 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeLearning and extrapolating scale-invariant processes
Jan 21, 2026Machine Learning (ML) has deeply changed some fields recently, like Language and Vision and we may expect it to be relevant also to the analysis of of complex systems. Here we want to tackle the question of how and to which extent can one regress scale-free processes, i.e. processes displaying power law behavior, like earthquakes or avalanches? We are interested in predicting the large ones, i.e. rare events in the training set which therefore require extrapolation capabilities of the model. For this we consider two paradigmatic problems that are statistically self-similar. The first one is a 2-dimensional fractional Gaussian field obeying linear dynamics, self-similar by construction and amenable to exact analysis. The second one is the Abelian sandpile model, exhibiting self-organized criticality. The emerging paradigm of Geometric Deep Learning shows that including known symmetries into the model's architecture is key to success. Here one may hope to extrapolate only by leveraging scale invariance. This is however a peculiar symmetry, as it involves possibly non-trivial coarse-graining operations and anomalous scaling. We perform experiments on various existing architectures like U-net, Riesz network (scale invariant by construction), or our own proposals: a wavelet-decomposition based Graph Neural Network (with discrete scale symmetry), a Fourier embedding layer and a Fourier-Mellin Neural Operator. Based on these experiments and a complete characterization of the linear case, we identify the main issues relative to spectral biases and coarse-grained representations, and discuss how to alleviate them with the relevant inductive biases.
Building causation links in stochastic nonlinear systems from data
Sep 09, 2025Causal relationships play a fundamental role in understanding the world around us. The ability to identify and understand cause-effect relationships is critical to making informed decisions, predicting outcomes, and developing effective strategies. However, deciphering causal relationships from observational data is a difficult task, as correlations alone may not provide definitive evidence of causality. In recent years, the field of machine learning (ML) has emerged as a powerful tool, offering new opportunities for uncovering hidden causal mechanisms and better understanding complex systems. In this work, we address the issue of detecting the intrinsic causal links of a large class of complex systems in the framework of the response theory in physics. We develop some theoretical ideas put forward by [1], and technically we use state-of-the-art ML techniques to build up models from data. We consider both linear stochastic and non-linear systems. Finally, we compute the asymptotic efficiency of the linear response based causal predictor in a case of large scale Markov process network of linear interactions.
A theoretical framework for overfitting in energy-based modeling
Jan 31, 2025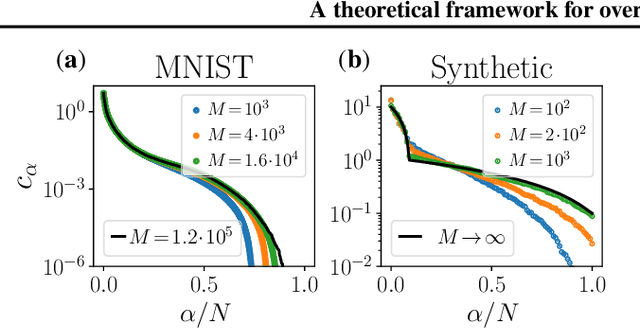



We investigate the impact of limited data on training pairwise energy-based models for inverse problems aimed at identifying interaction networks. Utilizing the Gaussian model as testbed, we dissect training trajectories across the eigenbasis of the coupling matrix, exploiting the independent evolution of eigenmodes and revealing that the learning timescales are tied to the spectral decomposition of the empirical covariance matrix. We see that optimal points for early stopping arise from the interplay between these timescales and the initial conditions of training. Moreover, we show that finite data corrections can be accurately modeled through asymptotic random matrix theory calculations and provide the counterpart of generalized cross-validation in the energy based model context. Our analytical framework extends to binary-variable maximum-entropy pairwise models with minimal variations. These findings offer strategies to control overfitting in discrete-variable models through empirical shrinkage corrections, improving the management of overfitting in energy-based generative models.
ANaGRAM: A Natural Gradient Relative to Adapted Model for efficient PINNs learning
Dec 14, 2024In the recent years, Physics Informed Neural Networks (PINNs) have received strong interest as a method to solve PDE driven systems, in particular for data assimilation purpose. This method is still in its infancy, with many shortcomings and failures that remain not properly understood. In this paper we propose a natural gradient approach to PINNs which contributes to speed-up and improve the accuracy of the training. Based on an in depth analysis of the differential geometric structures of the problem, we come up with two distinct contributions: (i) a new natural gradient algorithm that scales as $\min(P^2S, S^2P)$, where $P$ is the number of parameters, and $S$ the batch size; (ii) a mathematically principled reformulation of the PINNs problem that allows the extension of natural gradient to it, with proved connections to Green's function theory.
