 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeComputational linguistic assessment of textbook and online learning media by means of threshold concepts in business education
Aug 05, 2020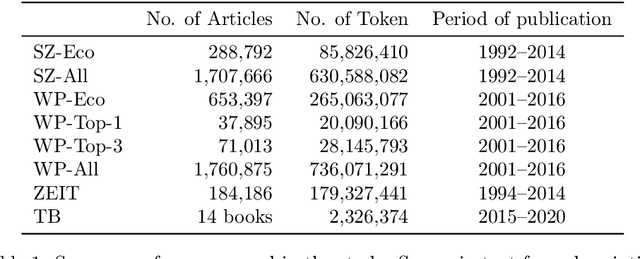
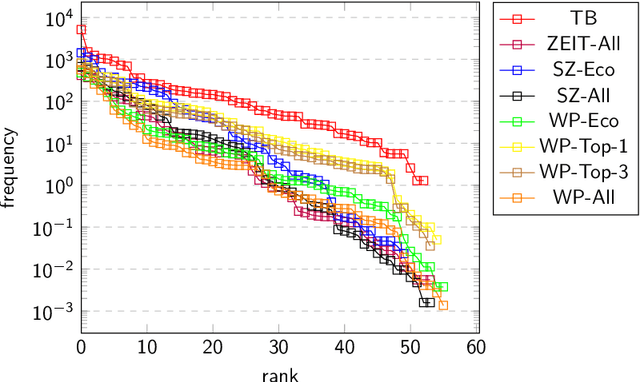
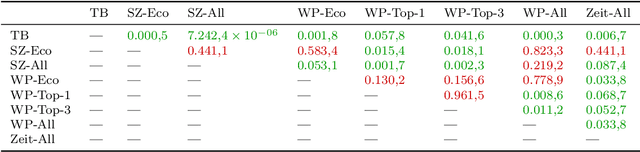
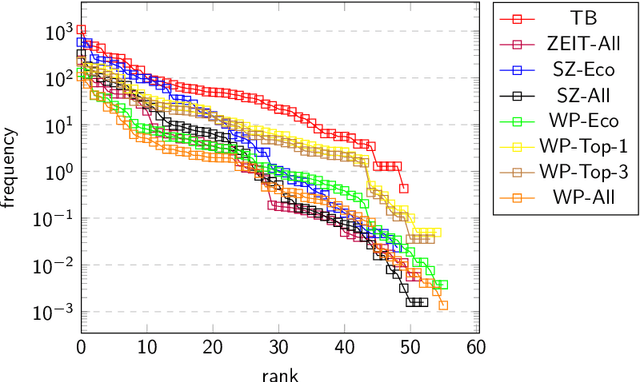
Threshold concepts are key terms in domain-based knowledge acquisition. They are regarded as building blocks of the conceptual development of domain knowledge within particular learners. From a linguistic perspective, however, threshold concepts are instances of specialized vocabularies, exhibiting particular linguistic features. Threshold concepts are typically used in specialized texts such as textbooks -- that is, within a formal learning environment. However, they also occur in informal learning environments like newspapers. In this article, a first approach is taken to combine both lines into an overarching research program - that is, to provide a computational linguistic assessment of different resources, including in particular online resources, by means of threshold concepts. To this end, the distributive profiles of 63 threshold concepts from business education (which have been collected from threshold concept research) has been investigated in three kinds of (German) resources, namely textbooks, newspapers, and Wikipedia. Wikipedia is (one of) the largest and most widely used online resources. We looked at the threshold concepts' frequency distribution, their compound distribution, and their network structure within the three kind of resources. The two main findings can be summarized as follows: Firstly, the three kinds of resources can indeed be distinguished in terms of their threshold concepts' profiles. Secondly, Wikipedia definitely appears to be a formal learning resource.
