 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeFundamental operating regimes, hyper-parameter fine-tuning and glassiness: towards an interpretable replica-theory for trained restricted Boltzmann machines
Jun 14, 2024We consider restricted Boltzmann machines with a binary visible layer and a Gaussian hidden layer trained by an unlabelled dataset composed of noisy realizations of a single ground pattern. We develop a statistical mechanics framework to describe the network generative capabilities, by exploiting the replica trick and assuming self-averaging of the underlying order parameters (i.e., replica symmetry). In particular, we outline the effective control parameters (e.g., the relative number of weights to be trained, the regularization parameter), whose tuning can yield qualitatively-different operative regimes. Further, we provide analytical and numerical evidence for the existence of a sub-region in the space of the hyperparameters where replica-symmetry breaking occurs.
Regularization, early-stopping and dreaming: a Hopfield-like setup to address generalization and overfitting
Aug 01, 2023In this work we approach attractor neural networks from a machine learning perspective: we look for optimal network parameters by applying a gradient descent over a regularized loss function. Within this framework, the optimal neuron-interaction matrices turn out to be a class of matrices which correspond to Hebbian kernels revised by iteratively applying some unlearning protocols. Remarkably, the number of unlearning steps is proved to be related to the regularization hyperparameters of the loss function and to the training time. Thus, we can design strategies to avoid overfitting that are formulated in terms of the algebraic properties of the interaction matrix, or, equivalently, in terms of regularization tuning and early-stopping strategies. The generalization capabilities of these attractor networks are also investigated: analytical results are obtained for random synthetic datasets, next, the emerging picture is corroborated by numerical experiments that highlight the existence of several regimes (i.e., overfitting, failure and success) as the dataset parameters are varied.
Pavlov Learning Machines
Jul 02, 2022

As well known, Hebb's learning traces its origin in Pavlov's Classical Conditioning, however, while the former has been extensively modelled in the past decades (e.g., by Hopfield model and countless variations on theme), as for the latter modelling has remained largely unaddressed so far; further, a bridge between these two pillars is totally lacking. The main difficulty towards this goal lays in the intrinsically different scales of the information involved: Pavlov's theory is about correlations among \emph{concepts} that are (dynamically) stored in the synaptic matrix as exemplified by the celebrated experiment starring a dog and a ring bell; conversely, Hebb's theory is about correlations among pairs of adjacent neurons as summarized by the famous statement {\em neurons that fire together wire together}. In this paper we rely on stochastic-process theory and model neural and synaptic dynamics via Langevin equations, to prove that -- as long as we keep neurons' and synapses' timescales largely split -- Pavlov mechanism spontaneously takes place and ultimately gives rise to synaptic weights that recover the Hebbian kernel.
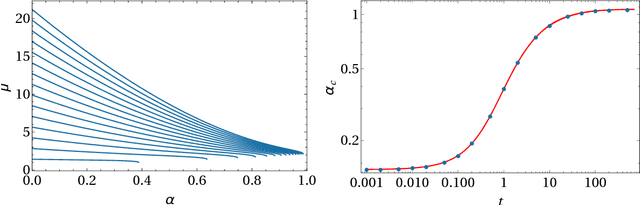
