 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeYou Shall Know a Tool by the Traces it Leaves: The Predictability of Sentiment Analysis Tools
Oct 18, 2024



If sentiment analysis tools were valid classifiers, one would expect them to provide comparable results for sentiment classification on different kinds of corpora and for different languages. In line with results of previous studies we show that sentiment analysis tools disagree on the same dataset. Going beyond previous studies we show that the sentiment tool used for sentiment annotation can even be predicted from its outcome, revealing an algorithmic bias of sentiment analysis. Based on Twitter, Wikipedia and different news corpora from the English, German and French languages, our classifiers separate sentiment tools with an averaged F1-score of 0.89 (for the English corpora). We therefore warn against taking sentiment annotations as face value and argue for the need of more and systematic NLP evaluation studies.
Iconic Gesture Semantics
Apr 29, 2024The "meaning" of an iconic gesture is conditioned on its informational evaluation. Only informational evaluation lifts a gesture to a quasi-linguistic level that can interact with verbal content. Interaction is either vacuous or regimented by usual lexicon-driven inferences. Informational evaluation is spelled out as extended exemplification (extemplification) in terms of perceptual classification of a gesture's visual iconic model. The iconic model is derived from Frege/Montague-like truth-functional evaluation of a gesture's form within spatially extended domains. We further argue that the perceptual classification of instances of visual communication requires a notion of meaning different from Frege/Montague frameworks. Therefore, a heuristic for gesture interpretation is provided that can guide the working semanticist. In sum, an iconic gesture semantics is introduced which covers the full range from kinematic gesture representations over model-theoretic evaluation to inferential interpretation in dynamic semantic frameworks.
What do Toothbrushes do in the Kitchen? How Transformers Think our World is Structured
Apr 12, 2022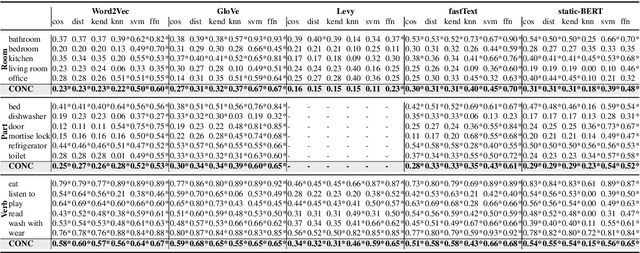
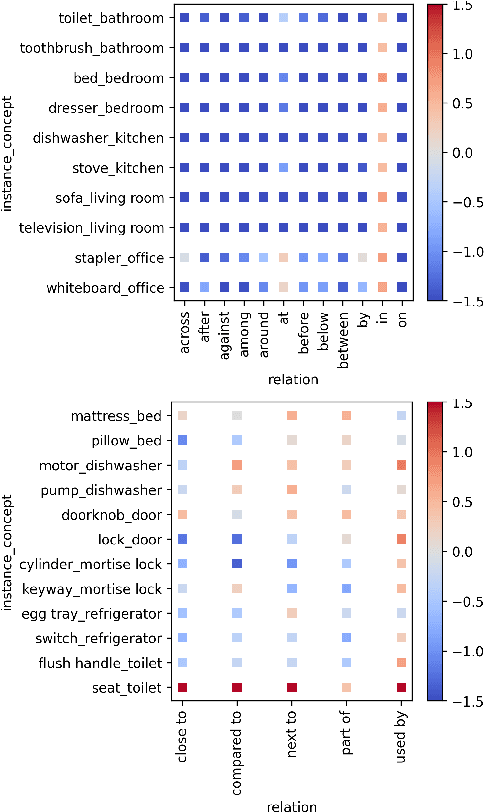
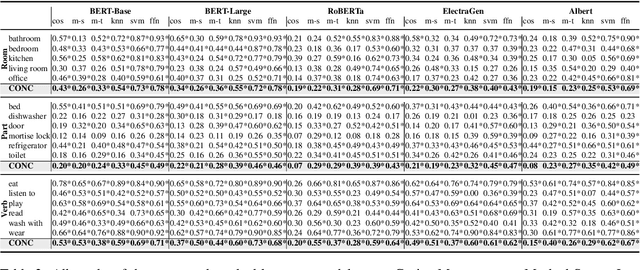
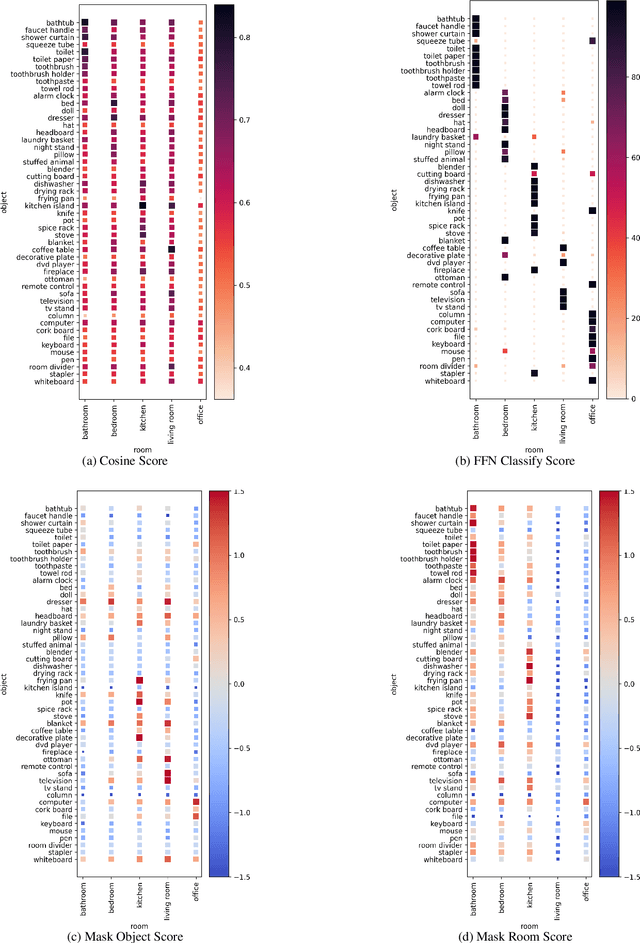
Transformer-based models are now predominant in NLP. They outperform approaches based on static models in many respects. This success has in turn prompted research that reveals a number of biases in the language models generated by transformers. In this paper we utilize this research on biases to investigate to what extent transformer-based language models allow for extracting knowledge about object relations (X occurs in Y; X consists of Z; action A involves using X). To this end, we compare contextualized models with their static counterparts. We make this comparison dependent on the application of a number of similarity measures and classifiers. Our results are threefold: Firstly, we show that the models combined with the different similarity measures differ greatly in terms of the amount of knowledge they allow for extracting. Secondly, our results suggest that similarity measures perform much worse than classifier-based approaches. Thirdly, we show that, surprisingly, static models perform almost as well as contextualized models -- in some cases even better.
