 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeOn the role of non-linear latent features in bipartite generative neural networks
Jun 12, 2025
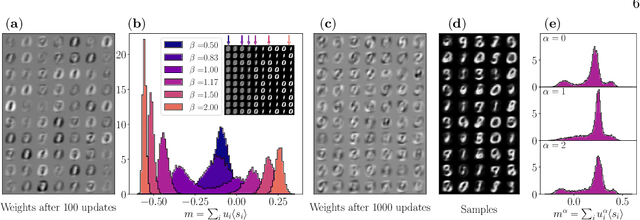


We investigate the phase diagram and memory retrieval capabilities of bipartite energy-based neural networks, namely Restricted Boltzmann Machines (RBMs), as a function of the prior distribution imposed on their hidden units - including binary, multi-state, and ReLU-like activations. Drawing connections to the Hopfield model and employing analytical tools from statistical physics of disordered systems, we explore how the architectural choices and activation functions shape the thermodynamic properties of these models. Our analysis reveals that standard RBMs with binary hidden nodes and extensive connectivity suffer from reduced critical capacity, limiting their effectiveness as associative memories. To address this, we examine several modifications, such as introducing local biases and adopting richer hidden unit priors. These adjustments restore ordered retrieval phases and markedly improve recall performance, even at finite temperatures. Our theoretical findings, supported by finite-size Monte Carlo simulations, highlight the importance of hidden unit design in enhancing the expressive power of RBMs.
A theoretical framework for overfitting in energy-based modeling
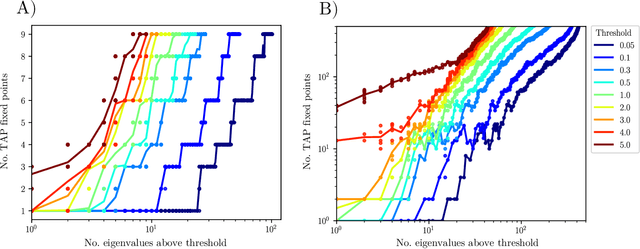
Jan 31, 2025We investigate the impact of limited data on training pairwise energy-based models for inverse problems aimed at identifying interaction networks. Utilizing the Gaussian model as testbed, we dissect training trajectories across the eigenbasis of the coupling matrix, exploiting the independent evolution of eigenmodes and revealing that the learning timescales are tied to the spectral decomposition of the empirical covariance matrix. We see that optimal points for early stopping arise from the interplay between these timescales and the initial conditions of training. Moreover, we show that finite data corrections can be accurately modeled through asymptotic random matrix theory calculations and provide the counterpart of generalized cross-validation in the energy based model context. Our analytical framework extends to binary-variable maximum-entropy pairwise models with minimal variations. These findings offer strategies to control overfitting in discrete-variable models through empirical shrinkage corrections, improving the management of overfitting in energy-based generative models.
Inferring High-Order Couplings with Neural Networks
Jan 10, 2025Maximum-entropy methods, rooted in the inverse Ising/Potts problem from statistical mechanics, have become indispensable tools for modeling pairwise interactions in disciplines such as bioinformatics, ecology, and neuroscience. Despite their remarkable success, these methods often overlook high-order interactions that may be crucial in complex systems. Conversely, while modern machine learning approaches can capture such interactions, existing interpretable frameworks are computationally expensive, making it impractical to assess the relevance of high-order interactions in real-world scenarios. Restricted Boltzmann Machines (RBMs) offer a computationally efficient alternative by encoding statistical correlations via hidden nodes in a bipartite neural network. Here, we present a method that maps RBMs exactly onto generalized Potts models with interactions of arbitrary high order. This approach leverages large-$N$ approximations, facilitated by the simple architecture of the RBM, to enable the efficient extraction of effective many-body couplings with minimal computational cost. This mapping also enables the development of a general formal framework for the extraction of effective higher-order interactions in arbitrarily complex probabilistic models. Additionally, we introduce a robust formalism for gauge fixing within the generalized Potts model. We validate our method by accurately recovering two- and three-body interactions from synthetic datasets. Additionally, applying our framework to protein sequence data demonstrates its effectiveness in reconstructing protein contact maps, achieving performance comparable to state-of-the-art inverse Potts models. These results position RBMs as a powerful and efficient tool for investigating high-order interactions in complex systems.
