 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeSupervised and Unsupervised protocols for hetero-associative neural networks
May 24, 2025This paper introduces a learning framework for Three-Directional Associative Memory (TAM) models, extending the classical Hebbian paradigm to both supervised and unsupervised protocols within an hetero-associative setting. These neural networks consist of three interconnected layers of binary neurons interacting via generalized Hebbian synaptic couplings that allow learning, storage and retrieval of structured triplets of patterns. By relying upon glassy statistical mechanical techniques (mainly replica theory and Guerra interpolation), we analyze the emergent computational properties of these networks, at work with random (Rademacher) datasets and at the replica-symmetric level of description: we obtain a set of self-consistency equations for the order parameters that quantify the critical dataset sizes (i.e. their thresholds for learning) and describe the retrieval performance of these networks, highlighting the differences between supervised and unsupervised protocols. Numerical simulations validate our theoretical findings and demonstrate the robustness of the captured picture about TAMs also at work with structured datasets. In particular, this study provides insights into the cooperative interplay of layers, beyond that of the neurons within the layers, with potential implications for optimal design of artificial neural network architectures.
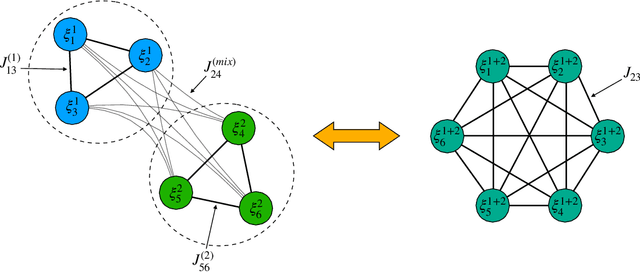
Beyond Disorder: Unveiling Cooperativeness in Multidirectional Associative Memories
Mar 06, 2025By leveraging tools from the statistical mechanics of complex systems, in these short notes we extend the architecture of a neural network for hetero-associative memory (called three-directional associative memories, TAM) to explore supervised and unsupervised learning protocols. In particular, by providing entropic-heterogeneous datasets to its various layers, we predict and quantify a new emergent phenomenon -- that we term {\em layer's cooperativeness} -- where the interplay of dataset entropies across network's layers enhances their retrieval capabilities Beyond those they would have without reciprocal influence. Naively we would expect layers trained with less informative datasets to develop smaller retrieval regions compared to those pertaining to layers that experienced more information: this does not happen and all the retrieval regions settle to the same amplitude, allowing for optimal retrieval performance globally. This cooperative dynamics marks a significant advancement in understanding emergent computational capabilities within disordered systems.
Hebbian Learning from First Principles
Jan 13, 2024Recently, the original storage prescription for the Hopfield model of neural networks -- as well as for its dense generalizations -- has been turned into a genuine Hebbian learning rule by postulating the expression of its Hamiltonian for both the supervised and unsupervised protocols. In these notes, first, we obtain these explicit expressions by relying upon maximum entropy extremization \`a la Jaynes. Beyond providing a formal derivation of these recipes for Hebbian learning, this construction also highlights how Lagrangian constraints within entropy extremization force network's outcomes on neural correlations: these try to mimic the empirical counterparts hidden in the datasets provided to the network for its training and, the denser the network, the longer the correlations that it is able to capture. Next, we prove that, in the big data limit, whatever the presence of a teacher (or its lacking), not only these Hebbian learning rules converge to the original storage prescription of the Hopfield model but also their related free energies (and, thus, the statistical mechanical picture provided by Amit, Gutfreund and Sompolinsky is fully recovered). As a sideline, we show mathematical equivalence among standard Cost functions (Hamiltonian), preferred in Statistical Mechanical jargon, and quadratic Loss Functions, preferred in Machine Learning terminology. Remarks on the exponential Hopfield model (as the limit of dense networks with diverging density) and semi-supervised protocols are also provided.