Multiple Texts as a Limiting Factor in Online Learning: Quantifying similarities of Knowledge Networks across Languages
Aug 05, 2020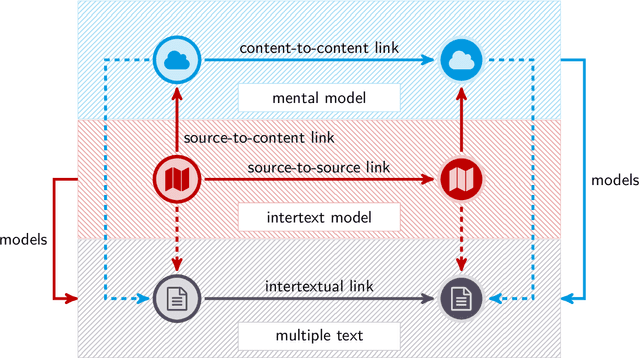

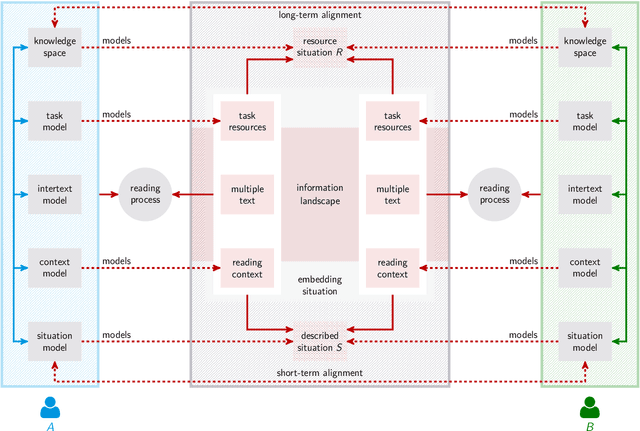
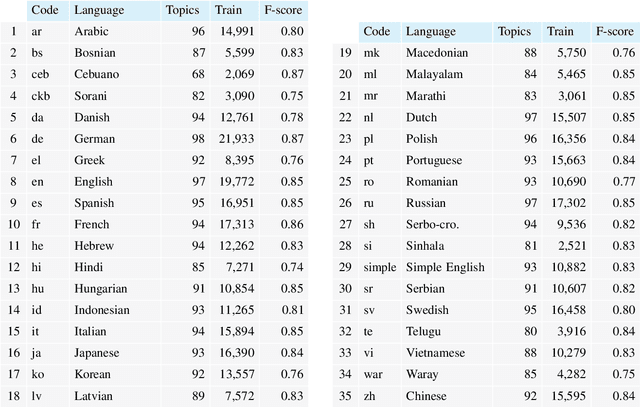
We test the hypothesis that the extent to which one obtains information on a given topic through Wikipedia depends on the language in which it is consulted. Controlling the size factor, we investigate this hypothesis for a number of 25 subject areas. Since Wikipedia is a central part of the web-based information landscape, this indicates a language-related, linguistic bias. The article therefore deals with the question of whether Wikipedia exhibits this kind of linguistic relativity or not. From the perspective of educational science, the article develops a computational model of the information landscape from which multiple texts are drawn as typical input of web-based reading. For this purpose, it develops a hybrid model of intra- and intertextual similarity of different parts of the information landscape and tests this model on the example of 35 languages and corresponding Wikipedias. In this way the article builds a bridge between reading research, educational science, Wikipedia research and computational linguistics.
The Frankfurt Latin Lexicon: From Morphological Expansion and Word Embeddings to SemioGraphs
May 21, 2020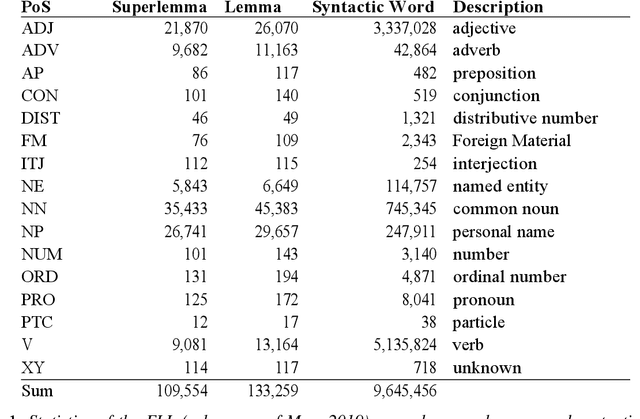
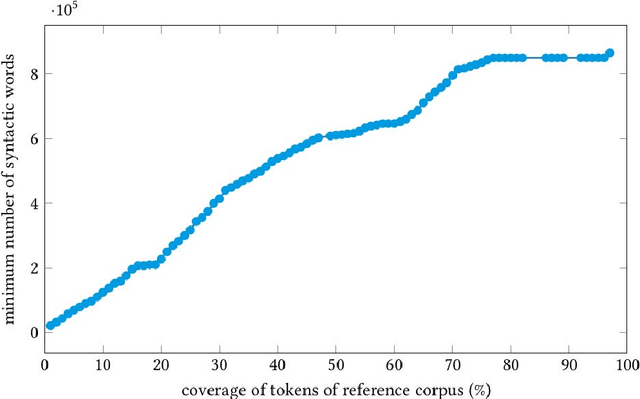
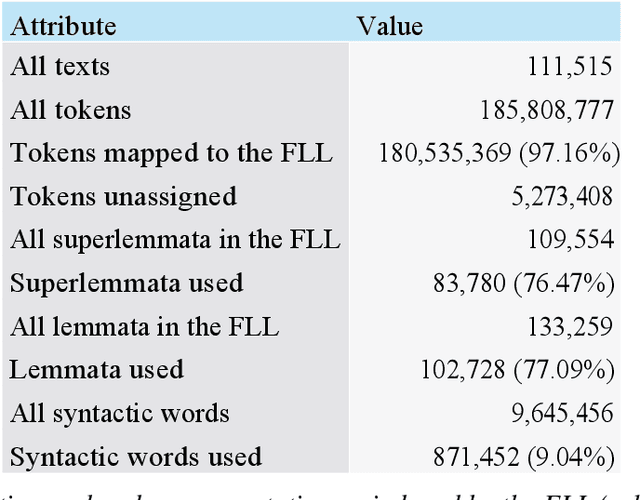
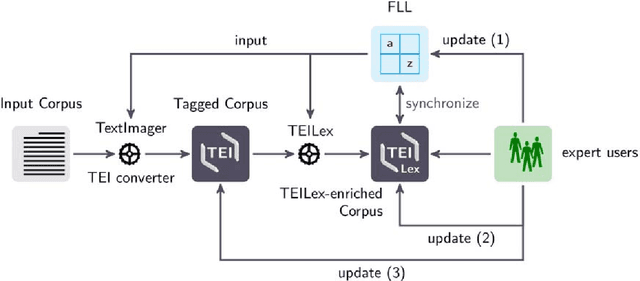
In this article we present the Frankfurt Latin Lexicon (FLL), a lexical resource for Medieval Latin that is used both for the lemmatization of Latin texts and for the post-editing of lemmatizations. We describe recent advances in the development of lemmatizers and test them against the Capitularies corpus (comprising Frankish royal edicts, mid-6th to mid-9th century), a corpus created as a reference for processing Medieval Latin. We also consider the post-correction of lemmatizations using a limited crowdsourcing process aimed at continuous review and updating of the FLL. Starting from the texts resulting from this lemmatization process, we