 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeCan pre-trained Transformers be used in detecting complex sensitive sentences? -- A Monsanto case study
Paper and Code
Mar 14, 2022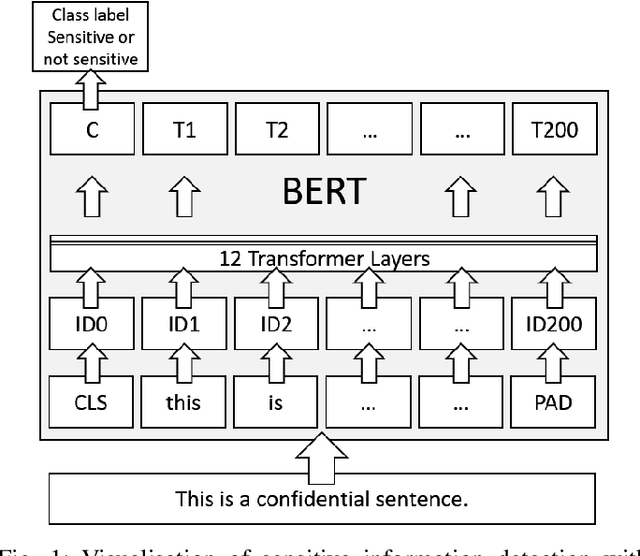
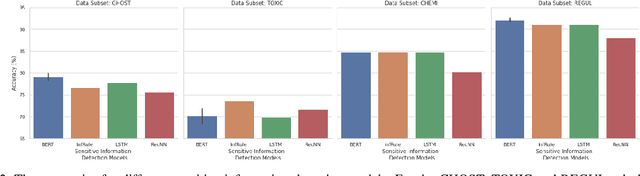
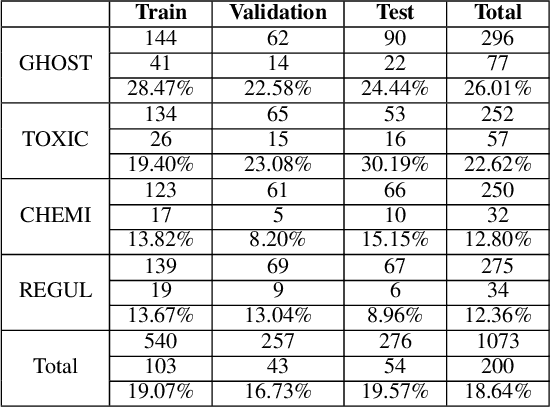
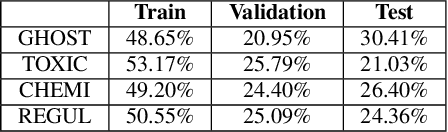
Each and every organisation releases information in a variety of forms ranging from annual reports to legal proceedings. Such documents may contain sensitive information and releasing them openly may lead to the leakage of confidential information. Detection of sentences that contain sensitive information in documents can help organisations prevent the leakage of valuable confidential information. This is especially challenging when such sentences contain a substantial amount of information or are paraphrased versions of known sensitive content. Current approaches to sensitive information detection in such complex settings are based on keyword-based approaches or standard machine learning models. In this paper, we wish to explore whether pre-trained transformer models are well suited to detect complex sensitive information. Pre-trained transformers are typically trained on an enormous amount of text and therefore readily learn grammar, structure and other linguistic features, making them particularly attractive for this task. Through our experiments on the Monsanto trial data set, we observe that the fine-tuned Bidirectional Encoder Representations from Transformers (BERT) transformer model performs better than traditional models. We experimented with four different categories of documents in the Monsanto dataset and observed that BERT achieves better F2 scores by 24.13\% to 65.79\% for GHOST, 30.14\% to 54.88\% for TOXIC, 39.22\% for CHEMI, 53.57\% for REGUL compared to existing sensitive information detection models.