Fast, accurate training and sampling of Restricted Boltzmann Machines
May 24, 2024



Thanks to their simple architecture, Restricted Boltzmann Machines (RBMs) are powerful tools for modeling complex systems and extracting interpretable insights from data. However, training RBMs, as other energy-based models, on highly structured data poses a major challenge, as effective training relies on mixing the Markov chain Monte Carlo simulations used to estimate the gradient. This process is often hindered by multiple second-order phase transitions and the associated critical slowdown. In this paper, we present an innovative method in which the principal directions of the dataset are integrated into a low-rank RBM through a convex optimization procedure. This approach enables efficient sampling of the equilibrium measure via a static Monte Carlo process. By starting the standard training process with a model that already accurately represents the main modes of the data, we bypass the initial phase transitions. Our results show that this strategy successfully trains RBMs to capture the full diversity of data in datasets where previous methods fail. Furthermore, we use the training trajectories to propose a new sampling method, {\em parallel trajectory tempering}, which allows us to sample the equilibrium measure of the trained model much faster than previous optimized MCMC approaches and a better estimation of the log-likelihood. We illustrate the success of the training method on several highly structured datasets.
Inferring effective couplings with Restricted Boltzmann Machines
Sep 20, 2023



Generative models offer a direct way to model complex data. Among them, energy-based models provide us with a neural network model that aims to accurately reproduce all statistical correlations observed in the data at the level of the Boltzmann weight of the model. However, one challenge is to understand the physical interpretation of such models. In this study, we propose a simple solution by implementing a direct mapping between the energy function of the Restricted Boltzmann Machine and an effective Ising spin Hamiltonian that includes high-order interactions between spins. This mapping includes interactions of all possible orders, going beyond the conventional pairwise interactions typically considered in the inverse Ising approach, and allowing the description of complex datasets. Earlier works attempted to achieve this goal, but the proposed mappings did not do properly treat the complexity of the problem or did not contain direct prescriptions for practical application. To validate our method, we performed several controlled numerical experiments where we trained the RBMs using equilibrium samples of predefined models containing local external fields, two-body and three-body interactions in various low-dimensional topologies. The results demonstrate the effectiveness of our proposed approach in learning the correct interaction network and pave the way for its application in modeling interesting datasets. We also evaluate the quality of the inferred model based on different training methods.
Learning a Restricted Boltzmann Machine using biased Monte Carlo sampling
Jun 02, 2022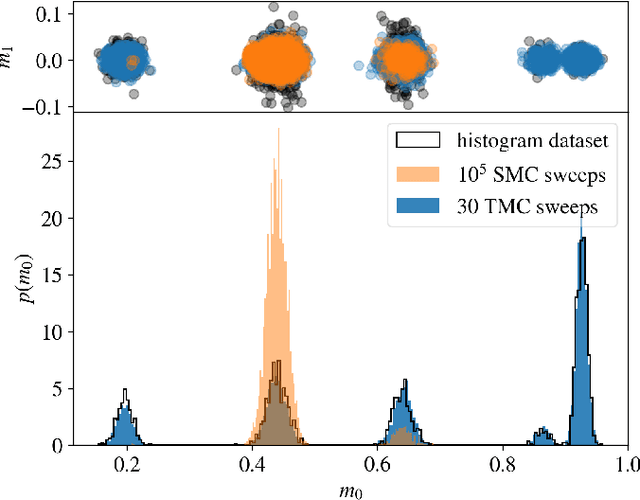

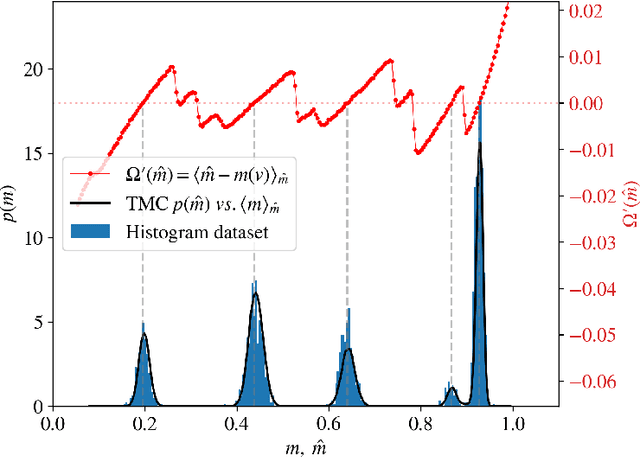

Restricted Boltzmann Machines are simple and powerful generative models capable of encoding any complex dataset. Despite all their advantages, in practice, trainings are often unstable, and it is hard to assess their quality because dynamics are hampered by extremely slow time-dependencies. This situation becomes critical when dealing with low-dimensional clustered datasets, where the time needed to sample ergodically the trained models becomes computationally prohibitive. In this work, we show that this divergence of Monte Carlo mixing times is related to a phase coexistence phenomenon, similar to that encountered in Physics in the vicinity of a first order phase transition. We show that sampling the equilibrium distribution via Markov Chain Monte Carlo can be dramatically accelerated using biased sampling techniques, in particular, the Tethered Monte Carlo method (TMC). This sampling technique solves efficiently the problem of evaluating the quality of a given trained model and the generation of new samples in reasonable times. In addition, we show that this sampling technique can be exploited to improve the computation of the log-likelihood gradient during the training too, which produces dramatic improvements when training RBMs with artificial clustered datasets. When dealing with real low-dimensional datasets, this new training procedure fits RBM models with significantly faster relaxational dynamics than those obtained with standard PCD recipes. We also show that TMC sampling can be used to recover free-energy profile of the RBM, which turns out to be extremely useful to compute the probability distribution of a given model and to improve the generation of new decorrelated samples on slow PCD trained models.