Interpolating between boolean and extremely high noisy patterns through Minimal Dense Associative Memories
Dec 02, 2019
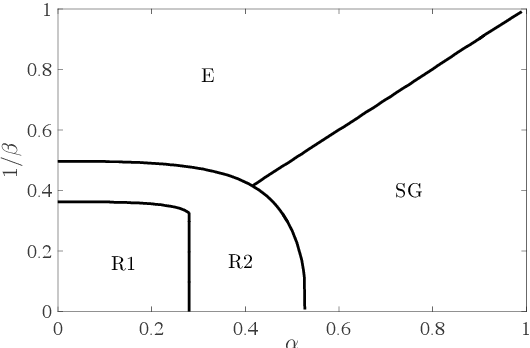
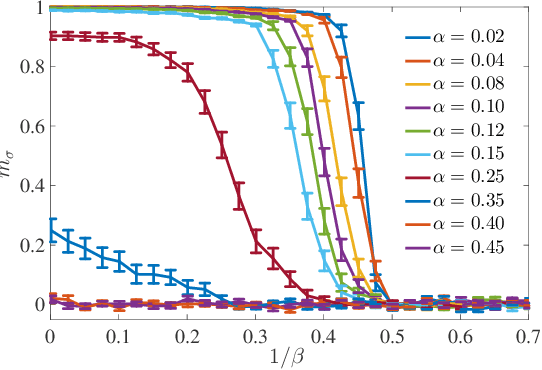
Recently, Hopfield and Krotov introduced the concept of {\em dense associative memories} [DAM] (close to spin-glasses with $P$-wise interactions in a disordered statistical mechanical jargon): they proved a number of remarkable features these networks share and suggested their use to (partially) explain the success of the new generation of Artificial Intelligence. Thanks to a remarkable ante-litteram analysis by Baldi \& Venkatesh, among these properties, it is known these networks can handle a maximal amount of stored patterns $K$ scaling as $K \sim N^{P-1}$.\\ In this paper, once introduced a {\em minimal dense associative network} as one of the most elementary cost-functions falling in this class of DAM, we sacrifice this high-load regime -namely we force the storage of {\em solely} a linear amount of patterns, i.e. $K = \alpha N$ (with $\alpha>0$)- to prove that, in this regime, these networks can correctly perform pattern recognition even if pattern signal is $O(1)$ and is embedded in a sea of noise $O(\sqrt{N})$, also in the large $N$ limit. To prove this statement, by extremizing the quenched free-energy of the model over its natural order-parameters (the various magnetizations and overlaps), we derived its phase diagram, at the replica symmetric level of description and in the thermodynamic limit: as a sideline, we stress that, to achieve this task, aiming at cross-fertilization among disciplines, we pave two hegemon routes in the statistical mechanics of spin glasses, namely the replica trick and the interpolation technique.\\ Both the approaches reach the same conclusion: there is a not-empty region, in the noise-$T$ vs load-$\alpha$ phase diagram plane, where these networks can actually work in this challenging regime; in particular we obtained a quite high critical (linear) load in the (fast) noiseless case resulting in $\lim_{\beta \to \infty}\alpha_c(\beta)=0.65$.
Neural networks with redundant representation: detecting the undetectable
Nov 28, 2019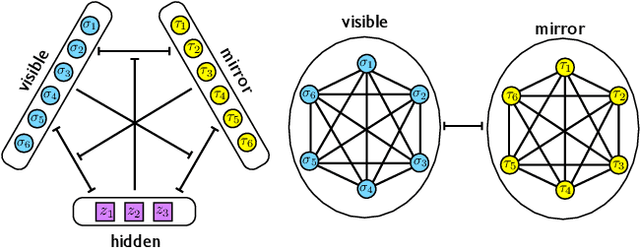

We consider a three-layer Sejnowski machine and show that features learnt via contrastive divergence have a dual representation as patterns in a dense associative memory of order P=4. The latter is known to be able to Hebbian-store an amount of patterns scaling as N^{P-1}, where N denotes the number of constituting binary neurons interacting P-wisely. We also prove that, by keeping the dense associative network far from the saturation regime (namely, allowing for a number of patterns scaling only linearly with N, while P>2) such a system is able to perform pattern recognition far below the standard signal-to-noise threshold. In particular, a network with P=4 is able to retrieve information whose intensity is O(1) even in the presence of a noise O(\sqrt{N}) in the large N limit. This striking skill stems from a redundancy representation of patterns -- which is afforded given the (relatively) low-load information storage -- and it contributes to explain the impressive abilities in pattern recognition exhibited by new-generation neural networks. The whole theory is developed rigorously, at the replica symmetric level of approximation, and corroborated by signal-to-noise analysis and Monte Carlo simulations.
