 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeYou Shall Know a Tool by the Traces it Leaves: The Predictability of Sentiment Analysis Tools
Oct 18, 2024



If sentiment analysis tools were valid classifiers, one would expect them to provide comparable results for sentiment classification on different kinds of corpora and for different languages. In line with results of previous studies we show that sentiment analysis tools disagree on the same dataset. Going beyond previous studies we show that the sentiment tool used for sentiment annotation can even be predicted from its outcome, revealing an algorithmic bias of sentiment analysis. Based on Twitter, Wikipedia and different news corpora from the English, German and French languages, our classifiers separate sentiment tools with an averaged F1-score of 0.89 (for the English corpora). We therefore warn against taking sentiment annotations as face value and argue for the need of more and systematic NLP evaluation studies.
Iconic Gesture Semantics
Apr 29, 2024The "meaning" of an iconic gesture is conditioned on its informational evaluation. Only informational evaluation lifts a gesture to a quasi-linguistic level that can interact with verbal content. Interaction is either vacuous or regimented by usual lexicon-driven inferences. Informational evaluation is spelled out as extended exemplification (extemplification) in terms of perceptual classification of a gesture's visual iconic model. The iconic model is derived from Frege/Montague-like truth-functional evaluation of a gesture's form within spatially extended domains. We further argue that the perceptual classification of instances of visual communication requires a notion of meaning different from Frege/Montague frameworks. Therefore, a heuristic for gesture interpretation is provided that can guide the working semanticist. In sum, an iconic gesture semantics is introduced which covers the full range from kinematic gesture representations over model-theoretic evaluation to inferential interpretation in dynamic semantic frameworks.
I still have Time: Extending HeidelTime for German Texts
Apr 19, 2022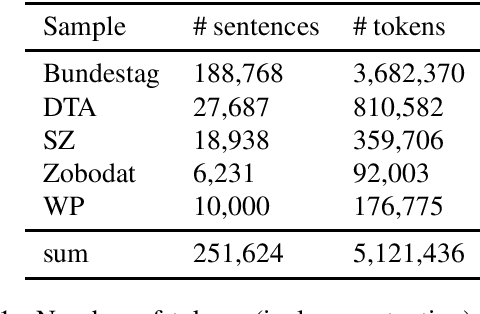
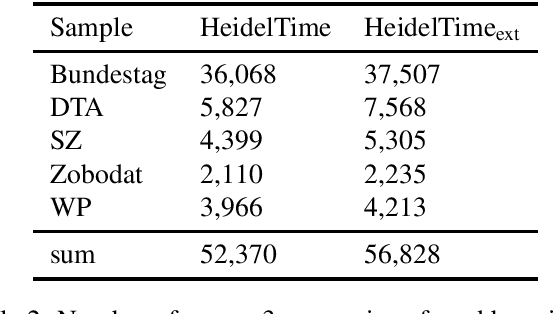
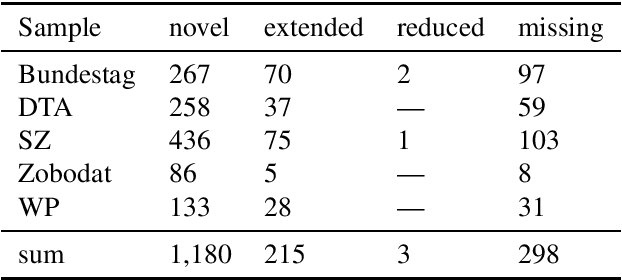
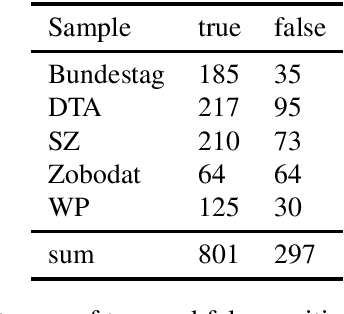
HeidelTime is one of the most widespread and successful tools for detecting temporal expressions in texts. Since HeidelTime's pattern matching system is based on regular expression, it can be extended in a convenient way. We present such an extension for the German resources of HeidelTime: HeidelTime-EXT . The extension has been brought about by means of observing false negatives within real world texts and various time banks. The gain in coverage is 2.7% or 8.5%, depending on the admitted degree of potential overgeneralization. We describe the development of HeidelTime-EXT, its evaluation on text samples from various genres, and share some linguistic observations. HeidelTime ext can be obtained from https://github.com/texttechnologylab/heideltime.
Computational linguistic assessment of textbook and online learning media by means of threshold concepts in business education
Aug 05, 2020
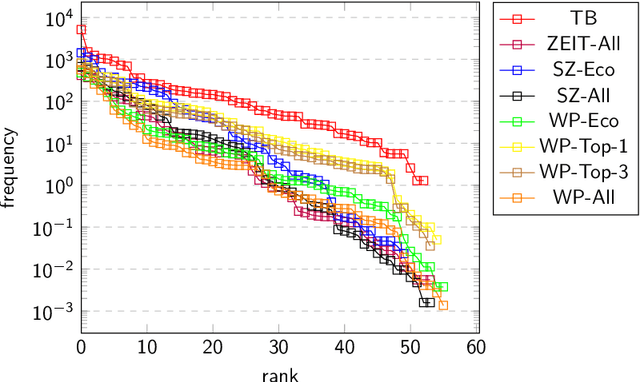
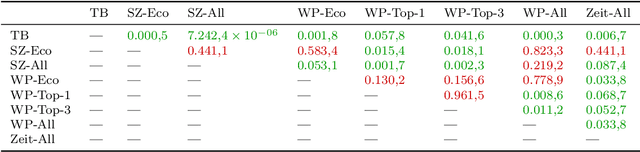
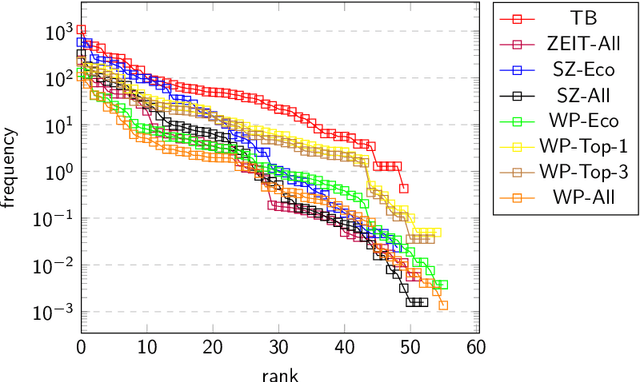
Threshold concepts are key terms in domain-based knowledge acquisition. They are regarded as building blocks of the conceptual development of domain knowledge within particular learners. From a linguistic perspective, however, threshold concepts are instances of specialized vocabularies, exhibiting particular linguistic features. Threshold concepts are typically used in specialized texts such as textbooks -- that is, within a formal learning environment. However, they also occur in informal learning environments like newspapers. In this article, a first approach is taken to combine both lines into an overarching research program - that is, to provide a computational linguistic assessment of different resources, including in particular online resources, by means of threshold concepts. To this end, the distributive profiles of 63 threshold concepts from business education (which have been collected from threshold concept research) has been investigated in three kinds of (German) resources, namely textbooks, newspapers, and Wikipedia. Wikipedia is (one of) the largest and most widely used online resources. We looked at the threshold concepts' frequency distribution, their compound distribution, and their network structure within the three kind of resources. The two main findings can be summarized as follows: Firstly, the three kinds of resources can indeed be distinguished in terms of their threshold concepts' profiles. Secondly, Wikipedia definitely appears to be a formal learning resource.