Unsupervised and Supervised learning by Dense Associative Memory under replica symmetry breaking
Dec 15, 2023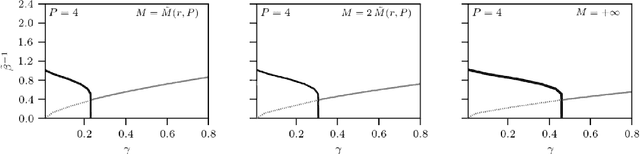

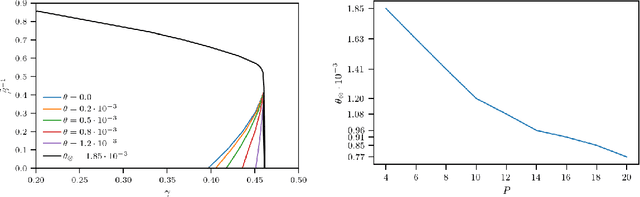

Statistical mechanics of spin glasses is one of the main strands toward a comprehension of information processing by neural networks and learning machines. Tackling this approach, at the fairly standard replica symmetric level of description, recently Hebbian attractor networks with multi-node interactions (often called Dense Associative Memories) have been shown to outperform their classical pairwise counterparts in a number of tasks, from their robustness against adversarial attacks and their capability to work with prohibitively weak signals to their supra-linear storage capacities. Focusing on mathematical techniques more than computational aspects, in this paper we relax the replica symmetric assumption and we derive the one-step broken-replica-symmetry picture of supervised and unsupervised learning protocols for these Dense Associative Memories: a phase diagram in the space of the control parameters is achieved, independently, both via the Parisi's hierarchy within then replica trick as well as via the Guerra's telescope within the broken-replica interpolation. Further, an explicit analytical investigation is provided to deepen both the big-data and ground state limits of these networks as well as a proof that replica symmetry breaking does not alter the thresholds for learning and slightly increases the maximal storage capacity. Finally the De Almeida and Thouless line, depicting the onset of instability of a replica symmetric description, is also analytically derived highlighting how, crossed this boundary, the broken replica description should be preferred.
Parallel Learning by Multitasking Neural Networks
Aug 08, 2023A modern challenge of Artificial Intelligence is learning multiple patterns at once (i.e.parallel learning). While this can not be accomplished by standard Hebbian associative neural networks, in this paper we show how the Multitasking Hebbian Network (a variation on theme of the Hopfield model working on sparse data-sets) is naturally able to perform this complex task. We focus on systems processing in parallel a finite (up to logarithmic growth in the size of the network) amount of patterns, mirroring the low-storage level of standard associative neural networks at work with pattern recognition. For mild dilution in the patterns, the network handles them hierarchically, distributing the amplitudes of their signals as power-laws w.r.t. their information content (hierarchical regime), while, for strong dilution, all the signals pertaining to all the patterns are raised with the same strength (parallel regime). Further, confined to the low-storage setting (i.e., far from the spin glass limit), the presence of a teacher neither alters the multitasking performances nor changes the thresholds for learning: the latter are the same whatever the training protocol is supervised or unsupervised. Results obtained through statistical mechanics, signal-to-noise technique and Monte Carlo simulations are overall in perfect agreement and carry interesting insights on multiple learning at once: for instance, whenever the cost-function of the model is minimized in parallel on several patterns (in its description via Statistical Mechanics), the same happens to the standard sum-squared error Loss function (typically used in Machine Learning).
Statistical Mechanics of Learning via Reverberation in Bidirectional Associative Memories
Jul 17, 2023



We study bi-directional associative neural networks that, exposed to noisy examples of an extensive number of random archetypes, learn the latter (with or without the presence of a teacher) when the supplied information is enough: in this setting, learning is heteroassociative -- involving couples of patterns -- and it is achieved by reverberating the information depicted from the examples through the layers of the network. By adapting Guerra's interpolation technique, we provide a full statistical mechanical picture of supervised and unsupervised learning processes (at the replica symmetric level of description) obtaining analytically phase diagrams, thresholds for learning, a picture of the ground-state in plain agreement with Monte Carlo simulations and signal-to-noise outcomes. In the large dataset limit, the Kosko storage prescription as well as its statistical mechanical picture provided by Kurchan, Peliti, and Saber in the eighties is fully recovered. Computational advantages in dealing with information reverberation, rather than storage, are discussed for natural test cases. In particular, we show how this network admits an integral representation in terms of two coupled restricted Boltzmann machines, whose hidden layers are entirely built of by grand-mother neurons, to prove that by coupling solely these grand-mother neurons we can correlate the patterns they are related to: it is thus possible to recover Pavlov's Classical Conditioning by adding just one synapse among the correct grand-mother neurons (hence saving an extensive number of these links for further information storage w.r.t. the classical autoassociative setting).
