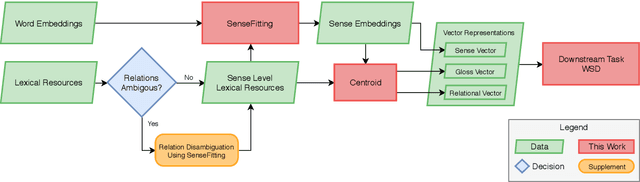

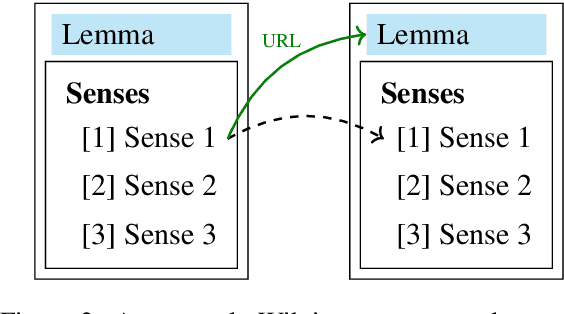
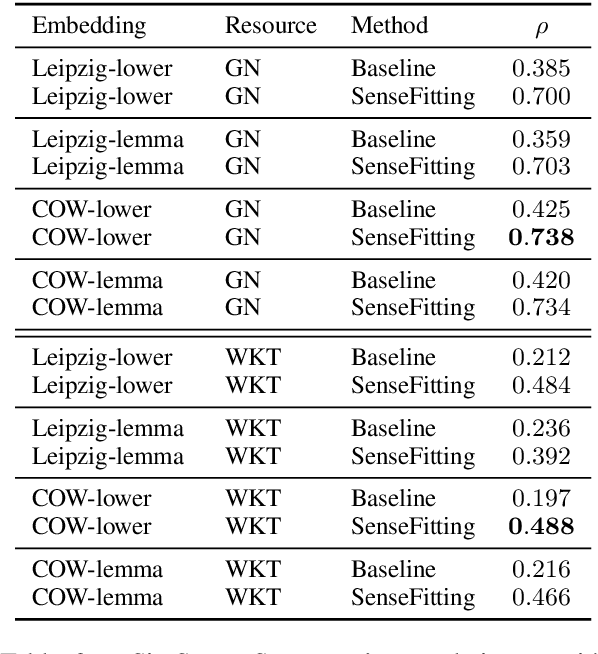
We introduce a neural network-based system of Word Sense Disambiguation (WSD) for German that is based on SenseFitting, a novel method for optimizing WSD. We outperform knowledge-based WSD methods by up to 25% F1-score and produce a new state-of-the-art on the German sense-annotated dataset WebCAGe. Our method uses three feature vectors consisting of a) sense, b) gloss, and c) relational vectors to represent target senses and to compare them with the vector centroids of sample contexts. Utilizing widely available word embeddings and lexical resources, we are able to compensate for the lower resource availability of German. SenseFitting builds upon the recently introduced semantic specialization procedure Attract-Repel, and leverages sense level semantic constraints from lexical-semantic networks (e.g. GermaNet) or online social dictionaries (e.g. Wiktionary) to produce high-quality sense embeddings from pre-trained word embeddings. We evaluate our sense embeddings with a new SimLex-999 based similarity dataset, called SimSense, that we developed for this work. We achieve results that outperform current lemma-based specialization methods for German, making them comparable to results achieved for English.
Resource-Size matters: Improving Neural Named Entity Recognition with Optimized Large Corpora
Jul 26, 2018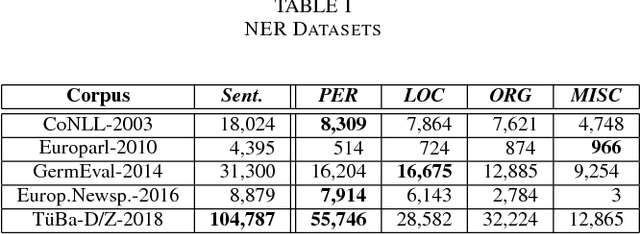
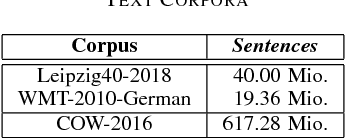
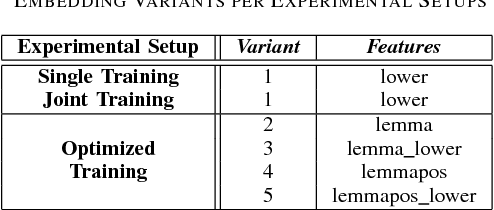
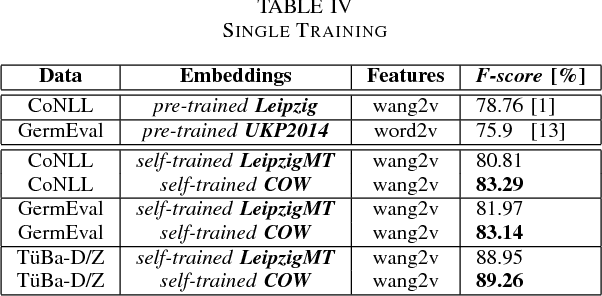
This study improves the performance of neural named entity recognition by a margin of up to 11% in F-score on the example of a low-resource language like German, thereby outperforming existing baselines and establishing a new state-of-the-art on each single open-source dataset. Rather than designing deeper and wider hybrid neural architectures, we gather all available resources and perform a detailed optimization and grammar-dependent morphological processing consisting of lemmatization and part-of-speech tagging prior to exposing the raw data to any training process. We test our approach in a threefold monolingual experimental setup of a) single, b) joint, and c) optimized training and shed light on the dependency of downstream-tasks on the size of corpora used to compute word embeddings.