Fast, accurate training and sampling of Restricted Boltzmann Machines
May 24, 2024Thanks to their simple architecture, Restricted Boltzmann Machines (RBMs) are powerful tools for modeling complex systems and extracting interpretable insights from data. However, training RBMs, as other energy-based models, on highly structured data poses a major challenge, as effective training relies on mixing the Markov chain Monte Carlo simulations used to estimate the gradient. This process is often hindered by multiple second-order phase transitions and the associated critical slowdown. In this paper, we present an innovative method in which the principal directions of the dataset are integrated into a low-rank RBM through a convex optimization procedure. This approach enables efficient sampling of the equilibrium measure via a static Monte Carlo process. By starting the standard training process with a model that already accurately represents the main modes of the data, we bypass the initial phase transitions. Our results show that this strategy successfully trains RBMs to capture the full diversity of data in datasets where previous methods fail. Furthermore, we use the training trajectories to propose a new sampling method, {\em parallel trajectory tempering}, which allows us to sample the equilibrium measure of the trained model much faster than previous optimized MCMC approaches and a better estimation of the log-likelihood. We illustrate the success of the training method on several highly structured datasets.
Cascade of phase transitions in the training of Energy-based models
May 23, 2024In this paper, we investigate the feature encoding process in a prototypical energy-based generative model, the Restricted Boltzmann Machine (RBM). We start with an analytical investigation using simplified architectures and data structures, and end with numerical analysis of real trainings on real datasets. Our study tracks the evolution of the model's weight matrix through its singular value decomposition, revealing a series of phase transitions associated to a progressive learning of the principal modes of the empirical probability distribution. The model first learns the center of mass of the modes and then progressively resolve all modes through a cascade of phase transitions. We first describe this process analytically in a controlled setup that allows us to study analytically the training dynamics. We then validate our theoretical results by training the Bernoulli-Bernoulli RBM on real data sets. By using data sets of increasing dimension, we show that learning indeed leads to sharp phase transitions in the high-dimensional limit. Moreover, we propose and test a mean-field finite-size scaling hypothesis. This shows that the first phase transition is in the same universality class of the one we studied analytically, and which is reminiscent of the mean-field paramagnetic-to-ferromagnetic phase transition.
Predicting large scale cosmological structure evolution with GAN-based autoencoders
Mar 04, 2024



Cosmological simulations play a key role in the prediction and understanding of large scale structure formation from initial conditions. We make use of GAN-based Autoencoders (AEs) in an attempt to predict structure evolution within simulations. The AEs are trained on images and cubes issued from respectively 2D and 3D N-body simulations describing the evolution of the dark matter (DM) field. We find that while the AEs can predict structure evolution for 2D simulations of DM fields well, using only the density fields as input, they perform significantly more poorly in similar conditions for 3D simulations. However, additionally providing velocity fields as inputs greatly improves results, with similar predictions regardless of time-difference between input and target.
Inferring effective couplings with Restricted Boltzmann Machines
Sep 20, 2023



Generative models offer a direct way to model complex data. Among them, energy-based models provide us with a neural network model that aims to accurately reproduce all statistical correlations observed in the data at the level of the Boltzmann weight of the model. However, one challenge is to understand the physical interpretation of such models. In this study, we propose a simple solution by implementing a direct mapping between the energy function of the Restricted Boltzmann Machine and an effective Ising spin Hamiltonian that includes high-order interactions between spins. This mapping includes interactions of all possible orders, going beyond the conventional pairwise interactions typically considered in the inverse Ising approach, and allowing the description of complex datasets. Earlier works attempted to achieve this goal, but the proposed mappings did not do properly treat the complexity of the problem or did not contain direct prescriptions for practical application. To validate our method, we performed several controlled numerical experiments where we trained the RBMs using equilibrium samples of predefined models containing local external fields, two-body and three-body interactions in various low-dimensional topologies. The results demonstrate the effectiveness of our proposed approach in learning the correct interaction network and pave the way for its application in modeling interesting datasets. We also evaluate the quality of the inferred model based on different training methods.