Dreaming neural networks: rigorous results
Dec 21, 2018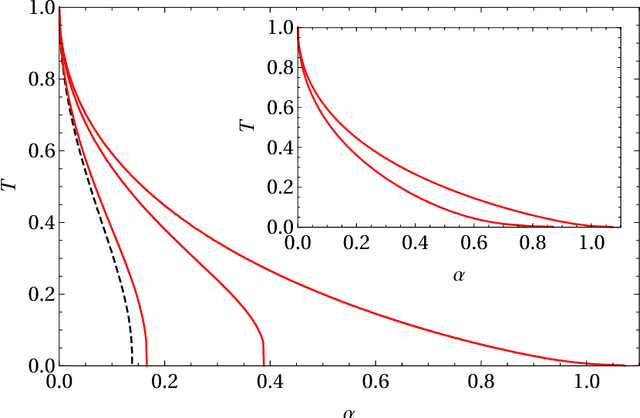


Recently a daily routine for associative neural networks has been proposed: the network Hebbian-learns during the awake state (thus behaving as a standard Hopfield model), then, during its sleep state, optimizing information storage, it consolidates pure patterns and removes spurious ones: this forces the synaptic matrix to collapse to the projector one (ultimately approaching the Kanter-Sompolinksy model). This procedure keeps the learning Hebbian-based (a biological must) but, by taking advantage of a (properly stylized) sleep phase, still reaches the maximal critical capacity (for symmetric interactions). So far this emerging picture (as well as the bulk of papers on unlearning techniques) was supported solely by mathematically-challenging routes, e.g. mainly replica-trick analysis and numerical simulations: here we rely extensively on Guerra's interpolation techniques developed for neural networks and, in particular, we extend the generalized stochastic stability approach to the case. Confining our description within the replica symmetric approximation (where the previous ones lie), the picture painted regarding this generalization (and the previously existing variations on theme) is here entirely confirmed. Further, still relying on Guerra's schemes, we develop a systematic fluctuation analysis to check where ergodicity is broken (an analysis entirely absent in previous investigations). We find that, as long as the network is awake, ergodicity is bounded by the Amit-Gutfreund-Sompolinsky critical line (as it should), but, as the network sleeps, sleeping destroys spin glass states by extending both the retrieval as well as the ergodic region: after an entire sleeping session the solely surviving regions are retrieval and ergodic ones and this allows the network to achieve the perfect retrieval regime (the number of storable patterns equals the number of neurons in the network).
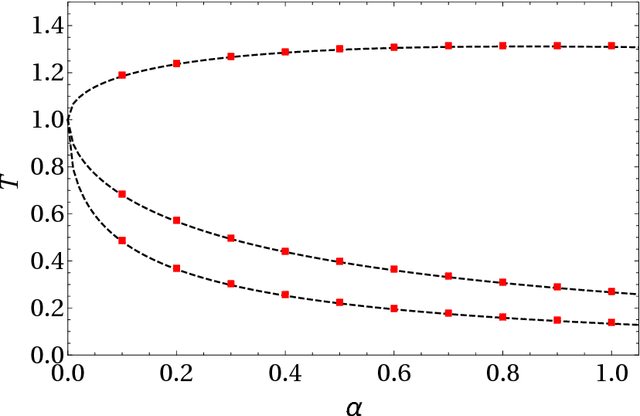
Dreaming neural networks: forgetting spurious memories and reinforcing pure ones
Oct 29, 2018


The standard Hopfield model for associative neural networks accounts for biological Hebbian learning and acts as the harmonic oscillator for pattern recognition, however its maximal storage capacity is $\alpha \sim 0.14$, far from the theoretical bound for symmetric networks, i.e. $\alpha =1$. Inspired by sleeping and dreaming mechanisms in mammal brains, we propose an extension of this model displaying the standard on-line (awake) learning mechanism (that allows the storage of external information in terms of patterns) and an off-line (sleep) unlearning$\&$consolidating mechanism (that allows spurious-pattern removal and pure-pattern reinforcement): this obtained daily prescription is able to saturate the theoretical bound $\alpha=1$, remaining also extremely robust against thermal noise. Both neural and synaptic features are analyzed both analytically and numerically. In particular, beyond obtaining a phase diagram for neural dynamics, we focus on synaptic plasticity and we give explicit prescriptions on the temporal evolution of the synaptic matrix. We analytically prove that our algorithm makes the Hebbian kernel converge with high probability to the projection matrix built over the pure stored patterns. Furthermore, we obtain a sharp and explicit estimate for the "sleep rate" in order to ensure such a convergence. Finally, we run extensive numerical simulations (mainly Monte Carlo sampling) to check the approximations underlying the analytical investigations (e.g., we developed the whole theory at the so called replica-symmetric level, as standard in the Amit-Gutfreund-Sompolinsky reference framework) and possible finite-size effects, finding overall full agreement with the theory.