Equilibrium and non-Equilibrium regimes in the learning of Restricted Boltzmann Machines
Jun 04, 2021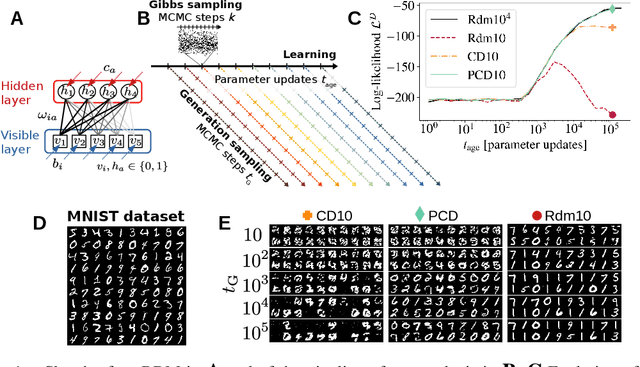
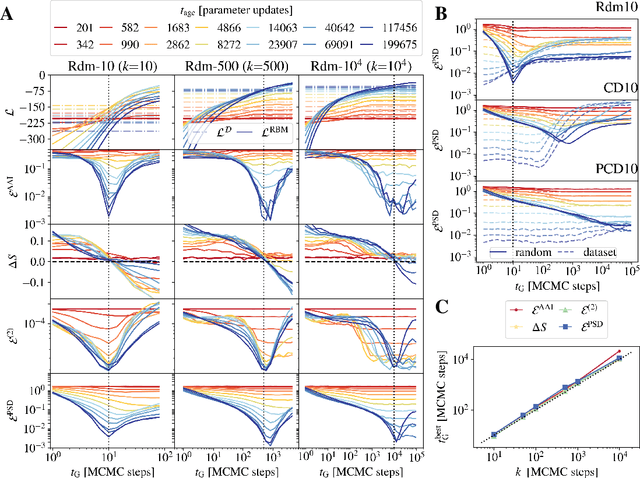
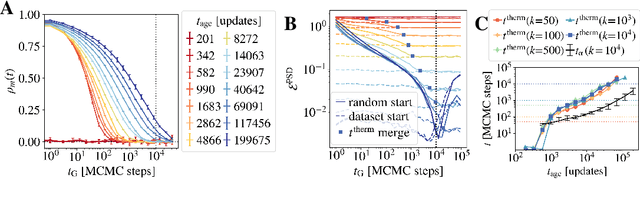
Training Restricted Boltzmann Machines (RBMs) has been challenging for a long time due to the difficulty of computing precisely the log-likelihood gradient. Over the past decades, many works have proposed more or less successful training recipes but without studying the crucial quantity of the problem: the mixing time i.e. the number of Monte Carlo iterations needed to sample new configurations from a model. In this work, we show that this mixing time plays a crucial role in the dynamics and stability of the trained model, and that RBMs operate in two well-defined regimes, namely equilibrium and out-of-equilibrium, depending on the interplay between this mixing time of the model and the number of steps, $k$, used to approximate the gradient. We further show empirically that this mixing time increases with the learning, which often implies a transition from one regime to another as soon as $k$ becomes smaller than this time. In particular, we show that using the popular $k$ (persistent) contrastive divergence approaches, with $k$ small, the dynamics of the learned model are extremely slow and often dominated by strong out-of-equilibrium effects. On the contrary, RBMs trained in equilibrium display faster dynamics, and a smooth convergence to dataset-like configurations during the sampling. Finally we discuss how to exploit in practice both regimes depending on the task one aims to fulfill: (i) short $k$s can be used to generate convincing samples in short times, (ii) large $k$ (or increasingly large) must be used to learn the correct equilibrium distribution of the RBM.
