 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeHebbian Learning from First Principles
Jan 13, 2024Recently, the original storage prescription for the Hopfield model of neural networks -- as well as for its dense generalizations -- has been turned into a genuine Hebbian learning rule by postulating the expression of its Hamiltonian for both the supervised and unsupervised protocols. In these notes, first, we obtain these explicit expressions by relying upon maximum entropy extremization \`a la Jaynes. Beyond providing a formal derivation of these recipes for Hebbian learning, this construction also highlights how Lagrangian constraints within entropy extremization force network's outcomes on neural correlations: these try to mimic the empirical counterparts hidden in the datasets provided to the network for its training and, the denser the network, the longer the correlations that it is able to capture. Next, we prove that, in the big data limit, whatever the presence of a teacher (or its lacking), not only these Hebbian learning rules converge to the original storage prescription of the Hopfield model but also their related free energies (and, thus, the statistical mechanical picture provided by Amit, Gutfreund and Sompolinsky is fully recovered). As a sideline, we show mathematical equivalence among standard Cost functions (Hamiltonian), preferred in Statistical Mechanical jargon, and quadratic Loss Functions, preferred in Machine Learning terminology. Remarks on the exponential Hopfield model (as the limit of dense networks with diverging density) and semi-supervised protocols are also provided.
Unsupervised and Supervised learning by Dense Associative Memory under replica symmetry breaking
Dec 15, 2023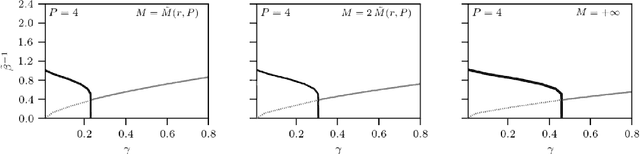