describe the extension of the FLL by means of word embeddings, whose interactive traversing by means of SemioGraphs completes the digital enhanced hermeneutic circle. In this way, the article argues for a more comprehensive understanding of lemmatization, encompassing classical machine learning as well as intellectual post-corrections and, in particular, human computation in the form of interpretation processes based on graph representations of the underlying lexical resources.
From Topic Networks to Distributed Cognitive Maps: Zipfian Topic Universes in the Area of Volunteered Geographic Information
Feb 04, 2020



Are nearby places (e.g. cities) described by related words? In this article we transfer this research question in the field of lexical encoding of geographic information onto the level of intertextuality. To this end, we explore Volunteered Geographic Information (VGI) to model texts addressing places at the level of cities or regions with the help of so-called topic networks. This is done to examine how language encodes and networks geographic information on the aboutness level of texts. Our hypothesis is that the networked thematizations of places are similar - regardless of their distances and the underlying communities of authors. To investigate this we introduce Multiplex Topic Networks (MTN), which we automatically derive from Linguistic Multilayer Networks (LMN) as a novel model, especially of thematic networking in text corpora. Our study shows a Zipfian organization of the thematic universe in which geographical places (especially cities) are located in online communication. We interpret this finding in the context of cognitive maps, a notion which we extend by so-called thematic maps. According to our interpretation of this finding, the organization of thematic maps as part of cognitive maps results from a tendency of authors to generate shareable content that ensures the continued existence of the underlying media. We test our hypothesis by example of special wikis and extracts of Wikipedia. In this way we come to the conclusion: Places, whether close to each other or not, are located in neighboring places that span similar subnetworks in the topic universe.