Restricted Boltzmann Machine, recent advances and mean-field theory
Nov 23, 2020
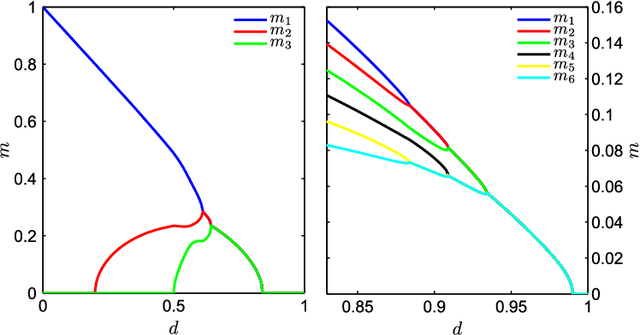
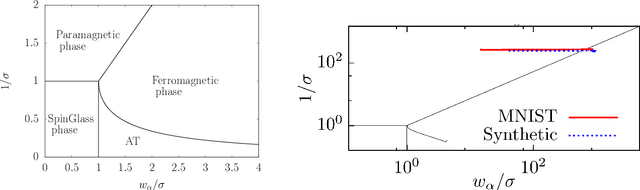
This review deals with Restricted Boltzmann Machine (RBM) under the light of statistical physics. The RBM is a classical family of Machine learning (ML) models which played a central role in the development of deep learning. Viewing it as a Spin Glass model and exhibiting various links with other models of statistical physics, we gather recent results dealing with mean-field theory in this context. First the functioning of the RBM can be analyzed via the phase diagrams obtained for various statistical ensembles of RBM leading in particular to identify a {\it compositional phase} where a small number of features or modes are combined to form complex patterns. Then we discuss recent works either able to devise mean-field based learning algorithms; either able to reproduce generic aspects of the learning process from some {\it ensemble dynamics equations} or/and from linear stability arguments.
Robust Multi-Output Learning with Highly Incomplete Data via Restricted Boltzmann Machines
Dec 19, 2019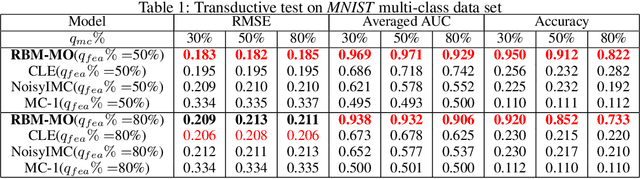

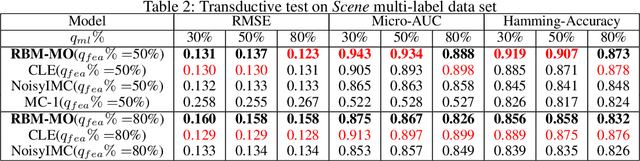
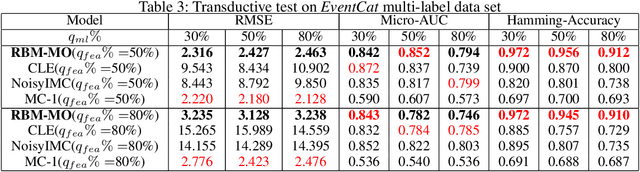
In a standard multi-output classification scenario, both features and labels of training data are partially observed. This challenging issue is widely witnessed due to sensor or database failures, crowd-sourcing and noisy communication channels in industrial data analytic services. Classic methods for handling multi-output classification with incomplete supervision information usually decompose the problem into an imputation stage that reconstructs the missing training information, and a learning stage that builds a classifier based on the imputed training set. These methods fail to fully leverage the dependencies between features and labels. In order to take full advantage of these dependencies we consider a purely probabilistic setting in which the features imputation and multi-label classification problems are jointly solved. Indeed, we show that a simple Restricted Boltzmann Machine can be trained with an adapted algorithm based on mean-field equations to efficiently solve problems of inductive and transductive learning in which both features and labels are missing at random. The effectiveness of the approach is demonstrated empirically on various datasets, with particular focus on a real-world Internet-of-Things security dataset.