Get our free extension to see links to code for papers anywhere online!Free add-on: code for papers everywhere!Free add-on: See code for papers anywhere!
 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeSoundLoCD: An Efficient Conditional Discrete Contrastive Latent Diffusion Model for Text-to-Sound Generation
Paper and Code

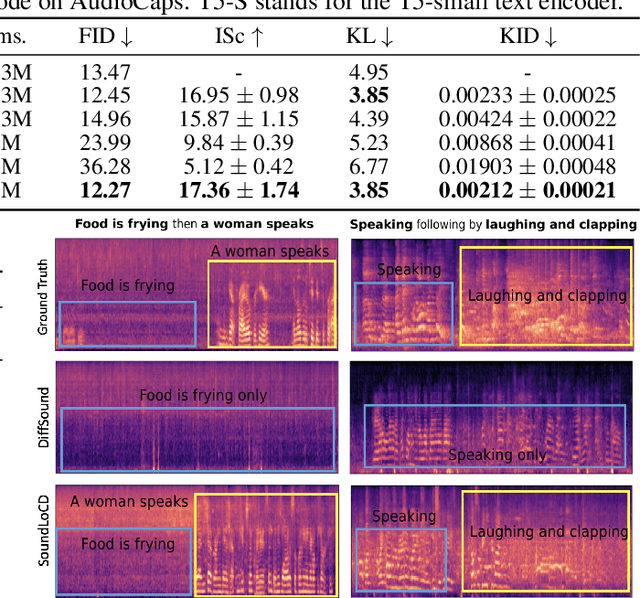

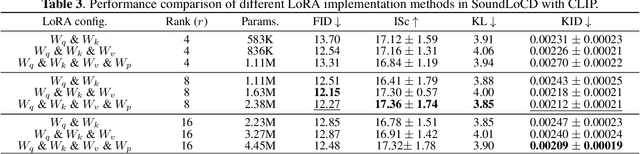
We present SoundLoCD, a novel text-to-sound generation framework, which incorporates a LoRA-based conditional discrete contrastive latent diffusion model. Unlike recent large-scale sound generation models, our model can be efficiently trained under limited computational resources. The integration of a contrastive learning strategy further enhances the connection between text conditions and the generated outputs, resulting in coherent and high-fidelity performance. Our experiments demonstrate that SoundLoCD outperforms the baseline with greatly reduced computational resources. A comprehensive ablation study further validates the contribution of each component within SoundLoCD. Demo page: \url{https://XinleiNIU.github.io/demo-SoundLoCD/}.
View paper on