Dense Hebbian neural networks: a replica symmetric picture of supervised learning
Nov 25, 2022



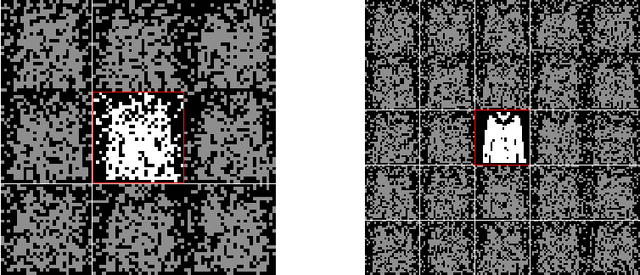
We consider dense, associative neural-networks trained by a teacher (i.e., with supervision) and we investigate their computational capabilities analytically, via statistical-mechanics of spin glasses, and numerically, via Monte Carlo simulations. In particular, we obtain a phase diagram summarizing their performance as a function of the control parameters such as quality and quantity of the training dataset, network storage and noise, that is valid in the limit of large network size and structureless datasets: these networks may work in a ultra-storage regime (where they can handle a huge amount of patterns, if compared with shallow neural networks) or in a ultra-detection regime (where they can perform pattern recognition at prohibitive signal-to-noise ratios, if compared with shallow neural networks). Guided by the random theory as a reference framework, we also test numerically learning, storing and retrieval capabilities shown by these networks on structured datasets as MNist and Fashion MNist. As technical remarks, from the analytic side, we implement large deviations and stability analysis within Guerra's interpolation to tackle the not-Gaussian distributions involved in the post-synaptic potentials while, from the computational counterpart, we insert Plefka approximation in the Monte Carlo scheme, to speed up the evaluation of the synaptic tensors, overall obtaining a novel and broad approach to investigate supervised learning in neural networks, beyond the shallow limit, in general.
Dense Hebbian neural networks: a replica symmetric picture of unsupervised learning
Nov 25, 2022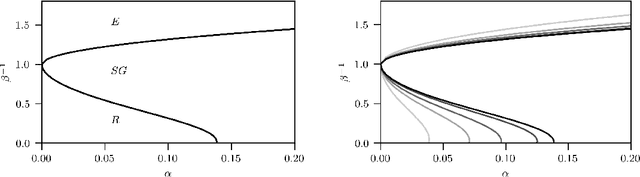
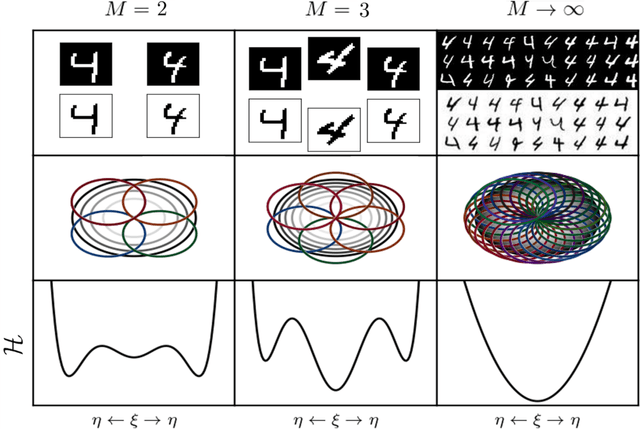
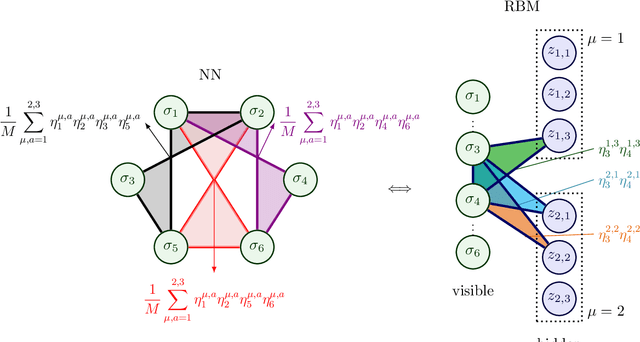
We consider dense, associative neural-networks trained with no supervision and we investigate their computational capabilities analytically, via a statistical-mechanics approach, and numerically, via Monte Carlo simulations. In particular, we obtain a phase diagram summarizing their performance as a function of the control parameters such as the quality and quantity of the training dataset and the network storage, valid in the limit of large network size and structureless datasets. Moreover, we establish a bridge between macroscopic observables standardly used in statistical mechanics and loss functions typically used in the machine learning. As technical remarks, from the analytic side, we implement large deviations and stability analysis within Guerra's interpolation to tackle the not-Gaussian distributions involved in the post-synaptic potentials while, from the computational counterpart, we insert Plefka approximation in the Monte Carlo scheme, to speed up the evaluation of the synaptic tensors, overall obtaining a novel and broad approach to investigate neural networks in general.