The Frankfurt Latin Lexicon: From Morphological Expansion and Word Embeddings to SemioGraphs
May 21, 2020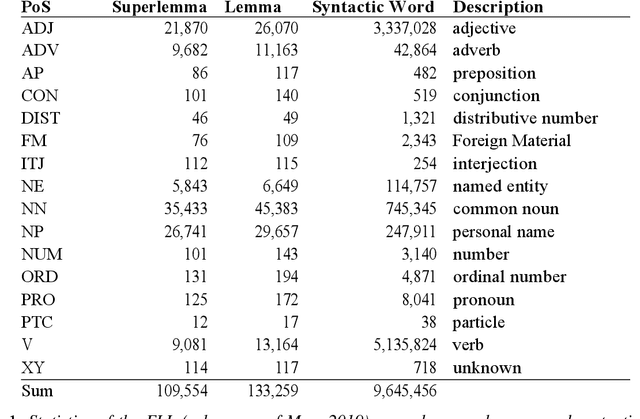
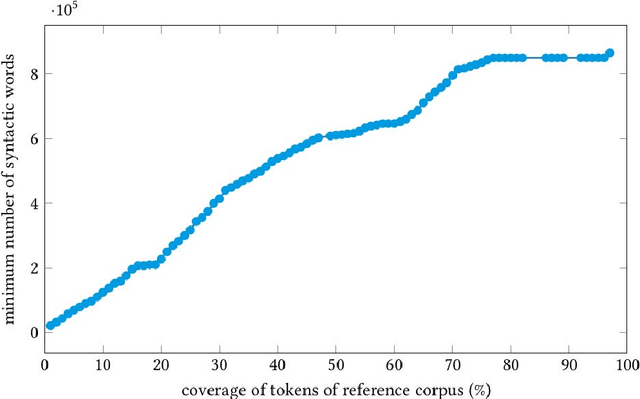
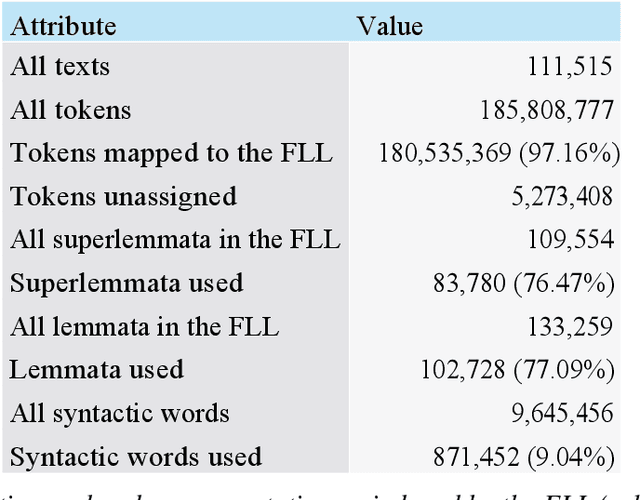
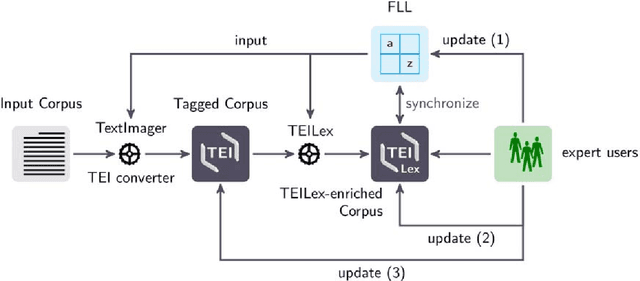
In this article we present the Frankfurt Latin Lexicon (FLL), a lexical resource for Medieval Latin that is used both for the lemmatization of Latin texts and for the post-editing of lemmatizations. We describe recent advances in the development of lemmatizers and test them against the Capitularies corpus (comprising Frankish royal edicts, mid-6th to mid-9th century), a corpus created as a reference for processing Medieval Latin. We also consider the post-correction of lemmatizations using a limited crowdsourcing process aimed at continuous review and updating of the FLL. Starting from the texts resulting from this lemmatization process, we describe the extension of the FLL by means of word embeddings, whose interactive traversing by means of SemioGraphs completes the digital enhanced hermeneutic circle. In this way, the article argues for a more comprehensive understanding of lemmatization, encompassing classical machine learning as well as intellectual post-corrections and, in particular, human computation in the form of interpretation processes based on graph representations of the underlying lexical resources.