 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeMetaLead: A Comprehensive Human-Curated Leaderboard Dataset for Transparent Reporting of Machine Learning Experiments
Jan 30, 2026Leaderboards are crucial in the machine learning (ML) domain for benchmarking and tracking progress. However, creating leaderboards traditionally demands significant manual effort. In recent years, efforts have been made to automate leaderboard generation, but existing datasets for this purpose are limited by capturing only the best results from each paper and limited metadata. We present MetaLead, a fully human-annotated ML Leaderboard dataset that captures all experimental results for result transparency and contains extra metadata, such as the result experimental type: baseline, proposed method, or variation of proposed method for experiment-type guided comparisons, and explicitly separates train and test dataset for cross-domain assessment. This enriched structure makes MetaLead a powerful resource for more transparent and nuanced evaluations across ML research.
Honeyfile Camouflage: Hiding Fake Files in Plain Sight
May 08, 2024Honeyfiles are a particularly useful type of honeypot: fake files deployed to detect and infer information from malicious behaviour. This paper considers the challenge of naming honeyfiles so they are camouflaged when placed amongst real files in a file system. Based on cosine distances in semantic vector spaces, we develop two metrics for filename camouflage: one based on simple averaging and one on clustering with mixture fitting. We evaluate and compare the metrics, showing that both perform well on a publicly available GitHub software repository dataset.
NASA Science Mission Directorate Knowledge Graph Discovery
Mar 20, 2023The size of the National Aeronautics and Space Administration (NASA) Science Mission Directorate (SMD) is growing exponentially, allowing researchers to make discoveries. However, making discoveries is challenging and time-consuming due to the size of the data catalogs, and as many concepts and data are indirectly connected. This paper proposes a pipeline to generate knowledge graphs (KGs) representing different NASA SMD domains. These KGs can be used as the basis for dataset search engines, saving researchers time and supporting them in finding new connections. We collected textual data and used several modern natural language processing (NLP) methods to create the nodes and the edges of the KGs. We explore the cross-domain connections, discuss our challenges, and provide future directions to inspire researchers working on similar challenges.
Deception for Cyber Defence: Challenges and Opportunities
Aug 15, 2022
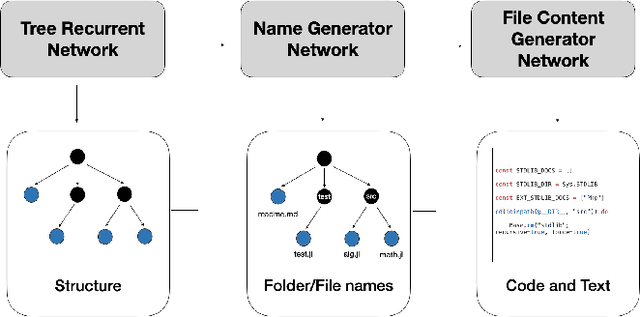
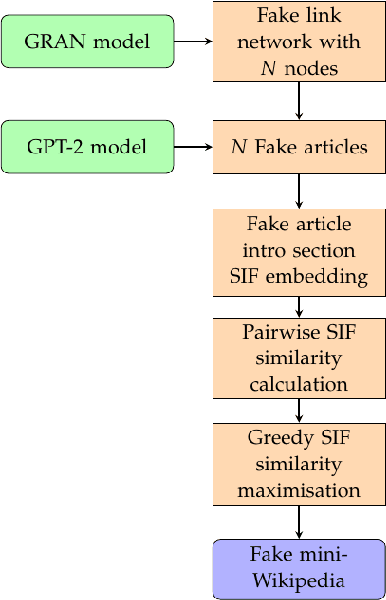
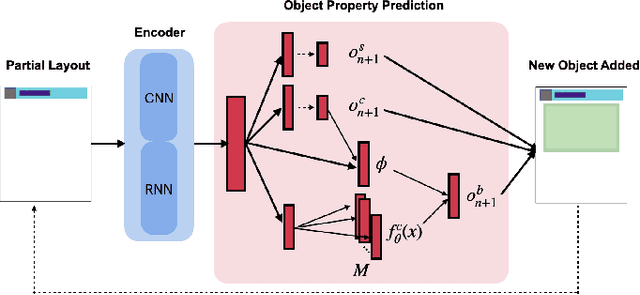
Deception is rapidly growing as an important tool for cyber defence, complementing existing perimeter security measures to rapidly detect breaches and data theft. One of the factors limiting the use of deception has been the cost of generating realistic artefacts by hand. Recent advances in Machine Learning have, however, created opportunities for scalable, automated generation of realistic deceptions. This vision paper describes the opportunities and challenges involved in developing models to mimic many common elements of the IT stack for deception effects.