Thermodynamics of bidirectional associative memories
Nov 17, 2022In this paper we investigate the equilibrium properties of bidirectional associative memories (BAMs). Introduced by Kosko in 1988 as a generalization of the Hopfield model to a bipartite structure, the simplest architecture is defined by two layers of neurons, with synaptic connections only between units of different layers: even without internal connections within each layer, information storage and retrieval are still possible through the reverberation of neural activities passing from one layer to another. We characterize the computational capabilities of a stochastic extension of this model in the thermodynamic limit, by applying rigorous techniques from statistical physics. A detailed picture of the phase diagram at the replica symmetric level is provided, both at finite temperature and in the noiseless regime. An analytical and numerical inspection of the transition curves (namely critical lines splitting the various modes of operation of the machine) is carried out as the control parameters - noise, load and asymmetry between the two layer sizes - are tuned. In particular, with a finite asymmetry between the two layers, it is shown how the BAM can store information more efficiently than the Hopfield model by requiring less parameters to encode a fixed number of patterns. Comparisons are made with numerical simulations of neural dynamics. Finally, a low-load analysis is carried out to explain the retrieval mechanism in the BAM by analogy with two interacting Hopfield models. A potential equivalence with two coupled Restricted Boltmzann Machines is also discussed.
Pavlov Learning Machines
Jul 02, 2022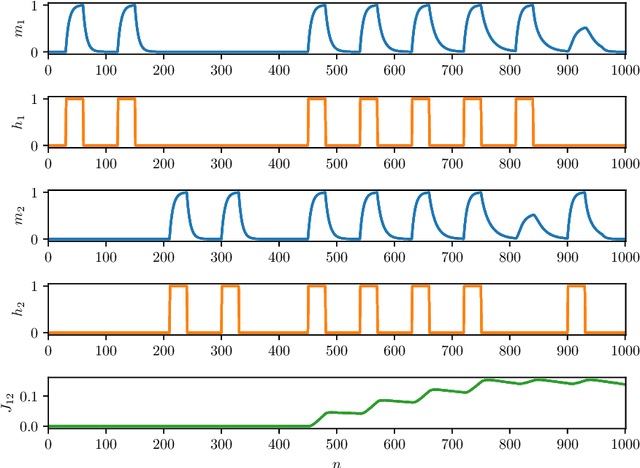
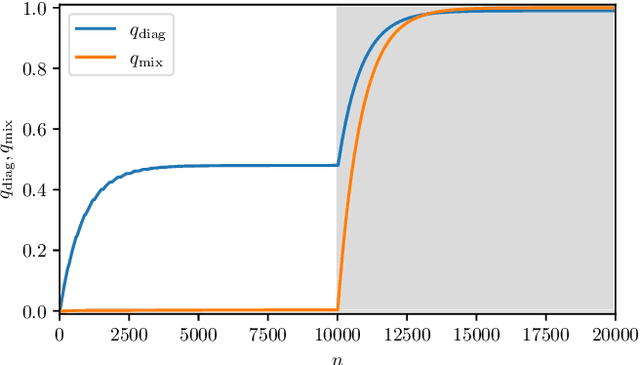

As well known, Hebb's learning traces its origin in Pavlov's Classical Conditioning, however, while the former has been extensively modelled in the past decades (e.g., by Hopfield model and countless variations on theme), as for the latter modelling has remained largely unaddressed so far; further, a bridge between these two pillars is totally lacking. The main difficulty towards this goal lays in the intrinsically different scales of the information involved: Pavlov's theory is about correlations among \emph{concepts} that are (dynamically) stored in the synaptic matrix as exemplified by the celebrated experiment starring a dog and a ring bell; conversely, Hebb's theory is about correlations among pairs of adjacent neurons as summarized by the famous statement {\em neurons that fire together wire together}. In this paper we rely on stochastic-process theory and model neural and synaptic dynamics via Langevin equations, to prove that -- as long as we keep neurons' and synapses' timescales largely split -- Pavlov mechanism spontaneously takes place and ultimately gives rise to synaptic weights that recover the Hebbian kernel.