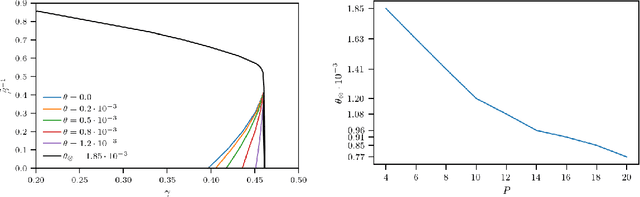

Statistical mechanics of spin glasses is one of the main strands toward a comprehension of information processing by neural networks and learning machines. Tackling this approach, at the fairly standard replica symmetric level of description, recently Hebbian attractor networks with multi-node interactions (often called Dense Associative Memories) have been shown to outperform their classical pairwise counterparts in a number of tasks, from their robustness against adversarial attacks and their capability to work with prohibitively weak signals to their supra-linear storage capacities. Focusing on mathematical techniques more than computational aspects, in this paper we relax the replica symmetric assumption and we derive the one-step broken-replica-symmetry picture of supervised and unsupervised learning protocols for these Dense Associative Memories: a phase diagram in the space of the control parameters is achieved, independently, both via the Parisi's hierarchy within then replica trick as well as via the Guerra's telescope within the broken-replica interpolation. Further, an explicit analytical investigation is provided to deepen both the big-data and ground state limits of these networks as well as a proof that replica symmetry breaking does not alter the thresholds for learning and slightly increases the maximal storage capacity. Finally the De Almeida and Thouless line, depicting the onset of instability of a replica symmetric description, is also analytically derived highlighting how, crossed this boundary, the broken replica description should be preferred.
Dense Hebbian neural networks: a replica symmetric picture of unsupervised learning
Nov 25, 2022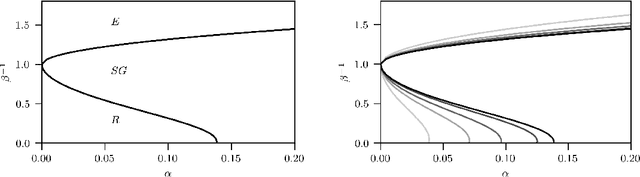
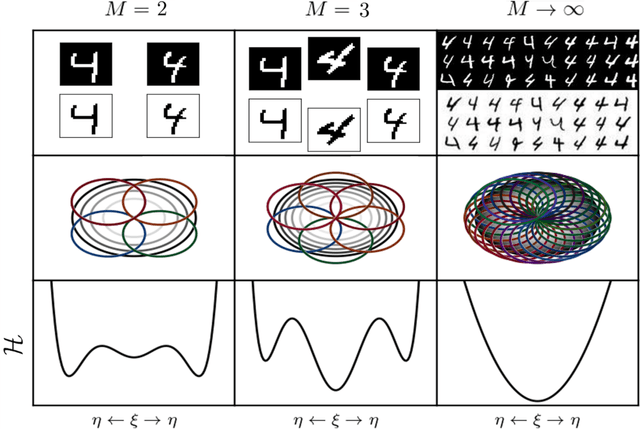
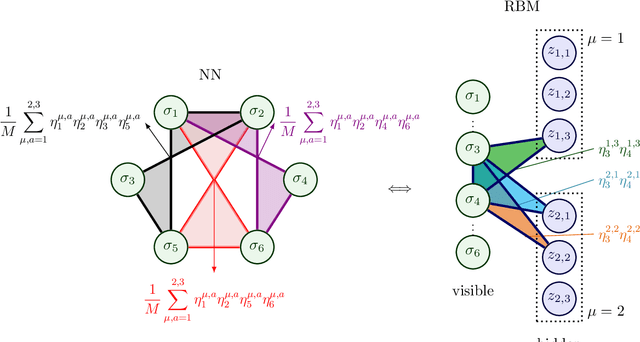
We consider dense, associative neural-networks trained with no supervision and we investigate their computational capabilities analytically, via a statistical-mechanics approach, and numerically, via Monte Carlo simulations. In particular, we obtain a phase diagram summarizing their performance as a function of the control parameters such as the quality and quantity of the training dataset and the network storage, valid in the limit of large network size and structureless datasets. Moreover, we establish a bridge between macroscopic observables standardly used in statistical mechanics and loss functions typically used in the machine learning. As technical remarks, from the analytic side, we implement large deviations and stability analysis within Guerra's interpolation to tackle the not-Gaussian distributions involved in the post-synaptic potentials while, from the computational counterpart, we insert Plefka approximation in the Monte Carlo scheme, to speed up the evaluation of the synaptic tensors, overall obtaining a novel and broad approach to investigate neural networks in general.
Dense Hebbian neural networks: a replica symmetric picture of supervised learning
Nov 25, 2022



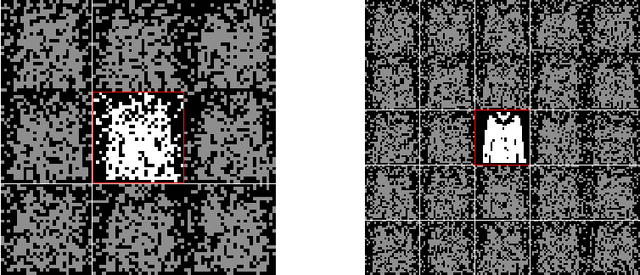
We consider dense, associative neural-networks trained by a teacher (i.e., with supervision) and we investigate their computational capabilities analytically, via statistical-mechanics of spin glasses, and numerically, via Monte Carlo simulations. In particular, we obtain a phase diagram summarizing their performance as a function of the control parameters such as quality and quantity of the training dataset, network storage and noise, that is valid in the limit of large network size and structureless datasets: these networks may work in a ultra-storage regime (where they can handle a huge amount of patterns, if compared with shallow neural networks) or in a ultra-detection regime (where they can perform pattern recognition at prohibitive signal-to-noise ratios, if compared with shallow neural networks). Guided by the random theory as a reference framework, we also test numerically learning, storing and retrieval capabilities shown by these networks on structured datasets as MNist and Fashion MNist. As technical remarks, from the analytic side, we implement large deviations and stability analysis within Guerra's interpolation to tackle the not-Gaussian distributions involved in the post-synaptic potentials while, from the computational counterpart, we insert Plefka approximation in the Monte Carlo scheme, to speed up the evaluation of the synaptic tensors, overall obtaining a novel and broad approach to investigate supervised learning in neural networks, beyond the shallow limit, in general.