A relativistic extension of Hopfield neural networks via the mechanical analogy
Jan 05, 2018
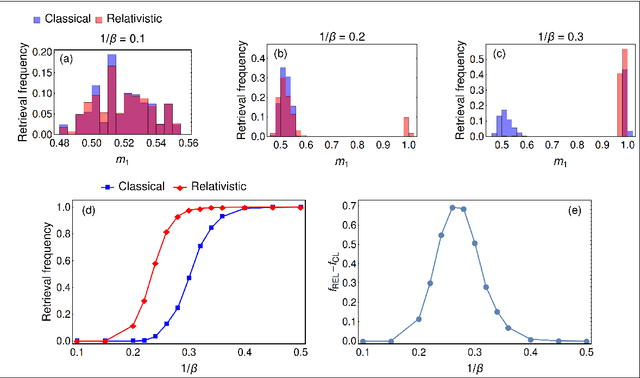
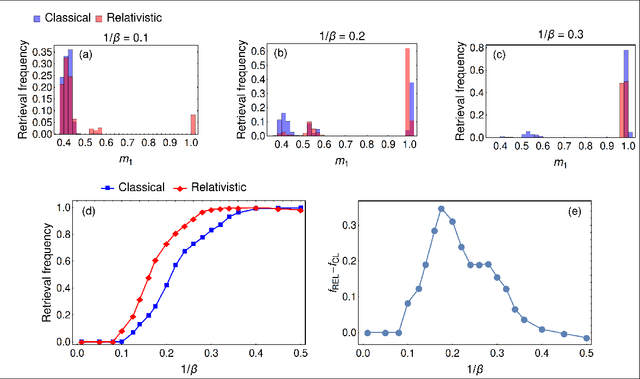
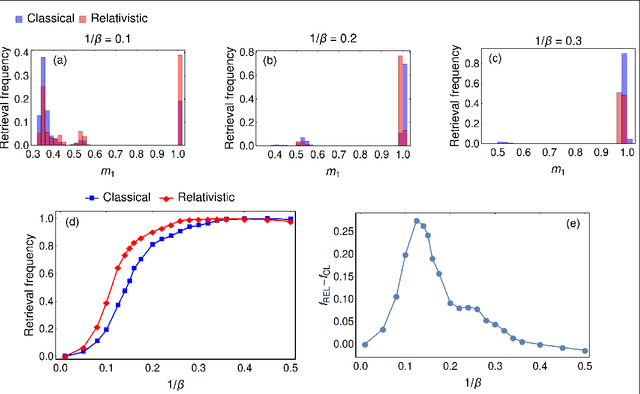
We propose a modification of the cost function of the Hopfield model whose salient features shine in its Taylor expansion and result in more than pairwise interactions with alternate signs, suggesting a unified framework for handling both with deep learning and network pruning. In our analysis, we heavily rely on the Hamilton-Jacobi correspondence relating the statistical model with a mechanical system. In this picture, our model is nothing but the relativistic extension of the original Hopfield model (whose cost function is a quadratic form in the Mattis magnetization which mimics the non-relativistic Hamiltonian for a free particle). We focus on the low-storage regime and solve the model analytically by taking advantage of the mechanical analogy, thus obtaining a complete characterization of the free energy and the associated self-consistency equations in the thermodynamic limit. On the numerical side, we test the performances of our proposal with MC simulations, showing that the stability of spurious states (limiting the capabilities of the standard Hebbian construction) is sensibly reduced due to presence of unlearning contributions in this extended framework.