TSM: Measuring the Enticement of Honeyfiles with Natural Language Processing
Mar 15, 2022

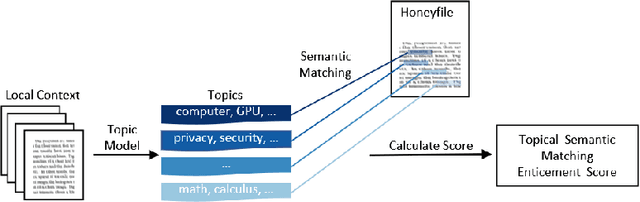

Honeyfile deployment is a useful breach detection method in cyber deception that can also inform defenders about the intent and interests of intruders and malicious insiders. A key property of a honeyfile, enticement, is the extent to which the file can attract an intruder to interact with it. We introduce a novel metric, Topic Semantic Matching (TSM), which uses topic modelling to represent files in the repository and semantic matching in an embedding vector space to compare honeyfile text and topic words robustly. We also present a honeyfile corpus created with different Natural Language Processing (NLP) methods. Experiments show that TSM is effective in inter-corpus comparisons and is a promising tool to measure the enticement of honeyfiles. TSM is the first measure to use NLP techniques to quantify the enticement of honeyfile content that compares the essential topical content of local contexts to honeyfiles and is robust to paraphrasing.
Can pre-trained Transformers be used in detecting complex sensitive sentences? -- A Monsanto case study
Mar 14, 2022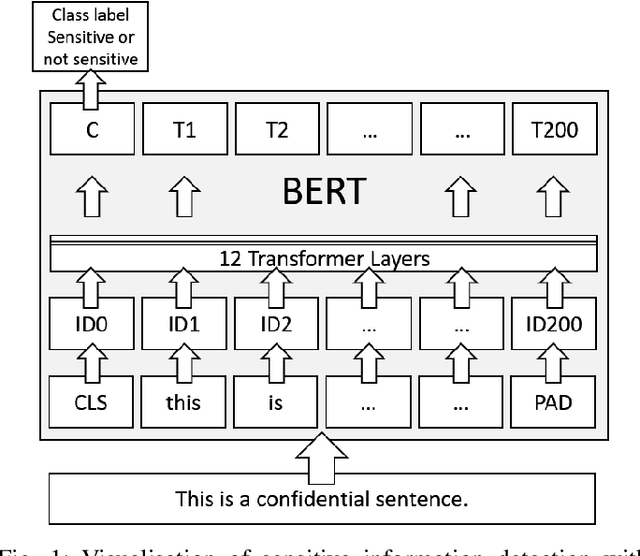
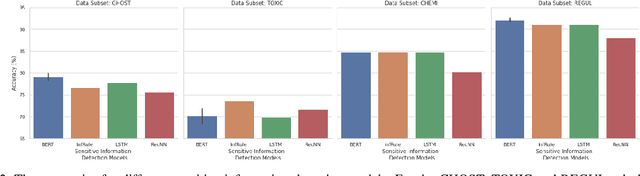
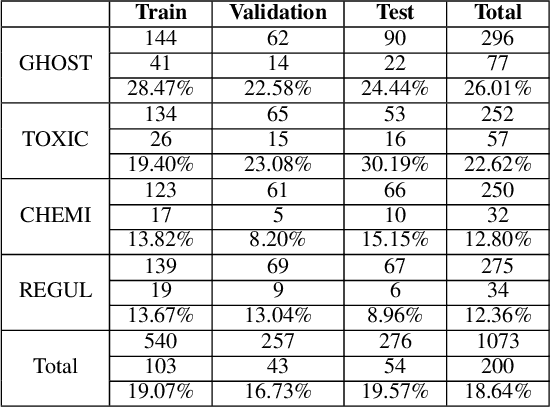
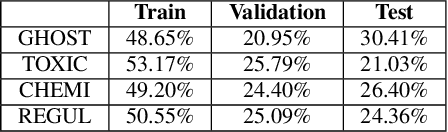
Each and every organisation releases information in a variety of forms ranging from annual reports to legal proceedings. Such documents may contain sensitive information and releasing them openly may lead to the leakage of confidential information. Detection of sentences that contain sensitive information in documents can help organisations prevent the leakage of valuable confidential information. This is especially challenging when such sentences contain a substantial amount of information or are paraphrased versions of known sensitive content. Current approaches to sensitive information detection in such complex settings are based on keyword-based approaches or standard machine learning models. In this paper, we wish to explore whether pre-trained transformer models are well suited to detect complex sensitive information. Pre-trained transformers are typically trained on an enormous amount of text and therefore readily learn grammar, structure and other linguistic features, making them particularly attractive for this task. Through our experiments on the Monsanto trial data set, we observe that the fine-tuned Bidirectional Encoder Representations from Transformers (BERT) transformer model performs better than traditional models. We experimented with four different categories of documents in the Monsanto dataset and observed that BERT achieves better F2 scores by 24.13\% to 65.79\% for GHOST, 30.14\% to 54.88\% for TOXIC, 39.22\% for CHEMI, 53.57\% for REGUL compared to existing sensitive information detection models.