The Copycat Perceptron: Smashing Barriers Through Collective Learning
Aug 07, 2023We characterize the equilibrium properties of a model of $y$ coupled binary perceptrons in the teacher-student scenario, subject to a suitable learning rule, with an explicit ferromagnetic coupling proportional to the Hamming distance between the students' weights. In contrast to recent works, we analyze a more general setting in which a thermal noise is present that affects the generalization performance of each student. Specifically, in the presence of a nonzero temperature, which assigns nonzero probability to configurations that misclassify samples with respect to the teacher's prescription, we find that the coupling of replicas leads to a shift of the phase diagram to smaller values of $\alpha$: This suggests that the free energy landscape gets smoother around the solution with good generalization (i.e., the teacher) at a fixed fraction of reviewed examples, which allows local update algorithms such as Simulated Annealing to reach the solution before the dynamics gets frozen. Finally, from a learning perspective, these results suggest that more students (in this case, with the same amount of data) are able to learn the same rule when coupled together with a smaller amount of data.
Fast and Functional Structured Data Generators Rooted in Out-of-Equilibrium Physics
Jul 13, 2023In this study, we address the challenge of using energy-based models to produce high-quality, label-specific data in complex structured datasets, such as population genetics, RNA or protein sequences data. Traditional training methods encounter difficulties due to inefficient Markov chain Monte Carlo mixing, which affects the diversity of synthetic data and increases generation times. To address these issues, we use a novel training algorithm that exploits non-equilibrium effects. This approach, applied on the Restricted Boltzmann Machine, improves the model's ability to correctly classify samples and generate high-quality synthetic data in only a few sampling steps. The effectiveness of this method is demonstrated by its successful application to four different types of data: handwritten digits, mutations of human genomes classified by continental origin, functionally characterized sequences of an enzyme protein family, and homologous RNA sequences from specific taxonomies.
Unsupervised hierarchical clustering using the learning dynamics of RBMs
Feb 06, 2023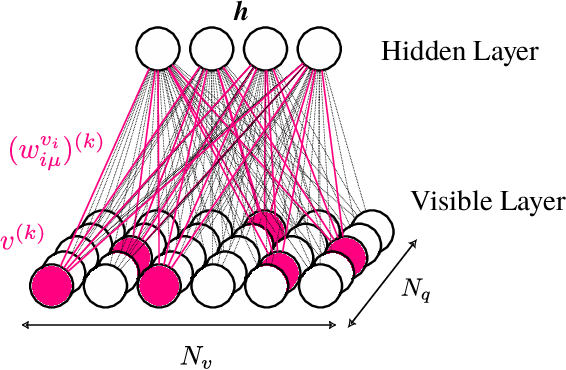
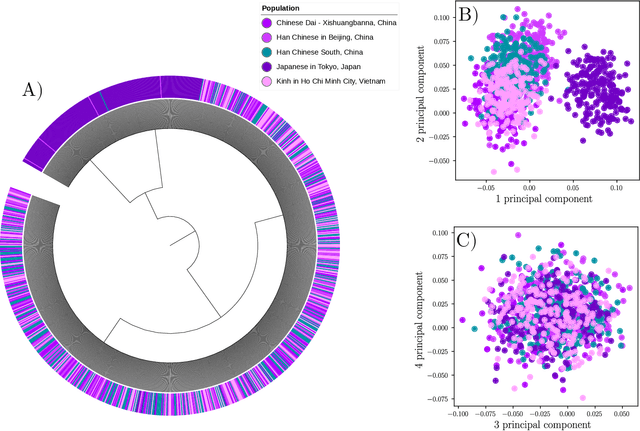
Datasets in the real world are often complex and to some degree hierarchical, with groups and sub-groups of data sharing common characteristics at different levels of abstraction. Understanding and uncovering the hidden structure of these datasets is an important task that has many practical applications. To address this challenge, we present a new and general method for building relational data trees by exploiting the learning dynamics of the Restricted Boltzmann Machine (RBM). Our method is based on the mean-field approach, derived from the Plefka expansion, and developed in the context of disordered systems. It is designed to be easily interpretable. We tested our method in an artificially created hierarchical dataset and on three different real-world datasets (images of digits, mutations in the human genome, and a homologous family of proteins). The method is able to automatically identify the hierarchical structure of the data. This could be useful in the study of homologous protein sequences, where the relationships between proteins are critical for understanding their function and evolution.